
什么是数据策略?
想象一下这种熟悉的情况: 作为公司的分析师, 你的任务是吸收组织的所有数据以收集独特而全面的见解。但这说起来容易做起来难。业务开发将他们的大部分数据分离到专有的 crm 解决方案中, 财务将其隐藏在电子表格中, 应用程序开发人员将 sdk 和 iot 数据流入独立的 prem 数据库, 而内置了容错能力。除此之外, 甚至从未考虑过合规和安全问题。似乎没有韵律, 也没有理由让一切都能运作, 不可能从所有的企业数据中获得统一的视图。而 “数据科学” 大多是通过对来自不同池的数据进行采样, 然后从任意采样的数据中进行 “裤子所在地” 的猜测来在组织周围进行的, 这种猜测既没有成效, 也不可靠。真是一团糟!
您需要为您的数据制定策略。你将如何做到这一点?您将收集哪些数据?您将存储哪些数据, 以及在哪里存储?谁是您的数据的受众群体?谁使用您分析的数据?您希望对数据具有何种访问控制和权限?
本博客将指导您在规划数据策略并开始考虑数据体系结构时, 了解需要探讨的各种问题。
但是, 首先, 什么是数据策略?
- 愿景和行动将朝着组织数据驱动的能力迈进。
- 组织如何获取、存储、吸收、控制、管理和使用数据的计划。
- 今天和明天的数据管道的路线图和功能列表。
- 制定该路线图的清单。
- 一组方法、过程和工具, 用于组织必须对数据执行的所有操作。
为什么您需要数据策略?
如果没有数据策略, 组织很可能会对其在组织内使用和应用数据感到临时和混乱, 从而缺乏对数据驱动功能的所有权和目的. 此外, 要可靠地整合来自多个源的数据, 以便从这些数据中获得一致、可重现和全面的见解, 也将更加困难。
数据策略使某些事情成为可能:
- 可以像资产一样管理和部署数据。
- 可以用最少的精力来使用、跟踪、分配和移动数据资产。
- 所有操作数据的过程和方法都是可重复、可靠和一致的。
- 解决了数据的法规遵从性和安全要求。
- 出现问题时, 有一种可预测的方法可用于识别和实现跨数据管道和数据资产本身所需的更改。
此外, 数据策略可能是由以下需求驱动的:
- 希望数据基础架构和功能能够在没有持续干预的情况下发挥作用并提供价值。
- 跨业务和 it 的愿景保持一致, 将数据作为一种资产进行利用。
- 定义整个组织和用户群的数据管理指标和成功标准。
- 推动盈利或至少零成本的数据管理工作
如果您的数据系统和过程无需不断扑灭火灾即可工作, 则可以专注于使用数据资产为您的业务增值。
基础知识
在开始开发数据策略时, 您会想问一些问题。让我们依次浏览每一个:
-
我希望我的数据通信 (或执行什么)?我希望我的数据管道 (或管道) 具体服务的目的是什么?我想收集哪些指标?我想要查找哪些相关性 (不同数据集之间的)?我还想从我的数据中获得哪些其他见解?作为此策略的一部分, 我希望执行哪些操作 (自动化或人工操作)?
-
谁是我的数据和/或数据管道的利益相关者?他们是客户吗?专业同行?高级管理层还是股东?还有谁?
-
我的数据管道是什么?它是支持业务中的函数 (或多个函数) 的管道吗?管道是数据驱动系统或服务的核心吗?管道本身是一种产品或服务吗?
-
数据管道是一个奇异的单向整体, 还是嵌套了许多双向管道 (例如核心到边缘系统)?是否有智能设备 (如传感器或响应式 ui) 为输入和输出提供组合手段?
-
我的数据基础架构还应该达到什么其他目的?例如, 我的管道只是中继数据, 还是从一个系统的输出输入到另一个系统, 就像机器学习培训的数据集一样?
收集数据
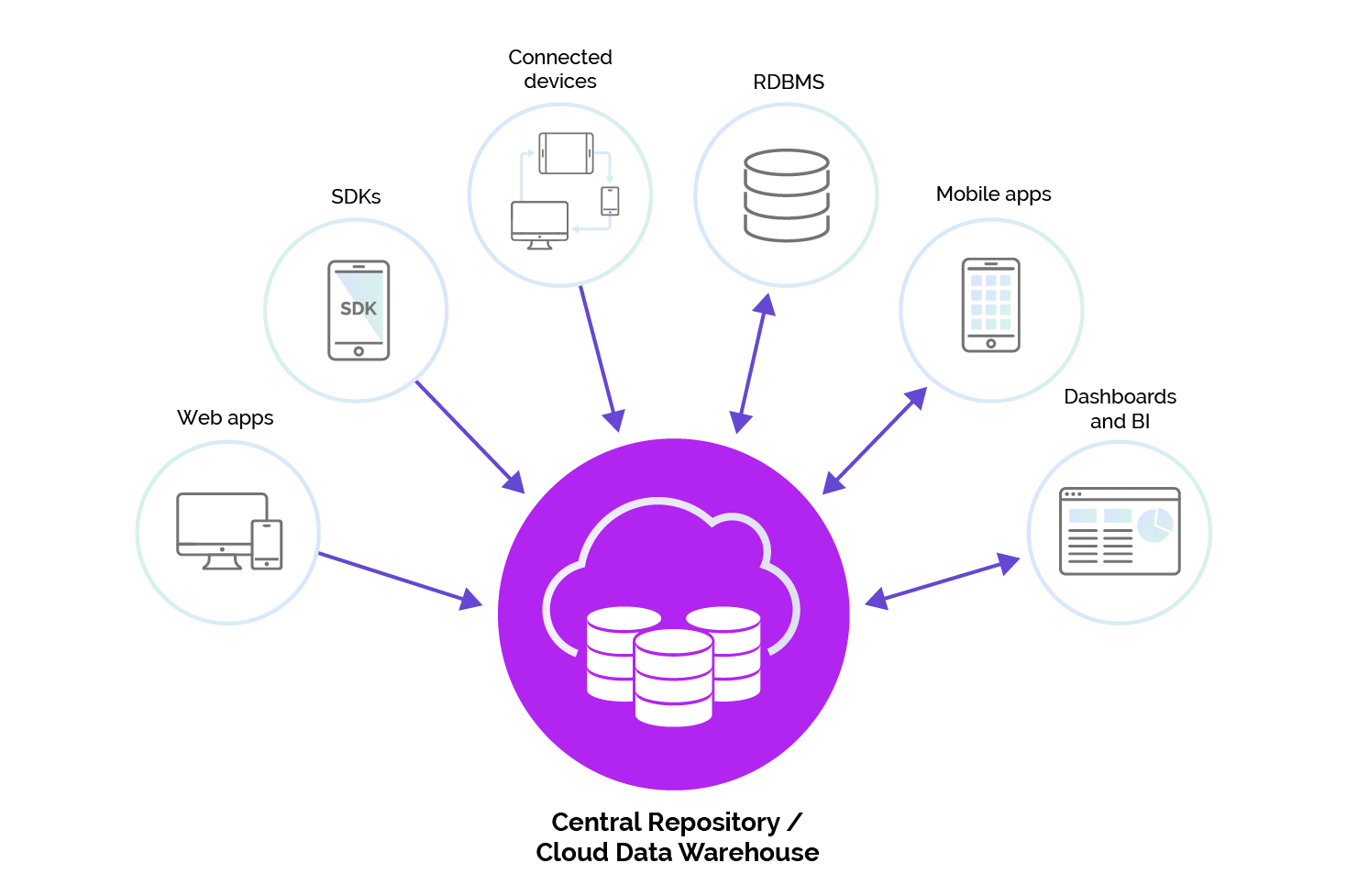
几乎所有数据基础架构的目标都是将许多不同系统的数据从一个全面的规范数据存储中提取, 以获得独特的见解和分析。以下是您可以询问的有关收集数据的一些问题。
我的数据是要实时、接近实时、批处理还是某种混合方法被接收?某些系统要求立即更新数据, 而另一些系统则可能容忍甚至需要一些延迟。
您将从何处以及如何收集数据?有许多潜在的数据源需要考虑, 其中包括:
- 软件 sdk (执行特定代码时触发的事件)。
- web 日志 (如通过速率单击、原始 ip 地址、时间戳等)。
- 传感器 (如物联网、能耗、制造系统或基础设施的传感器)。
- 智能设备, 如电视、仪表或安全系统。
- 事务性 rdbms。
- nosql 数据存储。
- 数据仓库。
- 集成平台, 如谷歌广告和谷歌分析。
- 企业系统 (如 erp、crm (例如 salesforce、splunk 或 Marketo)。
传输和加载数据
数据传输不仅涉及输入数据 (这类数据与收集数据有些重叠), 还涉及将数据从一个地方移动到另一个地方 (或不将数据移动)。如果您的数据管道不是单向的, 则在开发策略时可能需要考虑几种传输和加载方法。
您将如何加载数据?
- Sdk。
- 连接。
- 开源或 “专有” 日志收集器 (如 fluentd 或 Fluentd)。
- 散装装载机 (如浮雕)。
- 实时消息队列 (如 rabbitmq 或 zeromq)。
- – 亚结构 ( 如阿帕奇·普萨尔或阿帕奇卡夫卡 ) 。
存储和分析数据
考虑到未来数据量的增长速度将远远快于存储容量, 您可能还需要决定存储哪些数据以及哪些数据仍然是短暂的一些选项和注意事项:
- 云数据仓库。有许多可能性可供选择。您可以在此处查看条件。
- 用于架构刚性事务数据的 rdbms 系统。
- apache hadoop (使用 mapreduce 或 apache spark)。适用于在商品硬件上运行的非常大的数据集。hadoop 必须从磁盘读取并写入磁盘, 而 apache spark 可以在内存中工作得更快, 使用类似 sql 的方言来简化查询。
- 用于编写与分布式分类账相关的事件的结果一致的分布式数据库, 在该数据库中可以调整可用性和一致性之间的权衡。
- 列存储, 用于类似于酸的事务, 同时允许一定的架构灵活性。
- 时间序列数据库, 如 ffxdb, 针对物联网系统的大容量和高速度的时间戳数据进行了优化。
- 键值存储, 用于按键快速查找数据。
- 文档数据库, 如 mongodb, 用于快速查找架构松散、海量的数据。
- 一种文本搜索系统, 如 lucene 或 elasticsearch, 用于存储和查询非结构化、基于文本的数据。
- amazon s3 用于存储和访问写入平面文件、csv 或 json 的数据。s3 还允许您访问 amazon 的 ml 和 ai 功能。
- lambda 体系结构结合了多种存储方法来满足不同的数据要求 (例如, 用于对最近的数据进行快速查找的文档驱动数据库和用于历史数据慢速查找的 hadoop 群集)。
整合来自多个源的数据
要获得真正的见解, 您需要探索不同数据集之间的相关性, 这涉及到转换数据并将其合并到一个规范存储区。存储这些组合数据的位置在很大程度上取决于数据本身的要求, 正如我们在上面所研究的那样。aloma 是围绕着将数据从不同的数据源提取到一个规范数据存储中的想法构建的。
保护数据的安全
数据安全和合规性值得高度考虑, 尤其是在涉及个人识别信息 (pii) 的情况下。例如, 使用 pub-sub 机制的体系结构必须应对将所有事件写入不可变、有序事件日志的挑战, 同时根据用户的请求保持 pii 的安全性、最新性和可删除性, 并仅限于最低限度的必要。在写之前你会放弃所有的 pii 吗?对事件日志进行分区并保护不同的分区?或者根本不将包含 pii 的数据移动到您的系统中 (并远程运行查询)?为了安全并遵守 gdpr 等准则, 您可能需要在这些备选方案中进行选择。
输出数据
既然您已经摄入、处理和存储了数据, 接下来会发生什么?您的精细化数据是否适用于:
- 进一步分析?
- 历史趋势跟踪?
- 可视 化?
- 是否为后续系统转换为自动命令?
- 机器学习培训?
- 异常检测、k 近邻分析或类似检查?
根据其用途, 您的数据可能需要进行更多的优化、调整或目标架构更改。
使用数据浏览来了解数据集
数据浏览意味着测试不同的查询、sql 操作, 甚至仪表板可视化, 以验证不同的查询结果和输出。根据大多数帐户, 使用 d3. js/vega、r 或 python 等工具进行数据探索需要数据在两个维度或更大的数组 (或数据框) 中
所有流行的数据目标都支持这些阵列, 使数据探索技术和 bi 工具成为数据科学工具箱的日常组成部分。