
在本系列的第 1 部分中,我们研究了 MongoDB ,最可靠、最强大的面向文档的 NoSQL 数据库之一。在第 2 部分中,我们将研究另一个不可避免的 NoSQL 数据库:Elasticsearch。
Elasticsearch 不仅仅是一个流行且强大的开源分布式 NoSQL 数据库,Elasticsearch 首先是搜索和分析引擎。它构建在最著名的搜索引擎 Apache Lucene 之上Java库,能够对结构化和非结构化数据进行实时搜索和分析操作。它旨在有效地处理大量数据。
我们需要再次声明,这篇短文绝不是 Elasticsearch 教程。因此,强烈建议住院读者广泛使用官方文档以及 Madhusudhan Konda 所著的优秀书籍“Elasticsearch in Action”(Manning,2023 年),以了解有关产品架构和功能的更多信息。运营。在这里,我们只是重新实现与之前相同的用例,但这次使用 Elasticsearch 而不是 MongoDB。
所以,我们开始吧!
领域模型
下图显示了我们的*客户订单产品*域模型:
该图与第 1 部分中呈现的图相同。与 MongoDB 一样,Elasticsearch 也是一个文档数据存储,因此,它期望文档以 JSON 表示法。唯一的区别是,为了处理数据,Elasticsearch 需要对它们建立索引。
可以通过多种方式在 Elasticsearch 数据存储中对数据进行索引;例如,从关系数据库中传输它们、从文件系统中提取它们、从实时源流式传输它们等。但无论采用哪种提取方法,它最终都包括通过专用客户端调用 Elasticsearch RESTful API。此类专用客户分为两类:
- 基于 REST 的客户端,例如
curl、Postman、适用于 Java、JavaScript、Node.js 等的 HTTP 模块 - 编程语言 SDK(软件开发套件):Elasticsearch 为所有最常用的编程语言提供 SDK,包括但不限于 Java、Python 等。
使用 Elasticsearch 为新文档编制索引意味着使用针对名为 _doc 的特殊 RESTful API 端点的 POST 请求来创建该文档。例如,以下请求将创建一个新的 Elasticsearch 索引并在其中存储一个新的客户实例。
POST 客户/_doc/
{
“id”:10,
“名字”:“约翰”,
“姓氏”:“多伊”,
“电子邮件”: {
“地址”:“john.doe@gmail.com”,
“个人”:“约翰·多伊”,
“encodedPersonal”:“约翰·多伊”,
“类型”:“个人”,
“简单”:真实,
“组”:正确
},
“地址”:[
{
"street": "75, rue Véronique Coulon",
“城市”:“科斯特”,
“国家”:“法国”
},
{
“街道”:“Wulfweg 827”,
“城市”:“包岑”,
“国家”:“德国”
}
]
}使用 curl 或 Kibana 控制台(我们稍后会看到)运行上述请求将产生以下结果:
{
"_index": "客户",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
“_版本”:1,
“结果”:“创建”,
“_碎片”:{
“总计”:2,
“成功”:1、
“失败”:0
},
“_seq_no”:1,
“_primary_term”:1
}
这是对 POST 请求的 Elasticsearch 标准响应。它确认已创建名为 customers 的索引,并具有新的 customer 文档,由自动生成的 ID(在本例中为 ZEQsJI4BbwDzNcFB0ubC)标识。
其他有趣的参数出现在这里,例如_version,尤其是_shards。在不涉及太多细节的情况下,Elasticsearch 将索引创建为文档的逻辑集合。就像将纸质文档保存在文件柜中一样,Elasticsearch 将文档保存在索引中。每个索引都由分片组成,是物理的Apache Lucene 的实例,它是负责将数据移入或移出存储的幕后引擎。它们可能是主,存储文档,也可能是副本,顾名思义,存储主分片的副本。 Elasticsearch 文档中有更多相关内容 – 现在,我们需要注意名为 customers 的索引由两个分片组成:当然,其中一个是主分片。
最后注意:上面的 POST 请求没有提及 ID 值,因为它是自动生成的。虽然这可能是最常见的用例,但我们可以提供自己的 ID 值。在每种情况下,要使用的 HTTP 请求不再是 POST,而是 PUT。
回到我们的域模型图,如您所见,它的中心文档是 Order,存储在名为 Orders 的专用集合中。 Order 是 OrderItem 文档的聚合,每个文档都指向其关联的 Product。 Order 文档还引用下达该订单的 Customer。在 Java 中,其实现如下:
上面的代码显示了 Customer 类的片段。这是一个简单的 POJO(普通旧 Java 对象),具有客户 ID、名字和姓氏、电子邮件地址和一组邮政地址等属性。
现在让我们看一下 Order 文档。
在这里您可以注意到与 MongoDB 版本相比的一些差异。事实上,在 MongoDB 中,我们使用了对与此订单关联的客户实例的引用。 Elasticsearch 中不存在这种引用概念,因此,我们使用此文档 ID 在订单和下订单的客户之间创建关联。这同样适用于 orderItemSet 属性,它在订单与其项目之间创建关联。
我们的域模型的其余部分非常相似,并且基于相同的规范化思想。例如,OrderItem 文档:
这里,我们需要关联当前订单商品对象的产品。最后但并非最不重要的一点是,我们有 Product 文档:
数据存储库
Quarkus Panache 通过支持 活动记录和存储库设计模式。在第 1 部分中,我们使用 MongoDB 的 Quarkus Panache 扩展来实现我们的数据存储库,但目前还没有等效的 Elasticsearch Quarkus Panache 扩展。因此,在等待未来可能出现的 Elasticsearch Quarkus 扩展时,我们必须使用 Elasticsearch 专用客户端手动实现我们的数据存储库。
Elasticsearch 是用 Java 编写的,因此,它提供使用 Java 客户端库调用 Elasticsearch API 的本机支持也就不足为奇了。该库基于流畅的 API 构建器设计模式,并提供同步和异步处理模型。它至少需要 Java 8。
那么,我们基于 Fluent API 构建器的数据存储库是什么样的?下面是 CustomerServiceImpl 类的摘录,该类充当 Customer 文档的数据存储库。
@Path("客户")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
公共类 CustomerResourceImpl 实现 CustomerResource
{
@注入
客户服务 客户服务;
@覆盖
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) 抛出 IOException
{
返回 Response.accepted(customerService.doIndex(customer)).build();
}
@覆盖
公共响应 findCustomerById(String id) 抛出 IOException
{
返回 Response.ok().entity(customerService.getCustomer(id)).build();
}
@覆盖
公共响应 updateCustomer(客户客户)抛出 IOException
{
customerService.modifyCustomer(客户);
返回 Response.noContent().build();
}
@覆盖
公共响应deleteCustomerById(字符串id)抛出IOException
{
customerService.removeCustomerById(id);
返回 Response.noContent().build();
}
}这是客户的 REST API 实现。与订单、订单项目和产品相关的其他内容类似。
现在让我们看看如何运行和测试整个过程。
运行和测试我们的微服务
现在我们已经了解了实现的细节,让我们看看如何运行和测试它。我们选择代表 docker-compose 实用程序来执行此操作。这是关联的 docker-compose.yml 文件:
版本:“3.7”
服务:
弹性搜索:
图片:elasticsearch:8.12.2
环境:
节点名称:节点1
cluster.name:elasticsearch
discovery.type:单节点
bootstrap.memory_lock:“真”
xpack.security.enabled:“假”
路径.repo:/usr/share/elasticsearch/backups
ES_JAVA_OPTS:-Xms512m -Xmx512m
主机名:elasticsearch
容器名称:elasticsearch
端口:
- “9200:9200”
- “9300:9300”
u限制:
内存锁:
软:-1
困难:-1
卷:
- 节点1数据:/usr/share/elasticsearch/data
网络:
- 弹性搜索
基巴纳:
图片:docker.elastic.co/kibana/kibana:8.6.2
主机名:kibana
容器名称:kibana
环境:
-elasticsearch.url=http://elasticsearch:9200
-csp.strict=false
u限制:
内存锁:
软:-1
困难:-1
端口:
- 5601:5601
网络:
- 弹性搜索
依赖于取决于:
- 弹性搜索
链接:
- 弹性搜索:弹性搜索
文档库:
图片:quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
依赖于取决于:
- 弹性搜索
- 基巴纳
主机名:文档库
容器名称:文档库
链接:
- 弹性搜索:弹性搜索
- 基巴纳:基巴纳
端口:
- “8080:8080”
- “5005:5005”
网络:
- 弹性搜索
环境:
JAVA_DEBUG:“正确”
JAVA_APP_DIR:/home/jboss
JAVA_APP_JAR:quarkus-run.jar
卷:
节点1数据:
司机:本地
网络:
弹性搜索:
此文件指示 docker-compose 实用程序运行三个服务:
- 名为
elasticsearch的服务,运行 Elasticsearch 8.6.2 数据库 - 名为
kibana的服务,运行多用途 Web 控制台,提供不同的选项,例如执行查询、创建聚合以及开发仪表板和图表 - 名为
docstore的服务,运行我们的 Quarkus 微服务
现在,您可以检查所有必需的进程是否正在运行:
$ docker ps
容器 ID 图像命令创建状态端口名称
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3天前 3天前 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp 文档库
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 天前 Up 3 天 0.0.0.0:5601->5601/tcp, :::5601-> 5601/TCP 基巴纳
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 天前 3 天 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0: 9300->9300/tcp,:::9300->9300/tcp
$
要确认 Elasticsearch 服务器可用并且能够运行查询,您可以通过 http://localhost:601 连接到 Kibana。向下滚动页面并在首选项菜单中选择开发工具后,您可以运行查询,如下所示:
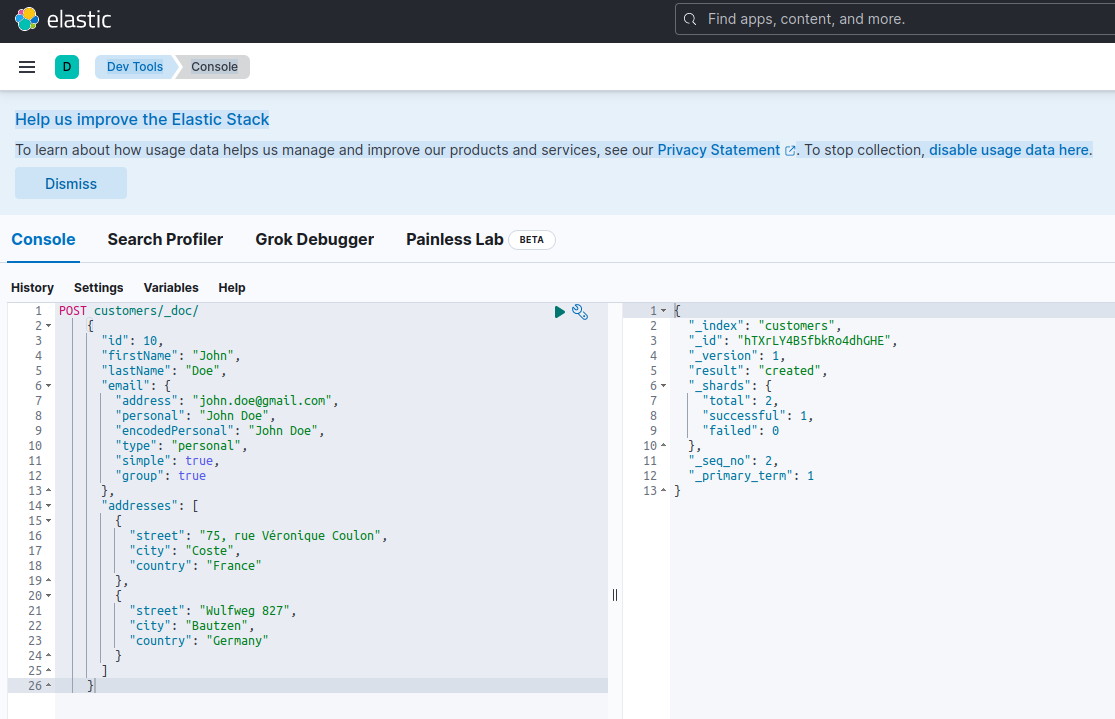
为了测试微服务,请按以下步骤操作:
1.克隆关联的 GitHub 存储库:
$ git 克隆 https://github.com/nicolasduminil/docstore.git2.进入项目:
$ cd 文档库3.检查正确的分支:
$ git checkout elastic-search4.构建:
$ mvn clean install5.运行集成测试:
$ mvn -DskipTests=false failuresafe:integration-test最后一条命令将运行提供的 17 个集成测试,这些测试应该都会成功。您还可以通过在 http://localhost:8080/q:swagger-ui 上触发您的首选浏览器来使用 Swagger UI 界面进行测试。然后,为了测试端点,您可以使用位于 docstore-api 项目的 src/resources/data 目录中的 JSON 文件中的负载。
享受吧!


