

香草RNN和储层计算的原始汤
利用过去的经验来提高未来性能是深度学习和机器学习的基石。机器学习的一个定义明确阐述了通过经验改进的重要性:
据说计算机程序可以学习经验E,学习与某些类任务T和性能度量P有关,如果其在T任务中的表现(按P测量)随着经验E的提高而提高。
-汤姆·米切尔机器学习
在神经网络中,经验的性能改进被编码为模型参数(权重)中的非常长期内存。从一组带批过的示例学习后,神经网络更有可能做出正确的决策,当显示其他类似但以前看不到的示例时。这是监督深度学习数据的本质,具有一对一的明确匹配,例如,一组图像映射到每个图像(猫、狗、热狗等)的一个类。
您可能还喜欢:
使用循环神经网络 (LSTM) 的时间序列预测
在很多情况下,数据自然形成序列,在这些情况下,顺序和内容同样重要。序列数据的其他示例包括视频、音乐、DNA 序列和许多其他示例。从序列数据中学习时,短期内存对于使用有序上下文处理一系列相关数据非常有用。为此,机器学习研究人员早已转向循环神经网络(RNN)。
 鹦鹉螺与决策树插图
鹦鹉螺与决策树插图
标准RNN本质上是一个及时展开的正向神经网络。这种安排可以通过引入网络的一个或多个隐藏状态与上一个时间点开始的相同隐藏状态之间的加权连接来实现,从而提供一些短期内存。挑战在于,这种短期记忆从根本上受到限制,就像训练深度网络很困难一样,使得香草RN的记忆确实很短。
通过许多隐藏层进行反向传播学习容易出现消失的梯度问题。在不详细介绍的情况下,该操作通常需要将错误信号重复乘以小于 1.0 的一系列值(激活函数梯度),从而衰减每一层的信号。通过时间进行反传播也存在同样的问题,这从根本上限制了从相对长期依赖中学习的能力。
深学习神经网络新激活功能的开发
对于使用前馈神经网络进行深度学习,渐变消失的挑战导致新激活函数(如 ReL)和新体系结构(如 ResNet 和 DenseNet)的普及。对于 RNN,一个早期的解决方案是完全跳过对循环层的训练,而是以它们执行输入数据的混沌非线性转换为更高维表示的方式初始化它们。
选择循环反馈和参数初始化,使系统几乎不稳定,并在输出中加入一个简单的线性层。学习仅限于最后一个线性层,这样可以在许多任务上获得合理的正常性能,同时通过完全忽略它来避免处理消失的梯度问题。计算机科学的这个子领域被称为储层计算,它甚至(在某种程度上)使用一桶水作为动态储层执行复杂计算。
储层型RNN不足有几个原因
对于准稳定动态储层,任何给定输入的效果都可以持续很长时间。然而,储层型RNN仍然不足,原因有几个:1)动态储层必须非常不稳定,长期依赖性才能持续,因此持续的刺激可能导致输出随时间而爆炸;2) 网络的下部/早期部分仍没有直接学习。塞普·霍奇赖特1991年的毕业证书(德语为pdf)描述了深层神经网络中梯度消失的根本问题,为塞普·霍奇赖特和约尔根·施密德胡伯在1997年发明长短期记忆(LSTM)循环神经网络铺平了道路。
LSTM 可以学习”正常”RNN 根本不能的长期依赖关系。这种能力背后的关键洞察力是一个称为单元状态的持久模块,该模块在时间上包含一个公共线程,每个时间步长仅受到几个线性操作的干扰。由于细胞状态连接到以前的单元状态仅被乘法和加法的线性操作中断,因此 LSTM 及其变体可以记住短期记忆(i长期属于同一”情节”)的活动。
多年来,对原始 LSTM 架构进行了多次修改,但令人惊奇的是,在 20 年后,经典变体在各种尖端任务中继续实现最先进的结果。话虽如此,什么是 LSTM 变体,它们有何用?
1. LSTM经典
经典的 LSTM 架构的特点是由非线性层包围的持久线性单元状态,从中馈送输入和分析输出。具体来说,细胞状态与4个门控层协同工作,这些通常称为遗忘、(2x)输入和输出门。
忘记门根据当前输入数据选择要删除的旧单元格状态的值。两个输入门(通常表示i和j)协同工作,根据输入决定向单元格状态添加哪些内容。i和j通常具有不同的激活功能,我们直观地期望使用该激活函数来建议缩放矢量和候选值以添加到单元格状态。
最后,输出门确定单元格状态的哪些部分应传递到输出。请注意,对于典型的 LSTM,输出h由隐藏层激活(例如,这些层可以进行进一步的层进行分类),并且输入由以前的隐藏状态输出和当前时间步长提供的任何新数据x组成。
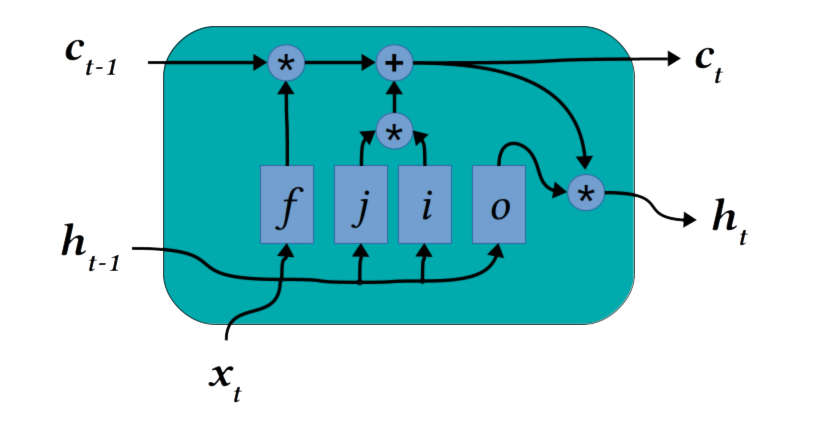
原始 LSTM 在一组合成实验中立即改进了技术,在相关数据段之间长时间滞后。快进到今天,我们仍然看到经典的LSTM形成了一个核心元素的最先进的强化学习突破,如Dota 2打队OpenAI五。
更详细地 (pdf)检查策略体系结构,您可以看到,虽然每个代理都使用多个密集的 ReLU 层进行特征提取和最终决策分类,但 1024 单元 LSTM 构成了每个代理的游戏体验的核心表示形式org/abs/1808.00177″ rel=”nofollow”目标=”_blank”]操纵彩色立方体以实现任意旋转。
2. 窥视孔连接
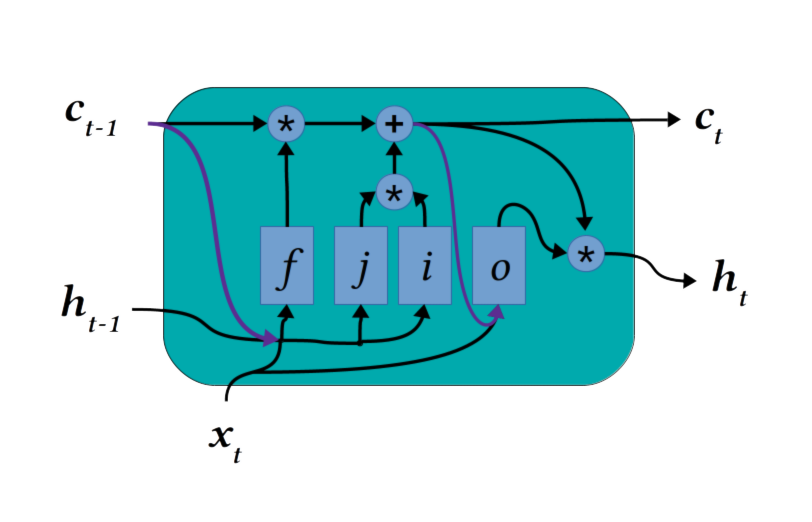
经典的 LSTM 通过持久细胞状态连接所有时间点(在早期描述 LSTM 的论文中称为”恒定误差旋转木马”),克服了梯度在循环神经网络中消失的问题。但是,确定要忘记的内容、要添加的内容,甚至从单元格状态中获取输出内容的浇注层不考虑单元格本身的内容。
从直觉上讲,在用新的记忆替换之前,代理或模型想知道它已有的记忆是有道理的。输入 LSTM 窥视孔连接。此修改(如上图中的深紫色所示)简单将单元格状态内容连接到门控层输入。特别是,当最初引入此变体时,此配置显示提供了改进的计数能力和罕见事件之间的时间距离。向 LSTM 中的层提供一些单元状态连接仍然是常见做法,尽管特定变体在提供访问对象时与哪些层完全不同。
3. 封闭经常性股
LSTM 门控循环单元插图
从图表上看,门控循环单元 (GRU) 看起来比经典 LSTM 复杂。事实上,它简单一些,而且由于其相对简单,训练速度比传统的LSTM快一点。GRUs将输入门j和忘记门f的浇注功能组合到单个更新门z中。
实际上,这意味着指定用于遗忘的单元格状态位置将与新数据的入口点匹配。GRU 的另一个关键区别是,单元格状态和隐藏输出h已合并到单个隐藏状态层中,而该单元还包含一个中间的内部隐藏状态。
门控循环单元 (GRUs) 已用于展示神经 GPU等异国情调概念的基础,以及一种更简单的序列学习序列模型,如机器翻译。GRUs 是一个有能力的 LSTM 变体,它们自创建以来一直相当受欢迎。虽然他们可以在音乐或文本生成等任务上快速学习,但由于计数方面的限制,他们最终被描述为不如经典 LSTM强大。
4. 乘法LSTM (2017)
Krause等人于2016年推出了乘法LSTMs(mLSTM)。从那时起,这个复杂的变体就成为自然语言处理领域众多高调、最先进的成就的核心。也许其中最著名的是OpenAI的无监督情绪神经元。
该项目的研究人员认为,通过在无监督文本预测上预先训练一个大型 mLSTM 模型,它变得更加强大,并且能够在一组 NLP 任务上以最小的微调在高级别上执行。文本中的一些有趣的特征(如情绪)被巧妙地映射到特定的神经元。
值得注意的是,在端到端蛋白质序列学习中,也报告了从无监督学习中产生的可解释分类神经元的相同现象。在蛋白质序列的下一个残留预测任务中,乘法LSTM模型显然学习了与基本次级结构图案(如α螺旋和β片)相对应的内部表示。蛋白质序列和结构是无监督、半监督序列学习模型取得重大突破的成熟领域。
尽管序列数据的数量在过去几年中呈指数级增长,但可用的蛋白质结构数据却以更悠闲的速度增长。因此,蛋白质折叠领域的下一个大 AI 不安可能涉及对纯序列进行某种程度的无监督学习,甚至可能在CASP13 蛋白质折叠挑战中超越 Deepmind 的不安注意的 LSTM
最后,我们得出了可能是序列模型中最近记忆中最具变革性的创新*。机器学习中的关注是指模型关注数据中特定元素的能力,在我们的案例中,LSTM 的隐藏状态输出。 Google 的 Wu等人使用一种架构,该架构由编码和解码 LSTM 层之间的关注网络组成,以实现最先进的神经机器翻译。
这可能继续推动谷歌翻译到今天。OpenAI 演示了在隐藏和查找强化学习环境中使用工具,这是 LSTM 的能力的最新示例,它关注复杂的非结构化任务。
在自然语言处理方面,LSTM 取得的重大成功预示了最佳语言模型中 L STM 的衰落。随着NLP研究可用的计算资源越来越强大,最先进的模型现在经常使用一种渴望内存的建筑风格,称为变压器。
变压器会消除LSTM,而有利于进给编码器/解码器。注意力变压器通过一次从整个序列片段中挑选,同时关注最重要的部分,消除了对细胞状态记忆的需求。BERT、ELMO、GPT-2和其他主要语言模型都遵循这种方法。
另一方面,最先进的 NLP 模型从零开始培训会产生重大的经济和环境影响,需要资源主要提供给与富有的科技公司相关的研究实验室。这些大型变压器模型的巨大能量需求使得传输学习变得更加重要,但它也为基于 LSTM 的序列到序列模型留下了足够的空间,以便对与大语言变压器训练的任务完全不同的任务做出有意义的贡献。
下一个项目的最佳 LSTM 是什么?
在本文中,我们讨论了许多 LSTM 变体,所有这些变体都有其优点和缺点。我们已经覆盖了很多领域,但事实上,我们只是触及了可能和已经尝试过的表面。好消息是,对于大多数序列到序列的学习任务,一个精心组合且无 Bug 的 LSTM 可能会执行与任何更深奥的变体一样,并且绝对能够在具有挑战性的环境中实现最先进的性能加强学习环境,正如我们上面讨论过的。
多篇文章比较了 LSTM 变体及其在各种典型任务上的性能。一般来说,1997 年的原始版本执行与较新的变体有关,并且注意偏置初始化等细节比使用的确切体系结构更重要。约瑟福维奇等人分析了超过10,000种不同的LSTM突变的性能,有些来自文献,但大多数生成为LSTM”突变体”,并发现一些突变在所研究的部分(但不是全部)任务上的表现确实优于经典的LSTM和GRU变异这种偏差对于避免使遗忘门受到阻碍,具有消失的梯度、具有小随机值的天真初始化以及 sigmoid 激活会导致忘记以 0.5 为中心的门值,从而迅速削弱长期学习的能力。依赖。
了解 LSTM 对于项目的良好绩效至关重要
最终,为您的项目提供的最佳 LSTM 将是一个优化最佳且无 Bug 的 LSTM,因此详细了解其工作原理非常重要。GRU 等架构提供良好的性能和简化的体系结构,而诸如乘法 LSTM 等变体在不受监督的序列到序列任务中生成了有趣的结果。
另一方面,像mLSTM这样的相对复杂的变体在本质上引入了更高的复杂性,也就是”吸引漏洞的表面”。首先,构建一个简化的变体并处理一些玩具问题,以充分理解细胞状态和门控层的相互作用可能是一个好主意。
此外,如果您的项目有很多其他复杂性要考虑(例如,在复杂的强化学习问题中),更简单的变体从开始更有意义。通过构建和优化相对简单的 LSTM 变体的经验,并在主要问题的简化版本上部署这些变体,可以构建具有多个 LSTM 层和关注机制的复杂模型。
最后,如果你的目标不仅仅是教条,而且你的问题被以前开发和训练的模型很好地勾勒出来,”不要成为英雄”。采用预先训练的模型并根据您的需求进行微调会更有效。节省的经济和环境成本以及开发人员时间,由于主要 AI 实验室为培训最先进的 NLP 模型带来了大量数据和计算资源,因此性能可以同样好或更好。
*不幸的是,这两个双关语都是完全有意的。