
开放表格式是专为在分布式数据处理系统。它们通过以下功能简化数据存储:
- 用于分析工作负载的列式存储
- 压缩可降低存储成本并提高性能
- 架构演化以适应不断变化的数据结构
- ACID 合规性,确保数据完整性
- 支持事务操作
- 历史数据查询的时间旅行功能
- 与各种数据处理框架和生态系统无缝集成
这些特性共同支持构建可扩展、可靠且高效的数据处理管道,使开放表格式成为当代数据架构和分析工作流程中的首选。
让我们深入研究开放表格式 Apache Iceberg、Apachi Hudi 和 Delta Lake。
阿帕奇冰山
Apache Iceberg是一种专为大规模设计的开源表格格式=”https://dzone.com/articles/data-lakes-all-you-need-to-know”>数据湖,旨在提高数据可靠性、性能和可扩展性。其架构引入了几个关键组件和概念,可解决与大数据处理和分析相关的常见挑战,例如管理大型数据集、模式演变、高效查询和确保事务完整性。下面深入探讨 Apache Iceberg 的核心组件和架构设计:

图 1:Apache Iceberg 架构(来源:Dremio)
1。表格格式和元数据管理
版本化元数据
Iceberg 使用版本化元数据管理系统,其中表上的每个操作都会创建表元数据的新快照。这种方法确保原子性和一致性,支持 ACID 事务,无论更改是否完全应用。
快照管理
每个快照都包含完整的表元数据,包括架构信息、分区详细信息和文件列表。快照支持时间旅行功能,允许用户查询任意时间点的数据。
元数据文件
元数据以 JSON 格式存储,使其易于读取和访问。轻量级元数据文件的使用还简化了架构演变和分区更改等操作,因为这些操作只需要元数据更新,而不会影响实际数据。
2.文件组织和分区
分区
Iceberg 引入了灵活的分区系统,支持分区演进。分区在表元数据中定义,允许随着时间的推移进行更改,而无需重写数据。这显着降低了管理不断变化的数据集的复杂性。
文件布局
数据被组织成存储在对象存储中的文件。 Iceberg 支持多种文件格式,包括 Parquet、Avro 和 ORC。文件被分组为“清单”,以进行有效的元数据管理。
隐藏分区
Iceberg 的分区是逻辑分区,与物理存储分离,支持谓词下推等优化,以实现高效的数据访问,而无需昂贵的目录遍历。
3.可扩展性和性能
增量处理
Iceberg 表专为高效的增量数据处理而设计。通过跟踪快照中的添加和删除,Iceberg 使消费者能够仅处理快照之间的更改,从而减少要扫描的数据量。
可扩展的元数据操作
该架构旨在扩展元数据操作,从而可以高效处理大型数据集。使用紧凑的元数据文件和清单列表有助于管理大量数据集,而不会降低性能。
4。查询引擎集成
广泛的生态系统支持
Iceberg 旨在与各种查询引擎和数据处理框架无缝集成,包括 Apache Spark、Trino、Flink 和 Hive。这是通过定义良好的 API 实现的,该 API 允许这些引擎利用 Iceberg 的功能,例如快照隔离、模式演化和高效文件修剪。
5。事务支持和并发
ACID 事务
Iceberg提供ACID事务来保证数据完整性,支持并发读写。乐观并发模型允许多个操作并行进行,并通过冲突检测和解决机制来保持一致性。
6。架构演变和兼容性
架构演变
Iceberg 支持添加、重命名、删除和更新列,同时保持向后和向前兼容性。这允许在不停机或数据迁移的情况下进行架构更改。
<小时/>
Apache Iceberg 的架构旨在通过提供可靠的 ACID 事务、高效的元数据管理和可扩展的数据处理功能来解决传统数据湖的局限性。其灵活的分区、版本化元数据以及与流行查询引擎的集成使其成为管理各种用例(从分析工作负载到实时流)中的大规模数据湖的强大解决方案。
阿帕奇胡迪
Apache Hudi(Hadoop Upserts、删除和增量的缩写)是一个开源数据管理框架用于简化 HDFS、S3 或云原生数据服务等数据湖之上的增量数据处理和数据管道开发。 Hudi 将流处理引入大数据,提供新鲜数据,同时高效存储大型数据集。以下是对 Apache Hudi 的架构和核心组件的深入探讨:
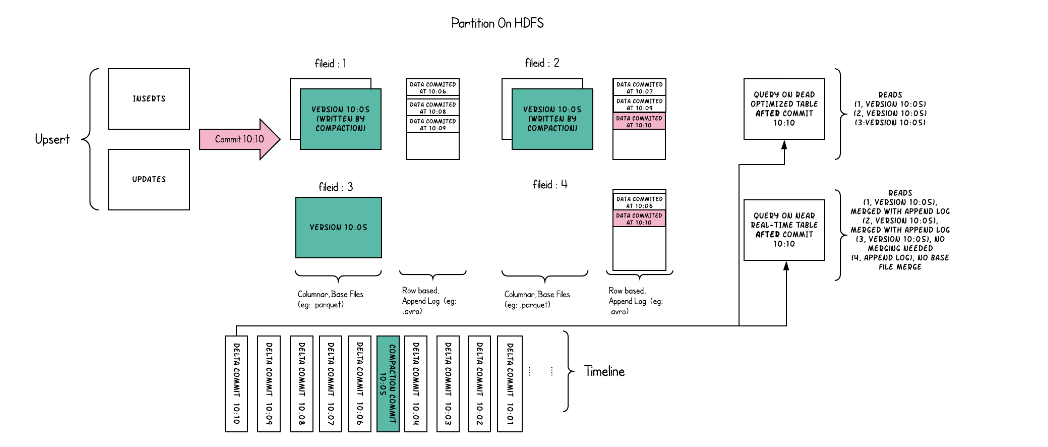
图 2:Apache Hudi 架构 (来源)
1。核心概念
表类型
Hudi 支持两种类型的表:写入时复制 (CoW) 和读取时合并 (MoR)。 CoW 表针对读取密集型工作负载进行了优化,具有更简单的写入模式,其中每个写入操作都会创建一个新版本的文件。 MoR 表通过频繁的读写支持更复杂的工作负载,以列式(为了高效读取)和基于行的格式(为了高效更新插入)的组合存储数据。
记录密钥和分区
Hudi 表通过记录键进行索引,数据根据分区路径分区到文件系统上的目录中。此结构可实现高效的更新插入(更新和插入)和删除。
2.数据存储和管理
文件大小管理
Hudi 自动管理文件大小和布局以优化读写性能。它压缩小文件并将数据组织成更大的文件以提高效率。
索引
Hudi 维护索引以快速定位要更新或删除的记录,从而显着减少此类操作期间需要扫描的数据量。
MoR 表的日志文件
在读取表合并中,Hudi 使用日志文件有效地存储传入写入(更新插入和删除)。这允许更快的写入,将数据合并到列式文件中,直到读取或压缩时间为止。
3.事务和并发
ACID 事务
Hudi 为读取和写入提供快照隔离,从而启用事务。即使存在并发操作,这也可以确保数据的完整性和一致性。
乐观并发控制
Hudi 采用乐观并发控制来管理并发写入。它通过重试或失败操作来解决冲突,具体取决于冲突解决策略。
4。增量处理
变更捕获和增量拉取
Hudi 支持在记录级别捕获数据更改,从而实现高效的增量数据处理。应用程序可以查询特定时间点的数据更改,从而减少要处理的数据量。
5。查询引擎集成
广泛的兼容性
Hudi 与 Apache Spark、Apache Flink、Presto 和 Hive 等流行查询引擎集成。这允许用户使用熟悉的工具和 API 查询 Hudi 表。
6。可扩展性和性能
可扩展的元数据管理
Hudi 旨在通过有效管理元数据来处理大型数据集。它利用紧凑的序列化元数据格式和可扩展的索引机制来保持性能。
数据压缩
对于读取表合并,Hudi 将日志文件后台压缩为列格式,优化读取性能而不影响正在进行的写入。
7。数据管理功能
时间旅行
Hudi 支持查询特定时间点的数据,实现时间旅行查询以进行审计或回滚目的。
架构演变
Hudi 可以优雅地处理架构更改,允许在不中断数据处理的情况下添加、删除和修改表架构。
<小时/>
Apache Hudi 的架构旨在通过提供高效的更新插入、删除和增量处理功能来解决管理大规模数据湖的复杂性。它与流行的大数据处理框架的集成、ACID 事务支持以及读写性能的优化使其成为构建高吞吐量、可扩展数据管道的强大工具。 Hudi 的数据管理方法可实现更快的数据刷新并简化对迟到数据的处理,使其成为现代数据架构中实时分析和数据处理的重要组成部分。
Delta Lake 架构
Delta Lake 是一个开源存储层,可为 Apache Spark 和大数据工作负载带来 ACID 事务,旨在提供更可靠、更高性能的数据湖。 Delta Lake 使用户能够构建强大的数据管道,能够抵御故障、支持并发读取和写入,并允许复杂的数据转换和分析。下面深入探讨 Delta Lake 的核心组件和架构设计:
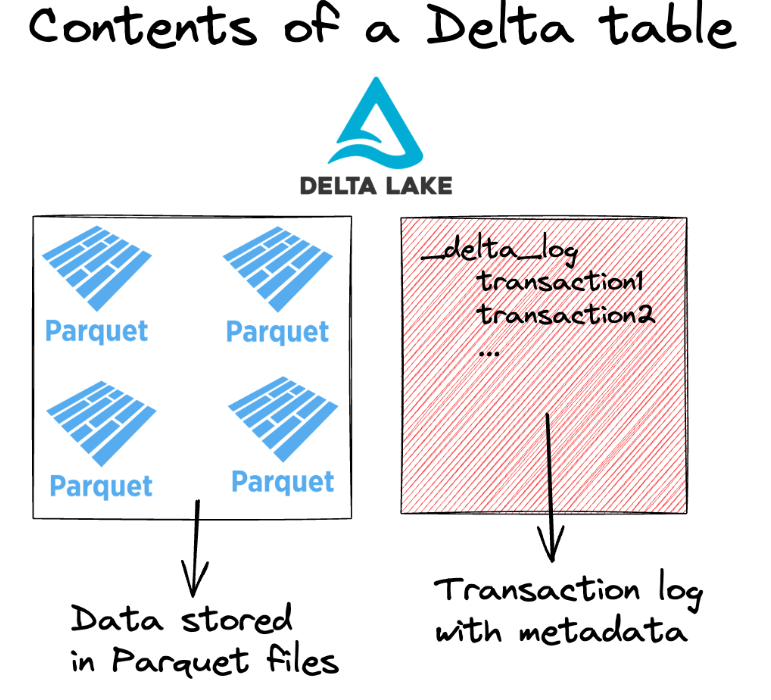
图 3:Delta 表(来源:Delta Lake 文档)
1。核心概念和组件
ACID 事务
Delta Lake 通过实施 ACID 事务来确保读写过程中的数据完整性和一致性。这是通过对数据进行原子操作来实现的,这些操作记录在事务日志中,确保每个操作要么完全完成,要么根本不发生。
增量表
Delta 表是带有事务日志的版本化镶木地板表。事务日志记录了对表所做的每次更改,用于确保一致性并启用时间旅行等功能。
架构实施和演变
Delta Lake 对写入操作强制执行架构验证,防止不良数据导致数据损坏。它还支持架构演变,允许添加新列和更改表架构,而不会破坏现有查询。
2.交易日志
事务日志(通常称为 Delta Log)是 Delta Lake 架构的关键组成部分。它包含跟踪表更改的 JSON 文件,包括有关提交、按顺序保存和不可变日志条目的信息。此日志允许 Delta Lake :
- 维护时间线:跟踪表的所有事务和修改,支持原子性和一致性。
- 支持时间旅行:查询以前版本的表,实现数据回滚和审计。
- 启用并发:使用乐观并发控制有效管理并发读写。
3.数据存储和管理
镶木地板文件
Delta Lake 利用其高效的列式存储格式将数据存储在 Parquet 文件中。 Parquet 文件是不可变的,修改会创建文件的新版本,然后通过事务日志进行跟踪。
文件管理
Delta Lake 通过压缩小文件并将其合并为大文件来优化文件存储,以提高读取性能。它还支持分区以增强查询性能。
4。可扩展性和性能
优化布局
Delta Lake 使用 Z 排序和数据跳跃来优化磁盘上数据的布局,从而显着减少查询扫描的数据量。
流式处理和批处理
在同一管道中无缝集成流式处理和批量数据处理,确保数据在所有操作中都是最新且一致的。
5。高级数据操作
更新插入、删除和合并
Delta Lake 支持更新插入 (MERGE INTO)、删除和合并等高级数据操作,通过简化复杂的转换和更新,使管理和维护数据湖变得更加容易。
增量处理
Delta Lake 允许对数据更改进行高效的增量处理,从而能够构建复杂的 ETL 管道,该管道只能处理自上次操作以来发生更改的数据。
6。与数据生态系统集成
Delta Lake 与 Apache Spark 深度集成,其 API 旨在与 Spark DataFrames 无缝使用。这种紧密集成可实现高性能数据转换和分析。此外,Delta Lake 还可以与其他数据处理和查询引擎结合使用,增强其在多工具数据架构中的多功能性。
Delta Lake 的架构解决了处理大数据的数据工程师和科学家面临的许多挑战,例如确保数据完整性、支持复杂事务以及优化查询性能。通过提供 ACID 事务、可扩展的元数据处理和强大的数据管理功能,Delta Lake 可实现更可靠、更高效的数据管道,使其成为现代数据平台的基础组件。
Iceberg、Hudi 和 Delta Lake 之间的比较表
| 功能 | 阿帕奇冰山 | Apache Hudi | 三角洲湖 |
|---|---|---|---|
| 基础 | 针对大型分析数据集的开放表格格式 | 用于增量处理的数据管理框架 | 带来ACID事务的存储层 |
| 主要用例 | 提高数据湖中的数据可靠性、性能和可扩展性 | 简化数据湖上的数据管道开发 | 使大数据工作负载更加可靠和高性能 |
| 数据结构 | 具有版本化元数据的表格格式 | 支持写入时复制 (CoW) 和读取时合并 (MoR) 表 | 带有事务日志的版本化 Parquet 表 |
| 架构演变 | 支持添加、重命名、删除和更新列 | 处理架构更改,允许添加、删除和修改 | 强制架构验证并支持演化 |
| 分区 | 具有分区演变的灵活分区系统 | 按记录键索引,分区为目录 | 支持分区,通过 Z 排序进行优化 |
| ACID 事务 | 是的,具有原子操作和快照隔离 | 是的,它为读写提供快照隔离 | 是的,它确保读取和写入时的数据完整性 |
| 并发和冲突解决 | 乐观并发模型 | 带冲突解决的乐观并发控制 | 有效管理并发读写 |
| 增量处理 | 专为高效增量数据处理而设计 | 捕获记录级别的更改,以实现高效的增量拉动 | 允许增量处理数据更改 |
| 时间旅行 | 快照管理,任意时间点查询数据 | 快照管理,任意时间点查询数据 | 数据回滚和审计的时间旅行 |
| 文件格式 | 支持 Parquet、Avro、ORC 等多种格式 | 管理文件大小和布局,压缩以提高效率 | 将数据存储在 Parquet 文件中,优化文件管理 |
| 查询引擎集成 | 广泛支持(例如 Apache Spark、Trino、Flink) | 兼容 Spark、Flink、Presto 等流行查询引擎 | 与 Apache Spark 深度集成 |
| 性能优化 | 大型数据集的元数据管理,隐藏分区 | 可扩展的元数据和索引、文件大小管理 | 通过 Z 排序、数据跳过优化布局 |
| 操作功能 | 支持更新插入、删除和架构演变,对性能的影响最小 | 高级数据操作,如更新插入、删除、合并 | 高级操作,如更新插入、删除、合并 |