
数据孤岛问题就像在线企业的关节炎,因为几乎每个人随着年龄的增长都会遇到这个问题。企业通过网站、移动应用、H5 页面和终端设备与客户互动。出于某种原因,整合所有这些来源的数据是一件很棘手的事情。数据保留在原处,无法相互关联以进行进一步分析。这就是数据孤岛的形成方式。您的业务规模越大,您拥有的客户数据源就越多样化,您就越有可能陷入数据孤岛。
这正是我将在这篇文章中讨论的保险公司所发生的情况。到2023年,他们已服务超过5亿客户,签订了570亿份保险合同。当他们开始构建客户数据平台(CDP)来适应如此大的数据规模时,他们使用了多个组件。
CDP 中的数据孤岛
与大多数数据平台一样,他们的 CDP 1.0 具有批处理管道和实时流管道。离线数据通过 Spark 作业加载到 Impala,在那里被标记并分成组。同时,Spark 还将其发送到 NebulaGraph 进行 OneID 计算(本文稍后详细阐述)。另一方面,实时数据通过Flink打标签,然后存储在HBase中,以供查询。
这导致了 CDP 中的组件密集型计算层:Impala、Spark、NebulaGraph 和 HBase。

因此,离线标签、实时标签和图形数据分散在多个组件中。由于冗余存储和大量数据传输,将它们集成以提供进一步的数据服务成本高昂。而且,由于存储的差异,他们不得不扩大CDH集群和NebulaGraph集群的规模,增加了资源和维护成本。
基于 Apache Doris 的 CDP
对于 CDP 2.0,他们决定引入一个统一的解决方案来收拾残局。在CDP 2.0的计算层,Apache Doris承担实时和离线数据存储和计算。
为了获取离线数据,他们利用流加载方法。他们的 30 线程摄取测试表明,它每秒可以执行超过 300,000 次更新插入。为了加载实时数据,他们使用Flink-Doris-Connector的组合 和流负载。此外,在需要从多个外部数据源提取数据的实时报告中,他们利用了Multi- 联合查询的目录功能。
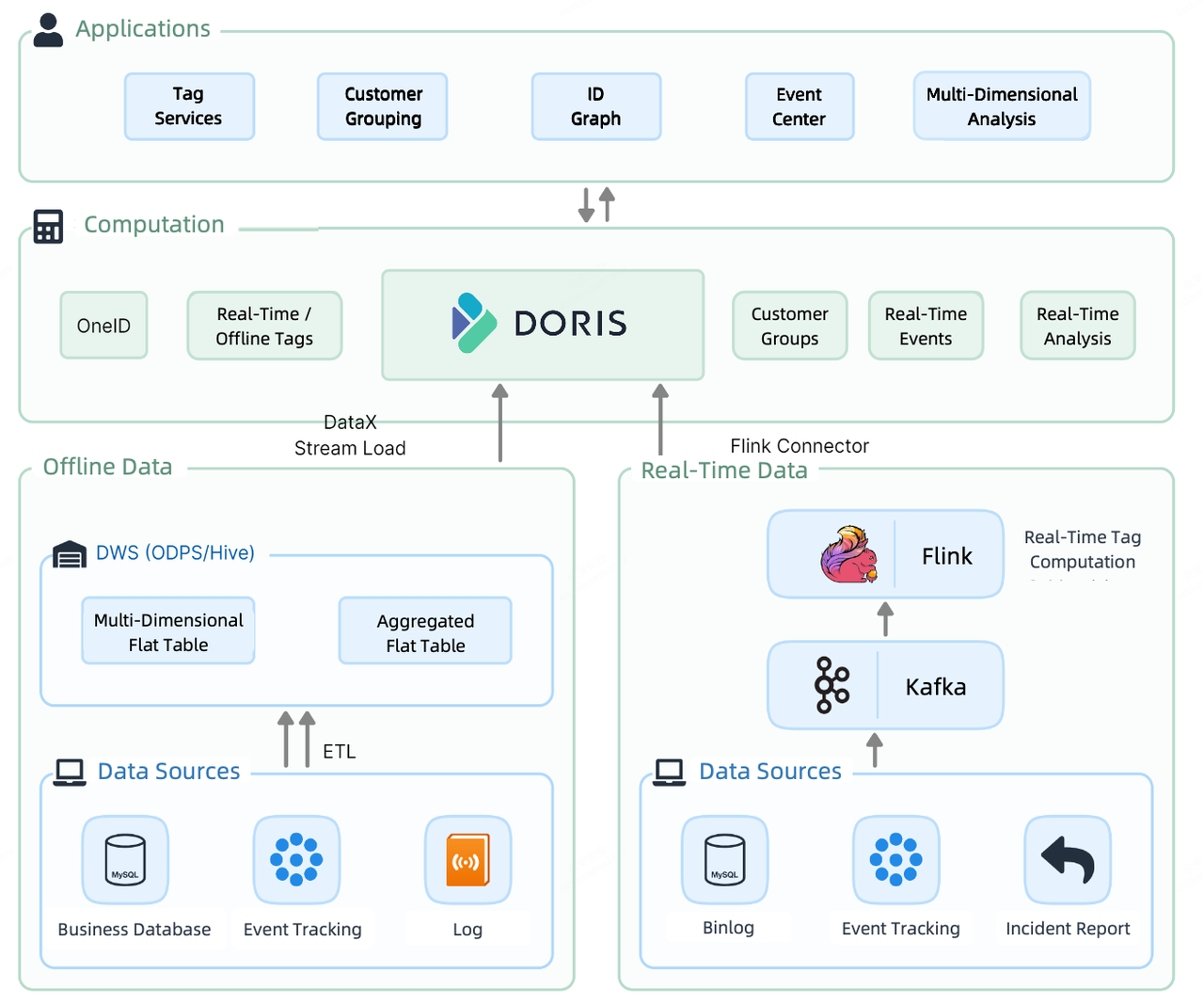
此 CDP 上的客户分析工作流程如下。首先,他们整理客户信息,然后为每个客户贴上标签。他们根据标签对客户进行分组,进行更有针对性的分析和操作。
接下来,我将深入研究这些工作负载并向您展示 Apache Doris 如何加速它们。
OneID
当您的产品和服务有不同的用户注册系统时,您是否遇到过这种情况?您可以从一个产品网页收集用户 ID A 的电子邮件,然后从另一个产品网页收集用户 ID B 的社会安全号码。然后您会发现 UserID A 和 UserID B 实际上属于同一个人,因为他们使用相同的电话号码。
这就是 OneID 作为一个想法出现的原因。就是将所有业务线的用户注册信息汇集到Apache Doris中一张大表中,进行整理,并确保每个用户拥有唯一的OneID。
这就是他们如何利用 Apache Doris 中的功能来确定哪些注册信息属于同一用户。
标记服务
该CDP可容纳5亿客户的信息,这些信息来自500多个源表,总共附加到2000多个标签。
按照时效性,标签可以分为实时标签和离线标签。实时标签由 Apache Flink 计算并写入 Apache Doris 中的平面表,而离线标签由 Apache Doris 计算,因为它们源自 Doris 中的用户属性表、业务表和用户行为表。以下是该公司在数据标记方面的最佳实践:
1。离线标签
在数据写入高峰期,由于数据规模庞大,全量更新很容易导致OOM错误。为了避免这种情况,他们利用了 INSERT INTO SELECT 函数Apache Doris 并启用部分列更新。这将大大减少内存消耗并保持数据加载过程中的系统稳定性。
设置enable_unique_key_partial_update=true;
插入 tb_label_result(one_id, labelxx)
选择 one_id、label_value 作为 labelxx
来自......2.实时标签
部分列更新也可用于实时标记,因为即使实时标记也会以不同的速度更新。所需要做的就是将 partial_columns 设置为 true。< /p>
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load3.高并发点查询
以目前的业务规模,该公司正在以超过 5000 QPS 的并发级别接收标签查询请求。他们使用策略组合来保证高性能。首先,他们采用 Prepared Statement 进行预编译和预编译- SQL 的执行。其次,他们微调 Doris 后端和表的参数以优化存储和执行。最后,他们启用行缓存作为对面向列的 Apache Doris。
-
在
be.conf中微调 Doris 的后端参数:
disable_storage_row_cache = false
storage_page_cache_limit=40%
-
创建表时微调表参数:
enable_unique_key_merge_on_write = true
store_row_column = true
light_schema_change = true
4。标签计算(Join)
在实践中,很多标签服务都是通过数据库中的多表连接来实现的。这通常涉及 10 多个表。为了获得最佳计算性能,他们在 Doris 中采用 colocation group 策略。
客户分组
CDP 2.0 中的客户分组管道是这样的:Apache Doris 从客户服务接收 SQL,执行计算,并通过 SELECT INTO OUTFILE 将结果集发送到 S3 对象存储。该公司已将其客户分为100万组。过去在 Impala 中需要 50 秒才能完成的客户分组任务,现在在 Doris 中只需要 10 秒。

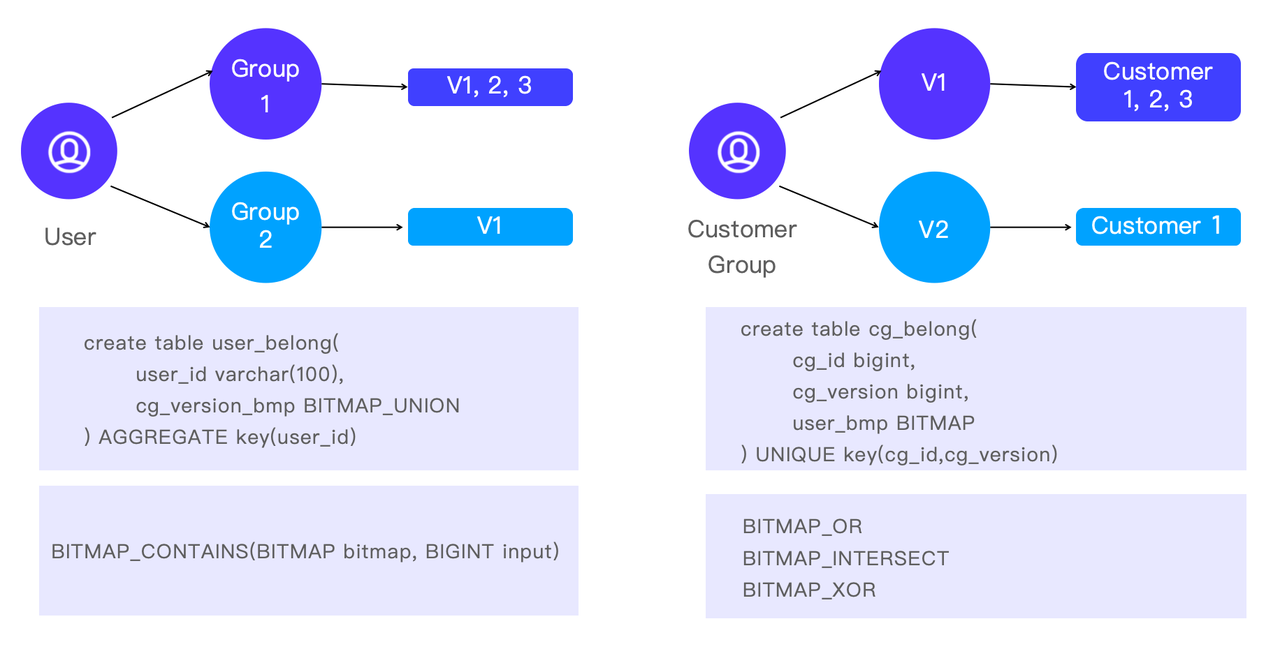
除了对客户进行分组进行更细粒度的分析外,有时他们还会进行反向分析。即针对某个客户,找出他/她属于哪些群体。这有助于分析师了解客户的特征以及不同客户群体的重叠情况。
在 Apache Doris 中,这是通过 BITMAP 函数实现的:BITMAP_CONTAINS 是检查客户是否属于某个组的快速方法、BITMAP_OR、BITMAP_INTERSECT 和 BITMAP_XOR 是交叉分析的选择。
结论
从CDP 1.0到CDP 2.0,保险公司采用统一数据仓库Apache Doris替代Spark+Impala+HBase+NebulaGraph。通过打破数据孤岛和简化数据处理管道,提高了数据处理效率。在CDP 3.0中,他们希望通过结合实时标签和离线标签来对客户进行分组,以进行更加多样化和灵活的分析。 Apache Doris 社区 和 VeloDB团队将在本次升级期间继续作为支持合作伙伴。
 服务的 Web 用户界面")


