
我们都知道线性回归例程是非常简单和易于理解的。如果它明确指出一个独立变量的值增加 1点, 则因变量增加 b 单位。
但是, 当涉及到预测离散变量 (例如, 客户是否会留在服务提供商, 或者是否会下雨) 时, 逻辑回归将发挥作用。没有很多不同的值, 结果只能是1或0。
在本文中, 我们将学习如何在 excel 中构建一个简单的客户流失模型, 我们将使用规划求解通过减少交叉熵误差来优化该模型。
在我们进入逻辑回归的细节之前, 让我们了解为什么当我们必须根据线性回归的以下限制预测离散结果时, 线性回归将不起作用:
- 线性回归假定每个变量之间存在线性关系。但是, 如果与竞争对手相比, 客户为特定服务支付的费用较低, 则客户离开服务提供商的可能性将呈指数级差异。
- 线性回归假定概率随自变量的增加而按比例增加。
解决方案: 救援的 sigmoid 曲线
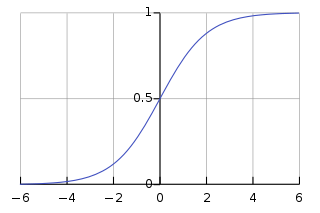
如上所述, 线性回归的主要问题是它假定变量之间的线性关系, 这在实践中是非常罕见的。
为了解决这个 (和其他几个) 限制问题, 我们将探索乙状结肠曲线。在外行的语言中, 我们可以说 sigmoid 函数 (曲线) 有助于返回概率值, 然后将概率值映射到两个或多个离散类。而在一般情况下, 线性回归并不告诉我们事件发生在一定范围后的概率。
基于上述解释, 我们可以说, sigmoid 曲线比线性回归更好地解释离散现象。
为了简单起见, 我将继续讨论本文的核心主题, 即如何使用逻辑回归来留住客户。为此, 我们将努力了解逻辑回归, 并了解如何实现它。
我们知道, 线性回归假定因变量和自变量之间的线性关系。它表示为 y = x + b * x. 逻辑回归通过应用 sigmoid 曲线偏离了线性关系的概念。
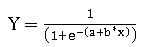
上述表示法清楚地显示了逻辑回归如何使用自变量, 这与线性回归相同。但是, 同时, 它还通过 sigmoid 激活传递这些变量, 以将输出绑定到0或1之间。
现在, 要查看逻辑回归中的输出是如何变化的, 让我们通过一个示例来查看逻辑回归方程的引擎盖下:
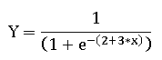
- 如果 x = 0, 则 y = 1/(1 + exp (-(2))) = 0.88
- 如果 x 增加2个单位 (即, x = 2), 则 y 的值为 y = 1/(1 + exp (-+ exp (-(-+ 3 * 2))) = 1/(1+exp(-(5)) = 0.9 93
当 x 从0更改为2时, y 的值从0.88 更改为0.88 是相当清楚的。同样, 如果 x 为-2, y 将为0.017。因此, x 中的单位更改对 y 的影响取决于方程。当 x = 0时的值0.88 可以解释为概率。例如, 在88% 的情况下, 当 x = 0时, y 的值为1。
逻辑回归在行动
为了看到上面的方程和例程的作用, 我们将在 excel 中进行建立逻辑回归方程的练习
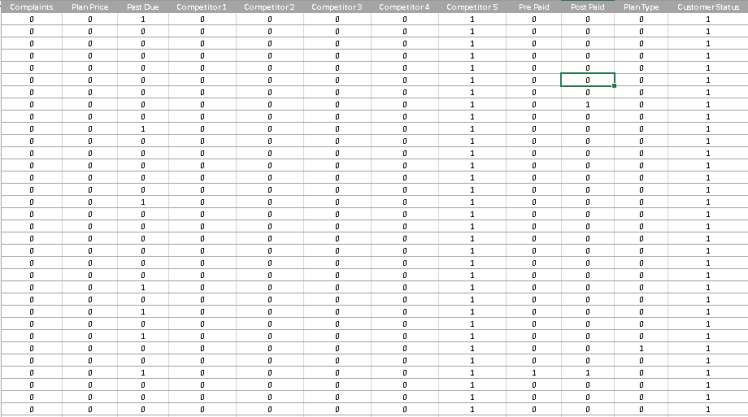
要遵循的步骤
- 将自变量的权重初始化为随机值 (让我们假设每个随机值 1个)。
- 一旦权重和偏差初始化, 我们将通过在自变量的多元线性回归上应用 sigmoid 激活来估计输出值 (客户离开 = 1 或停留 =-0 的概率)。
下表包含有关 sigmoid 曲线的 (a + b * x) 部分和最终 sigmoid 激活值的信息:
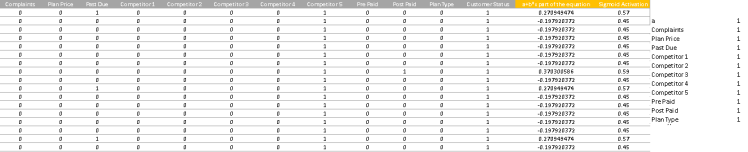
获得上表中的值的公式见下表:
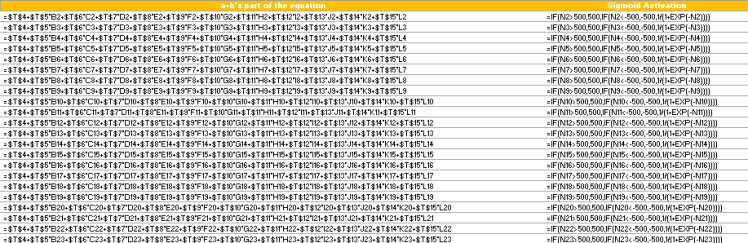
使用前一个 sigmoid 激活 col 中的 if 条件只是因为 excel 在计算任何值 > exp 500 时存在限制, 因此会进行裁剪。
误差估计
在线性回归中, 我们考虑实际值和预测值之间的最小二乘 (平方差) 来估计总体误差。在逻辑回归中, 我们将使用一个不同的误差度量, 称为交叉熵。
交叉熵是衡量两种不同分布之间差异的指标–实际分布和预测分布。
让我们来看看因变量 (客户流失) 为1的情况下的两个成本函数 (最小二乘法和熵成本):
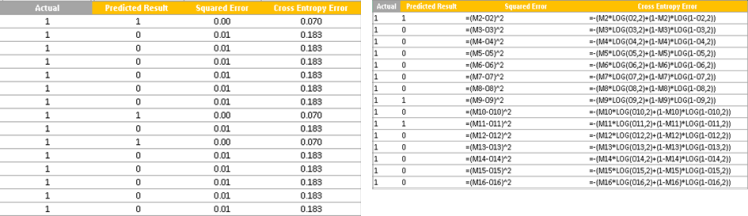
上表清楚地表明, 与平方误差相比, 交叉熵方法对高预测误差的惩罚很大: 较低的误差值在平方误差和交叉熵误差上都有类似的损失, 但在有较高差异的地方,交叉熵沉重地惩罚。因此, 在预测离散变量时, 坚持将交叉熵误差作为误差度量是一个好主意。
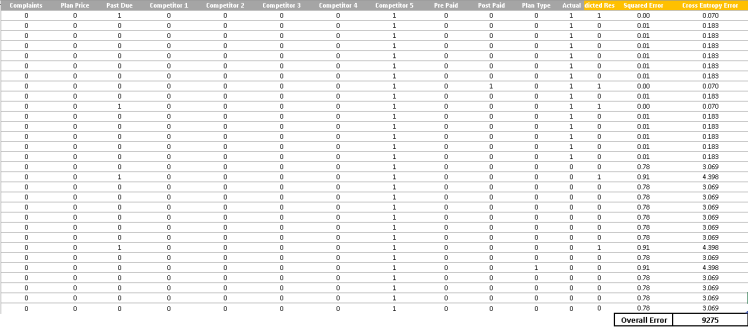
现在我们已经设置了问题, 让我们改变参数, 从而减少整体误差。此步骤可以通过渐变下降来执行, 这可以通过在 excel 中使用规划求解功能来完成。
注意: 为了提高模型性能并减少错误, 最好只引入那些具有统计意义的变量。对于此活动, 可以遵循本文范围之外的不同方法。