
AI系统发展趋势与挑战
1.关键任务AI系统
趋势: AI推动了越来越多的关键任务在生活中的应用,例如自动驾驶、机械辅助手术、家庭自动化,与人类的福祉和生命息息相关。
挑战: AI系统需要通过与动态环境交互持续学习,并且做出及时、鲁棒,以及安全的决策。
2.个性化AI系统
趋势:从虚拟助理、自动驾驶到政治运动,为用户提供量身定做的决策正日益成为AI系统设计的关注焦点。个性化AI系统要考虑用户的行为和喜好。
挑战:设计能够提供个性化应用程序和服务的AI系统,但不能损害用户的隐私和安全性。
3.跨组织AI系统
趋势:越来越多的组织在利用第三方数据来增强他们的人工智能服务。例如医院共享数据以防止疫情爆发,金融机构共享数据以提高防欺诈能力。这种应用场景的普及将带来从数据仓库(一个公司收集数据,处理数据,并提供服务)到数据生态系统(AI应用可以使用不同组织拥有的数据进行学习和决策)的过渡。
挑战:设计出能够在由不同组织所拥有的数据集上进行训练的AI系统,而不影响组织之间的数据保密性,并且在这个过程中能够跨越组织之间的潜在竞争障碍。
4.AI的需求超过摩尔定律
趋势:能够处理和存储海量数据是AI取得成功的一个重要前提,然而技术的发展将越来越难追赶上数据产生的速度。首先,数据正在持续指数增长。其次,数据的激增恰巧发生在我们曾经飞速改善的硬件技术面临停滞的时候。
挑战:开发特定领域的架构和软件系统,以满足后摩尔法则时代,未来AI应用程序的性能需求,包括适用于AI工作负载的定制芯片、边缘云系统以有效处理边缘数据,以及简化和采样数据的技术。
针对这些挑战,本文在3个主要领域(动态环境中的行为、安全AI,以及AI特定的体系结构)中确定了9个未来的研究方向(R1-R9)。
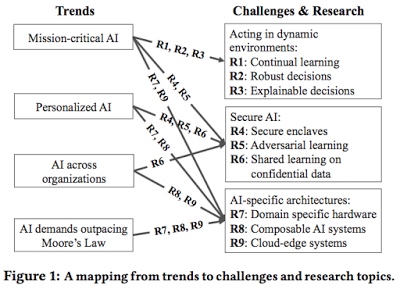 

趋势、挑战和研究主题之间的关系。
动态环境中的行为
未来的大部分AI系统都将在动态环境中运行,这就要求AI系统能够快速安全作出反应,即使对于之前从来没有遇到的场景。
R1:不断学习
在动态环境下学习的AI系统一般使用强化学习(Reinforcement Learning,RL)框架。尽管最近强化学习与深度神经网络的成功结合开发出了能在多种环境下工作的AI系统(例如AlphaGo打败世界象棋冠军),强化学习并没有得到大规模的实际应用。作者认为,强化学习算法的进步与系统设计的创新结合,将推动新的强化学习应用程序的发展。
研究方向:(1)构建能够充分利用并行性的强化学习系统,同时允许动态任务图,满足毫秒级延迟,并在严格的要求时间内在异构硬件上运行。(2)构建能够完全模拟真实环境的系统,因为真实环境会不断产生难以预料的变化,而且运行速度要超过实时。
R2:鲁棒决策
越来越多的AI应用程序正在代替人类做出决策,尤其是在关键任务中。一个重要的标准是它们需要对输入和反馈中的不确定和错误保持鲁棒性。
AI系统中最重要的两个鲁棒性概念是:(1)在有噪声和对抗反馈的情况下能够进行鲁棒学习,(2)在不可预见的和对抗输入的情况下给出鲁棒决策。
研究方向:(1)在AI系统中建立细粒度的源头支持,将结果(例如奖励或状态)变化与引起这些变化的数据源连接起来,并自动学习出因果的、特定于源的噪声模型。(2)为开发系统设计API和语言支持,使系统能够维护制定决策的置信区间,特别是标记不可预见的输入。
R3:可解释决策
除了进行黑箱预测和决策,AI系统也需要为他们的决策提供人类能够理解的解释。因果推断领域在未来AI系统的应用中是十分重要的,并且该领域与数据库中的系统诊断和源思想有着自然联系。
研究方向:(1)构建能够支持交互式诊断分析的AI系统,能够重现之前的运行过程,并能够确定负责特定决策的输入特征,一般方法是通过对之前的扰动输入重新执行决策任务,(2)为因果推理提供系统支持。
安全AI
AI系统的安全问题可以分为两类:第一类是攻击者破坏决策过程的完整性。第二类是攻击者学习用于AI系统训练的机密数据,或学习保密模型。
R4:安全飞地
防止这些攻击的方法是提供安全飞地(secure enclaves)。安全飞地是指安全的执行环境,它保护飞地内部运行的应用程序,防止受到飞地外运行的恶意代码的危害。
研究方向:构建利用安全飞地来确保数据机密性、用户隐私和决策完整性的AI系统,可以通过将AI系统的代码分割为在飞地内运行的最小代码库,以及在飞地以外运行的代码。确保飞地内的代码不会泄露信息,也不会影响决策的完整性。
R5:对抗学习
机器学习算法的自适应性使学习系统易受到新类型的攻击,这些攻击通过恶意改变训练数据或决策输入来破坏决策的完整性。主要有两种类型的攻击:闪避攻击(evasion attack)和数据中毒攻击(data poisoning attack)。
闪避攻击发生在系统推理阶段,攻击者试图产生被学习系统错误分类的数据。数据中毒攻击发生在训练阶段,攻击者将中毒数据(例如错误标签的数据)注入到训练数据集中,导致学习系统学习出错误模式。
研究方向:构建在训练和预测阶段对对抗性输入鲁棒的AI系统,可以通过设计新的机器学习模型和网络结构,利用源追踪虚假数据源,并在消除虚假数据源后重新进行决策。
R6:机密数据的共享学习
如今,公司与企业通常各自收集数据、分析数据,并使用这些数据来实现新的特性和产品。然而,并不是所有的组织都拥有与大型AI公司相同数量的数据。我们期望越来越多的组织能够收集有价值的数据,有更多的第三方数据服务可用,并从多个组织的数据中共享学习。
共享学习的主要挑战是如何在跨组织数据上学习模型,同时保证训练过程中不会泄露相关信息。主要有三种方法:(1)将所有数据汇集到硬盘飞地,然后学习模型,(2)使用安全多方计算技术(secure multi-party computation),(3)使用差分隐私(differential privacy)技术。
研究方向:构建AI系统:(1)能够跨数据源学习,同时在训练或测试过程中不泄露数据源的信息,(2)激励潜在的竞争组织共享他们的数据或模型。
AI特定的架构
AI系统的需求会驱动系统和硬件架构的创新。这些新架构的目标不只是提升性能,而且要通过提供丰富的、易组合的模块库简化下一代AI应用的开发。
R7:域特定的硬件
在数据持续指数性增长时,40年来一直推动着计算机产业发展的“性能-成本-能源”技术进步已经接近终点,唯一能够继续改进处理器的方法就是开发域特定的处理器。
研究方向:(1)设计域特定硬件架构来提升性能,并大幅度降低AI应用的能量消耗,并增强这些应用的安全性,(2)设计能够利用域特定架构、资源分解架构,以及未来的非易失性存储技术的AI软件系统。
R8:可组合的AI系统
模块化和组合是提高人工智能开发速度和应用的关键,它使AI更容易在复杂系统中集成。
研究方向:设计能够以模块化、灵活的方式组合模型和动作的AI系统和API,并利用这些API开发丰富的模型库和可选项,以极大地简化AI应用的开发。
R9:云边缘系统
目前大量AI应用服务,例如语音识别和语言翻译,均部署在云上。我们期望未来AI系统的跨度可以连接云和边缘设备。首先,部署在云的AI系统可以将部分功能移至边缘设备以提高安全性、隐私性、低延迟和安全性。其次,部署在边缘的AI系统可以分享数据,并利用云的计算资源来更新模型。
研究方向:设计云边缘AI系统,(1)利用边缘降低延迟,提升安全性,实现智能数据保持技术,(2)利用云在跨边缘设备上分享数据和模型,训练复杂的计算密集型模型,并且采取高质量的决策。
延伸思考
(评论来自纽约州立大学布法洛分校Murat Demirbas教授)
1) 2009年,伯克利发表了一篇类似的关于云计算的立场论文(Above the Clouds: A Berkeley View of Cloud Computing)。这篇论文对云计算思想进行了很好的总结、整理。但是8年过去了,那篇文章中的研究计划进行的并不是很理想。计划是无用的,但计划是必不可少的。学界所感兴趣的区域一直在随时间变化,研究方向也在相应变化。在CS领域,几乎不可能完全计划和管理探索性研究(或许在生物学和科学领域是可能的)。
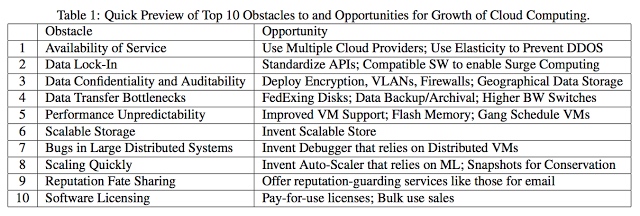 

论文中提出的第4,5,6项研究方向进展良好,剩下的进展平淡,项目2和9进展甚微。下面几个研究方向虽然在这份研究计划中没有提及,但它们实实在在重塑了云计算领域的发展进程。
云中机器学习工作负载的优势
新SQL系统的崛起,一致分布式数据库的增多,协调组、Paxos算法、ZooKeeper服务在云中的重要性
开发在线内存数据流和流处理系统,如Spark,来自伯克利
通过容器和函数作为服务实现细粒度虚拟化的竞争
SLA受到更多的重视
即使伯克利提出的AI系统研究计划很有道理,我们还是应该关注未来几年内这些计划的进展,以及AI系统领域会带来怎样令人意想不到的研究机遇。
2)斯坦福在今年早些时间也发表了一篇类似的立场论文,不过他们的论文是关于机器学习中可复用架构的问题和见解。斯坦福的DAWN项目旨在建立端到端的机器学习工作流,加入领域专家的力量,并进行端到端的优化。下图总结了他们对于可复用机器学习架构的想法:
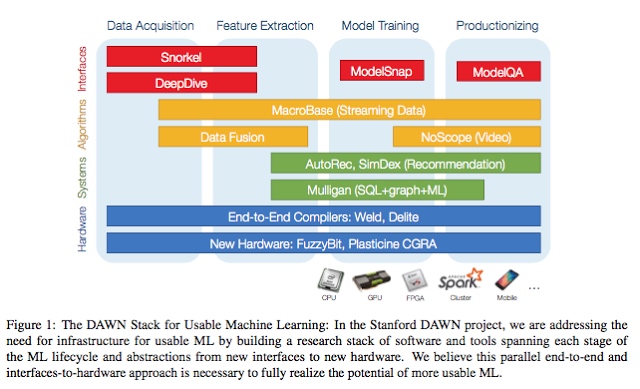 

当然,这也无可避免地反映了斯坦福团队的优势和弊端:他们更擅长于数据库、数据科学、以及生产方面的研究。看起来与伯克利论文中的“AI特定架构”部分有一些共同点,但是双方针对相同的问题提出了不同的方法。
3) 对于文中提出的R2鲁棒决策这一研究方向,似乎是想说形式化方法——建模、基于不变的推理,是有用的,尤其是当并发控制成为分布式机器学习部署中的一个问题时。