
进入人工智能 (AI) 领域,机器学习模型和智能算法正在彻底改变我们与数据交互、制定决策和预测结果的方式。 AI 与 Node.js 的融合打开了通往多种可能性的门户,改变了包括体育和健身在内的各个领域的 Web 服务格局。
生命周期
在应用程序的基础上,我们将提供一些基于人工智能生成的日常体育活动建议。这意味着我们做了人工智能建议的活动,然后我们必须再次询问人工智能的建议。然后我们会收到人工智能对我们的应用程序的响应,并在第二天公开它。然后用户会日复一日地看到新的建议计划。
< img alt="体育活动生成的生命周期" class="lazyload" data-creationdate="1710366392118" data-creationdateformatted="03/13/2024 09:46 PM" data-id="17565238" data-image="true “ data-mimetype =“image/jpeg” data-modificationdate =“ null” data-name =“ezgif-4-5c220188fb.jpg” data-new =“ false” data-size =“ 119126” data-sizeformatted =“ 119.1” kB" data-src="https://dz2cdn1.dzone.com/storage/temp/17565238-ezgif-4-5c220188fb.jpg" data-type="temp" data-url="https://dz2cdn1.dzone .com/storage/temp/17565238-ezgif-4-5c220188fb.jpg" src="http://www.cheeli.com.cn/wp-content/uploads/2024/03/17565238-ezgif-4-5c220188fb. jpg"/>
此外,我们将限制用户可以单独完成的体育活动。

假设足球或曲棍球可以由用户完成,但这是一项团队游戏,需要一些额外的提示设置来生成 AI。我们将特别关注单人活动,这将使我们在一开始就变得简单。
设置 OpenAI API
路径将非常简单。在我们的例子中,我们将使用 OpenAI API 和 Node.js 环境。这通常很容易从主仪表板或菜单中找到。
如果您是新用户或之前从未使用过该 API,则可能需要申请访问权限。这可能需要填写一份表格,在其中解释您计划如何使用 API。
OpenAI 可能有不同的计划,包括免费或付费选项,具体取决于使用限制和附加功能。对于大多数付费计划,您需要输入账单信息。
您的帐户设置完毕并拥有 API 访问权限后,您将获得一个 API 密钥。该密钥是一长串字符,用于唯一标识您的帐户。
让我们转到 OpenAI 并导航到 API 部分。导航至 https://platform.openai.com/api-keys 。从 api-keys 列表中获取您要使用的内容。该键看起来像这样:
OPENAI_API_KEY="sk-PMCRj7YiTV9e8OdTV26AI7BhcdkFJYZ3lu0p00H3217315y84"使用您的 API 密钥,您可以开始向 OpenAI API 发出请求。在代码中,您通常会在 HTTP 标头或配置文件中设置此密钥来验证您的 API 请求。
在这里您可以看到我们将如何继续:
 服务构建流程
服务构建流程
选择 OpenAI 模型
最好的模型是 GPT-4 系列中的模型,能够根据大量信息处理和生成文本。但在我们的例子中,我将使用 gpt-3.5-turbo。该模型速度超快,并针对更快的响应进行了优化。此外,它的设计更具成本效益,使其成为需要频繁且大量 API 调用的应用程序的合适选择。
设置 Node.js 环境
让我们使用 express 生成一个简单的节点应用程序框架。为此,我使用 create-node-application,但这取决于您使用哪个生成器或自行设置。我们需要一个环境和入口点来公开端点。
npx create-node-application sports_activity_servise -fw=express该项目应该有一个带有 `index.ts` 的 `src` 文件,它应该是启动服务器的简单默认设置。
应用程序监听 http://localhost:3000如果您能够通过访问该 URL 获得 Hello world,那么一切都很好。
让我们看一下该服务的结构。
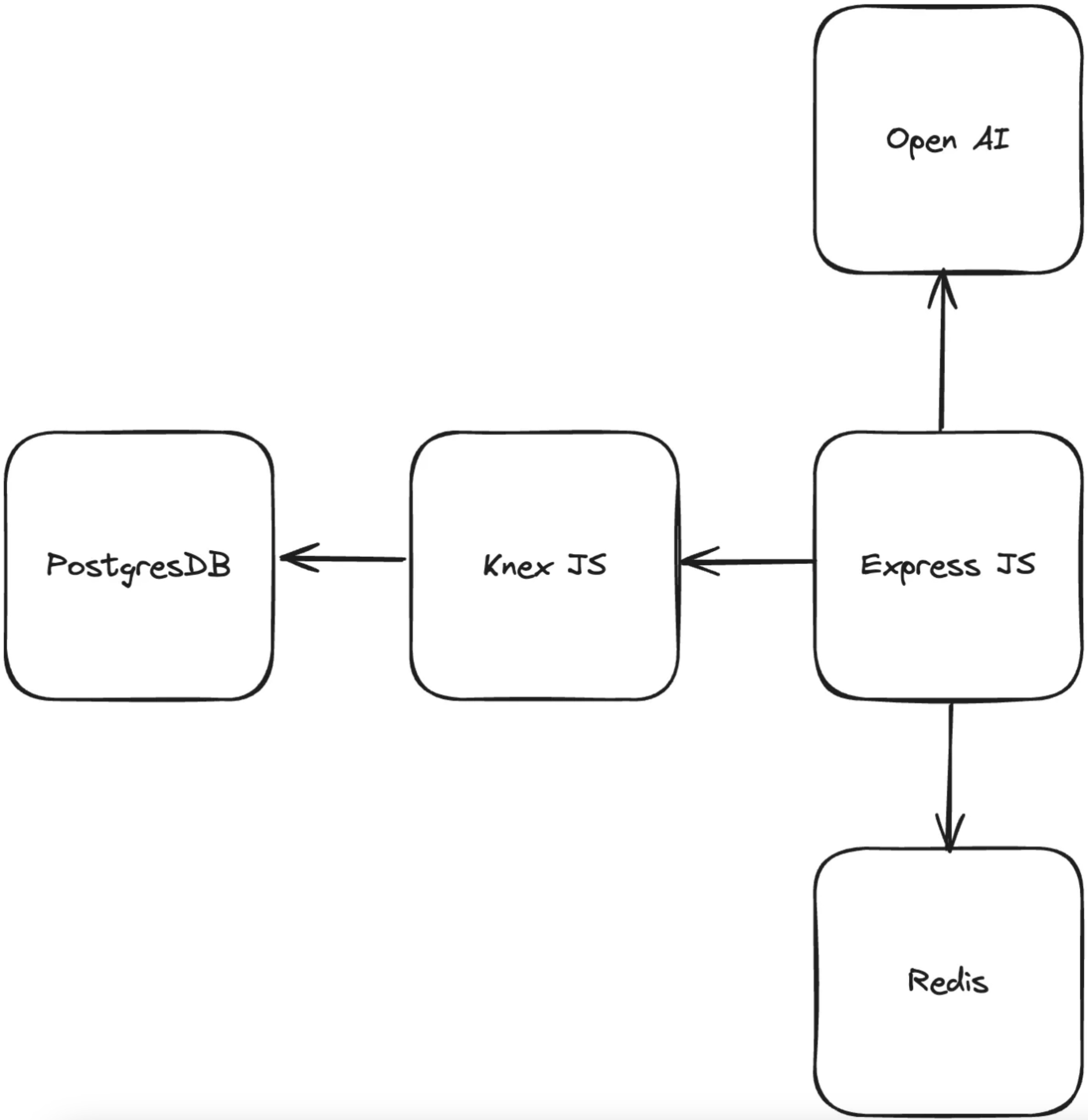 应用程序架构
应用程序架构
现在我们需要安装依赖项。运行 npm i --save openai 并在 package.json 中验证该软件包是否已安装。

package.json 中的 OpenAI 包
下一步是验证环境变量。为此,我们必须在 sports_activity_servise 的根目录中创建 .env 并添加以下值:

体育活动服务的环境变量
现在,借助 dotenv 包,我们可以在应用程序中使用这些值。我们使用从平台获取的OPENAI_API_KEY。为此,我们需要创建 src/config/index.ts 并添加以下代码:
从 'openai' 导入 OpenAI;
导出 const openai = 新 OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});此配置将允许我们访问 OpenAI 界面,我们计划在控制器中使用该界面。
OpenAI 与 Node.js 的结合使用
要准确推荐体育活动,收集有关用户的具体信息至关重要。在我们的数据库中,我们的目标是收集基本的用户指标以及自服务提供的最后建议以来他们所进行的活动的历史记录。让我们回顾一下架构。
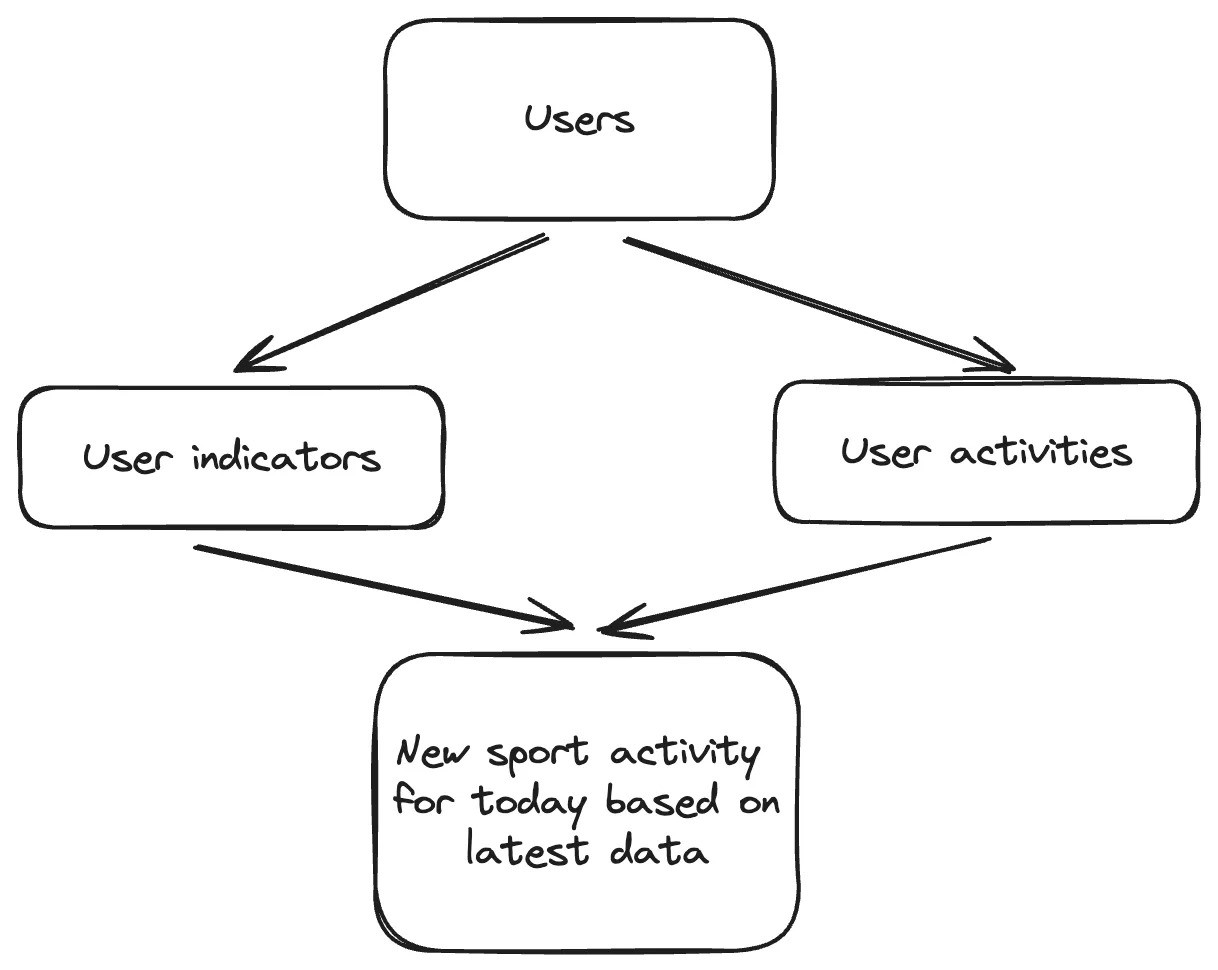
基于指标和活动历史的体育活动结果
如你所见,结果总是受到历史的影响。然而,这一结果可以通过多种因素得到增强。最终的建议可能会受到当前天气、活动频率、合作伙伴、居住区域、生活方式和可达性等因素的影响。我们将集中精力选择其中的几个因素来简化流程。

构建 OpenAI 提示的架构
我们需要构建一个简洁的提示,清楚地向 OpenAI 传达我们对详细说明今天活动的响应的要求。
如前所述,我们将利用 Knex 进行数据库交互。有关设置数据库、执行迁移和播种的指导,请参阅我的另一篇文章:如何在 Express 上使用 Postgres 和 Knex 创建 Node.js 服务器。
让我们为数据库开发必要的迁移:
knex migrate:make create_users_table -x ts
knex 迁移:make create_indicators_table -x ts
knex 迁移:make create_activities_table -x ts然后一一填写:
用户表迁移文件
指标表迁移文件
活动的迁移将包含一个布尔标志来指示完成。这对于确定发送另一个建议的适当时机是必要的。
活动表迁移文件
接下来,执行knex migrate:latest将所有指定字段合并到数据库中。接下来,要使用初始数据填充数据库,请执行播种命令:
knex 种子:make 01-users -x ts
knex 种子:make 02-指标 -x ts包含以下文件:
01-users.ts — 用户种子
02-indicators.ts — 指标种子
正如您所观察到的,用户的指标非常基本。此外,虽然提示可能包括更多上下文的活动历史记录,但我们将在初始播种过程中省略此步骤。准备好所有文件后,只需执行 knex seeds:run 即可填充数据库。至此,我们的数据库已经准备就绪。
现在在 src 文件夹中创建一个 index.ts 作为我们服务的入口点:
服务入口点
路由
在我们继续构建控制器之前,让我们检查一下从 src/routes/index.ts 获取的路由设置。
从 'express' 导入 { Router };
从 'src/routes/authRouter' 导入 { authRouter };
从 'src/controllers/sessionController' 导入 { sessionController } ;
从 'src/middlewares/authMiddleware' 导入 { authMiddleware };
从 'src/routes/userRouter' 导入 { userRouter };
从 'src/routes/suggestionRouter' 导入 { suggestRouter } ;
从'src/routes/indicatorRouter'导入{indicatorRouter};
导出 const router = Router({ mergeParams: true });
router.use('/auth', authRouter);
router.use(authMiddleware);
router.get('/session', sessionController);
router.use('/user', userRouter);
router.use('/suggestion', suggestRouter);
router.use('/indicator', IndicatorRouter);申请途径
为了保持焦点并避免偏离当前上下文,我们将绕过 Redis 和身份验证段的设置。要深入探索这些领域,请参阅我有关 Node.js 应用程序中的身份验证的其他文章。
在接下来的迭代中,我们将从中间件 authMiddleware 获取用户会话:req.user = userSession。此会话仅包含标识符,没有其他信息。
导出类型 UserSession = {
身份证号;
}我们将利用该 ID 来检索用户以及提示所需的所有基本数据。请记住,我们的目标是构建适合 OpenAI 的提示。
我们将从 suggestionRouter 获取建议,其中包含 get 和 post 端点。
从 'express' 导入 { Router };
从 'src/controllers/suggestion/getSuggestionController' 导入 { getSuggestionController };
从 'src/controllers/suggestion/finishLastSuggestionController' 导入 { finishLastSuggestionController };
导出 const suggestRouter = Router({ mergeParams: true });
suggestRouter.get('/', getSuggestionController);
suggestRouter.post('/finish', finishLastSuggestionController);建议路由器
最后一个组件是 indicatorRouter,它包含一个控制器:
从 'express' 导入 { Router };
从 'src/controllers/indicators/updateIndicatorController' 导入 { updateIndicatorController } ;
导出 const IndicatorRouter = Router({ mergeParams: true });
IndicatorRouter.post('/', updateIndicatorController);指标路由器
模型
现在,是时候探索模型的功能以及如何管理它们了。有关创建模块的更多详细信息,我在另一篇文章中提供了深入的解释:使用 Knex.js 和 PostgreSQL 制作数据库模型。您可以在那里查看如何构建基本的模型并将其用于其他模型。我们需要在文件夹 src/models 中添加 3 个额外模型:
用户模型
指标模型
活动模型
所有这些模型都继承自一个基本模型,该模型提供了用于 get、set 或 delete 方法的工具集合。现在,我们准备将这些模型合并到我们的控制器中。
提示的期望
现在,让我们从核心实现细节中退一步,关注我们对 OpenAI 的期望结果。
- 它需要是一个将结果返回给我们的 GET 端点。我们的路线:
localhost:9999/api/v1/suggestion - 结果应该是一个 JSON 对象,其中包含我们期望在响应中出现的特定键。
- 它应该以我们可以轻松识别的格式返回活动类型。
让我们回顾一下此图中描绘的 Postman 的响应。

邮递员对建议路线的响应
我们旨在描述的响应类型类似于以下内容:Promise
导出类型 Activity = {
身份证号;
活动类型:字符串;
is_completed:布尔值;
持续时间:数量;
创建时间:日期;
};
导出类型 ActivityDescription = {
描述:字符串;
水消耗:数量;
距离?: 数量;
计划:字符串[];
};
导出类型建议 = Activity & ActivityDescription;因此,这意味着我们需要创建一个函数:getSportActivitySuggestion,该函数将向我们返回一个带有suggestion 数据的承诺.
但是我们应该多久收到一次此建议呢?一种方法是使用计时器或等到最后建议完成,如上次活动后客户端发出的具有新指标的 POST 请求所指示的那样。这是架构:
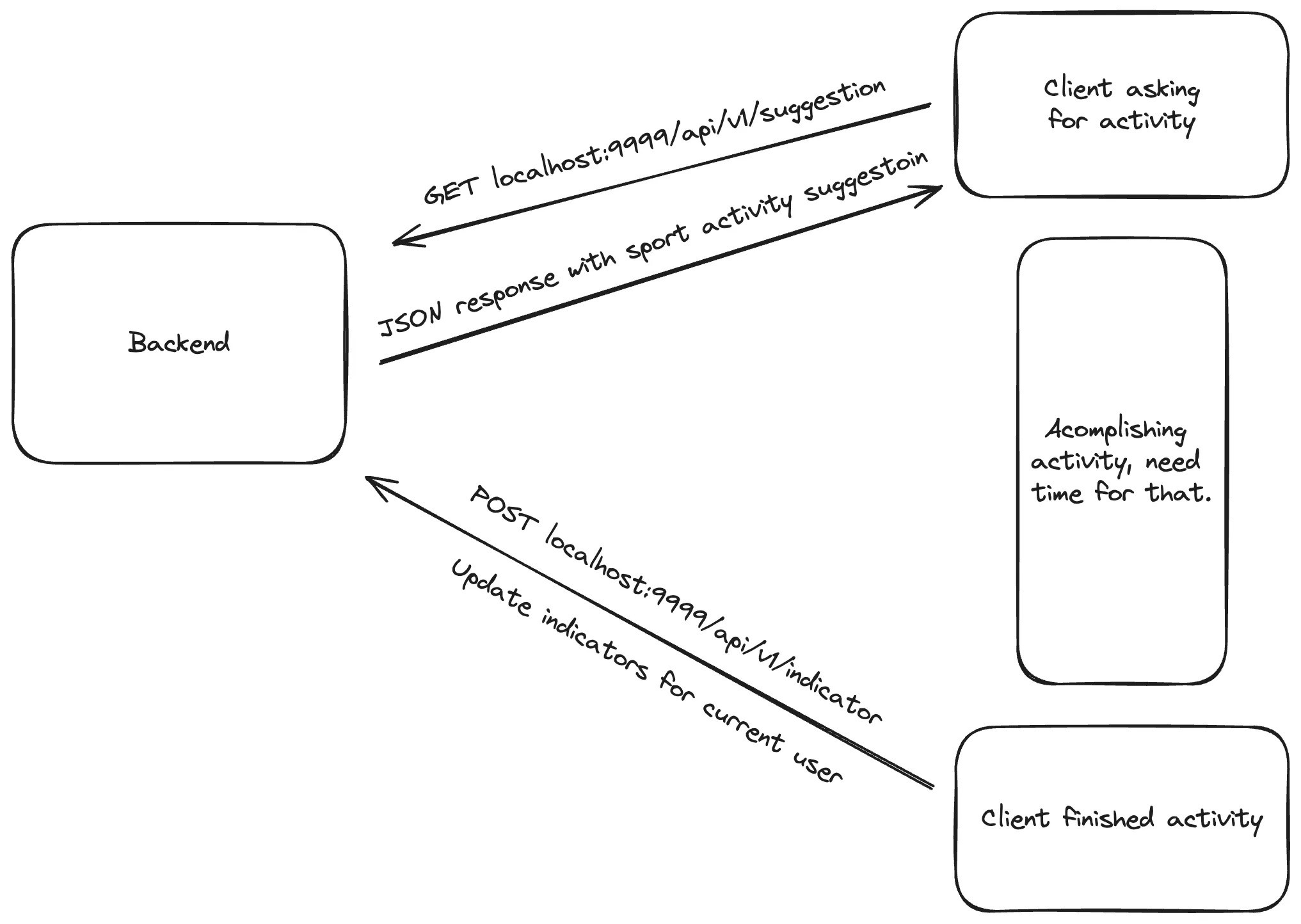
建议和更新指标的生命周期。
当客户端发送建议请求时,客户端应用程序还应指定下一个请求的时间。这可能会在更新指标后立即发生,作为向客户发出的信号,表明是时候寻求新建议了,具体取决于自上次建议以来经过的时间。
获取体育活动建议
现在,我们需要开发一个控制器来管理建议结果。为此,请创建 src/controllers/getSuggestionController 并插入以下代码:
getSuggestionController.ts
收到建议后,我们必须验证上一个活动的状态 is_completed,以避免在活动已在进行时向 OpenAI API 发出不必要的请求。如果没有活动活动,我们会通过 getSportActivitySuggestion 辅助函数获取建议。接下来,我们必须在数据库中以适当的状态记录用户 ID 下的活动,以便将来的建议请求能够检索。最终,我们返回该结果。
要从助手那里获取建议,我们必须为 OpenAI API 负载制作适当的提示消息。让我们深入研究一下辅助函数执行的流程。
辅助函数使用 OpenAI API 基于类似对话的结构生成补全。
本质上,我们正在制作适当的消息来创建补全,模拟对话,并指示系统如何准确地构建响应。我们整合了指标的所有参数、响应示例以及上次完成的活动的详细信息。例如,函数 openai.chat.completions.create() 表示我们需要创建补全并生成文本。在属性messages中,您可以找到role,它可以是system,我们在其中提供指令,user代表来自的输入用户。 content 消息的内容,可以是提示或用户输入。 model 指定用于生成补全的模型,它是针对速度和性能进行优化的 GPT-3.5 模型的特定版本,在我们的例子中是最便宜的版本。最后一个参数是温度,它控制生成文本的随机性。较高的温度会导致更多样化的输出,而较低的温度会产生更保守、可预测的结果。这里,它设置为 0.9,表示中等程度的随机性。最后,我们简单地从完成结果中解析 JSON。
gpt-3.5-turbo 的价格取决于提供商和使用条款。通常,使用 GPT-3.5 Turbo 等模型的定价取决于发出的请求数量、请求的复杂性以及提供的任何附加服务等因素。最好与模型的具体提供商联系以获取准确的定价信息。
我们需要创建一个控制器来负责完成最后一个活动:
完成最后一项活动
并更新 POST 请求中包含的指示器。
更新指标控制器
我们可以使用任何使用此服务的客户端(例如提供充足数据的 Apple iPhone 或 Android 手机)的指标来更新指标。通过利用此端点,我们可以使用额外的参数来扩充模式以提高精度。
在此过程结束时,我想说明一下完成所有这些步骤后您将获得的数据库中建议表的结果:
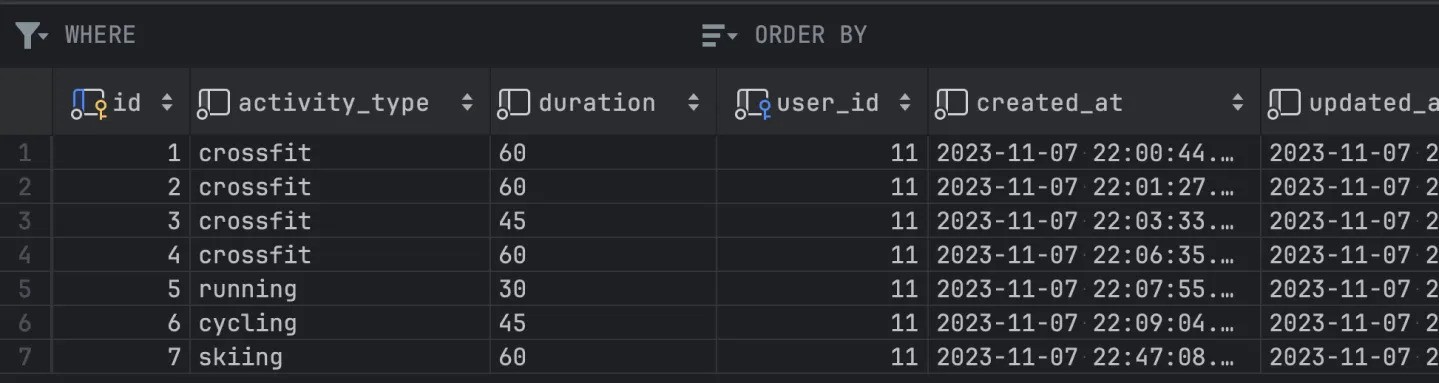
数据库中的建议结果
结论
总而言之,利用 OpenAI 提供体育活动建议提供了一个强大的解决方案,可以提高用户参与度并鼓励积极的生活方式。指标的细化在提高提示消息的清晰度和有效性方面具有巨大的潜力,为更加个性化和引人注目的用户体验铺平了道路。本文的核心是与 OpenAI API 通信、构建提示消息以及解析结果数据的关键概念。这些基本流程构成了我们应用程序的支柱,推动其生成定制体育活动建议并提供无缝用户体验的能力。
我相信您会发现这次旅程令人愉快且内容丰富。如果您有任何进一步的建议或疑问,请随时通过评论或其他平台与我联系。


