

面临法规和激烈竞争挑战的金融服务机构每天完成数百万笔交易。
正在利用先进的 IT 工具来降低财务风险;使用由不断增长的数据量馈送的算法,在交易时快速实现明智的决策和风险缓解。但分析的有效性完全取决于性能和速度。
通过更高效地处理大量数据来加速和丰富洞察,金融机构可以创造竞争优势。他们的决定更加客观、知情和及时,这意味着他们也可以更有利可图。
您可能还喜欢:实时流处理与阿帕奇卡夫卡第一部分。
大数据瓶颈
有几个因素会减慢分析速度。有大量不同类型的数据,包括交易数据、客户数据、网络日志、研究、出版物、市场数据以及通过社交媒体传达的公众情绪。数据定义和实现不一致会使数据聚合过程复杂化。某些数据仓库会预先聚合数据以提供固定视图,并且可能需要再次聚合这些数据以提供完整的风险分析。
此外,系统之间的不同网络跃点也会减慢处理时间,如下图所示:
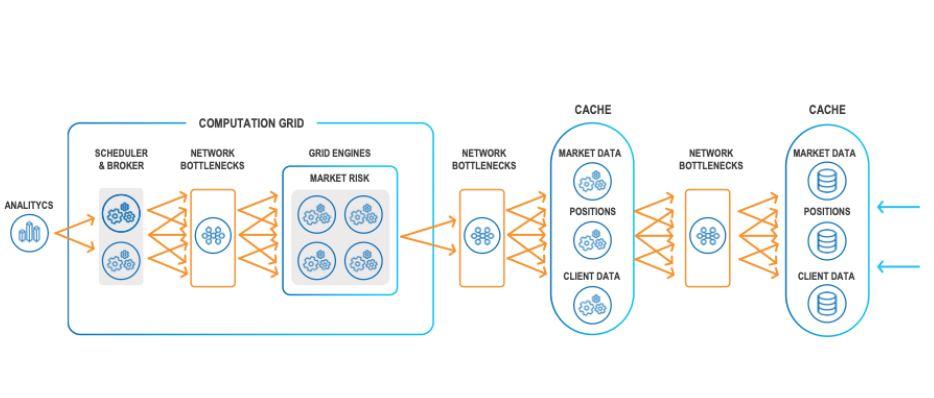
统一的数据层可以克服这些挑战,在近乎实时的时间内减少计算和检索时间。拥有一个数据层,支持数据湖或数据仓库(Hadoop 或云存储)中存档数据的推送和拉取功能,可提供连续和按需的见解。
实时洞察解决方案
通常,数据存储在速度层(使用传统的快速数据库或 IMDG)和存储存档数据的批处理层中,如HDFS或S3。数据可以流式传输到两个层中,速度层会保存最近数据的滑动窗口,例如,最近 24 小时或几天。然后,用户可以根据业务需求查询相应的层,并在需要时独立查询这两个层并合并查询结果。
此体系结构的警告包括:
- 速度和批处理层的生命周期管理。
- 需要复杂的查询。
- 多个产品的多个代码库。
- 每个组件的高可用性
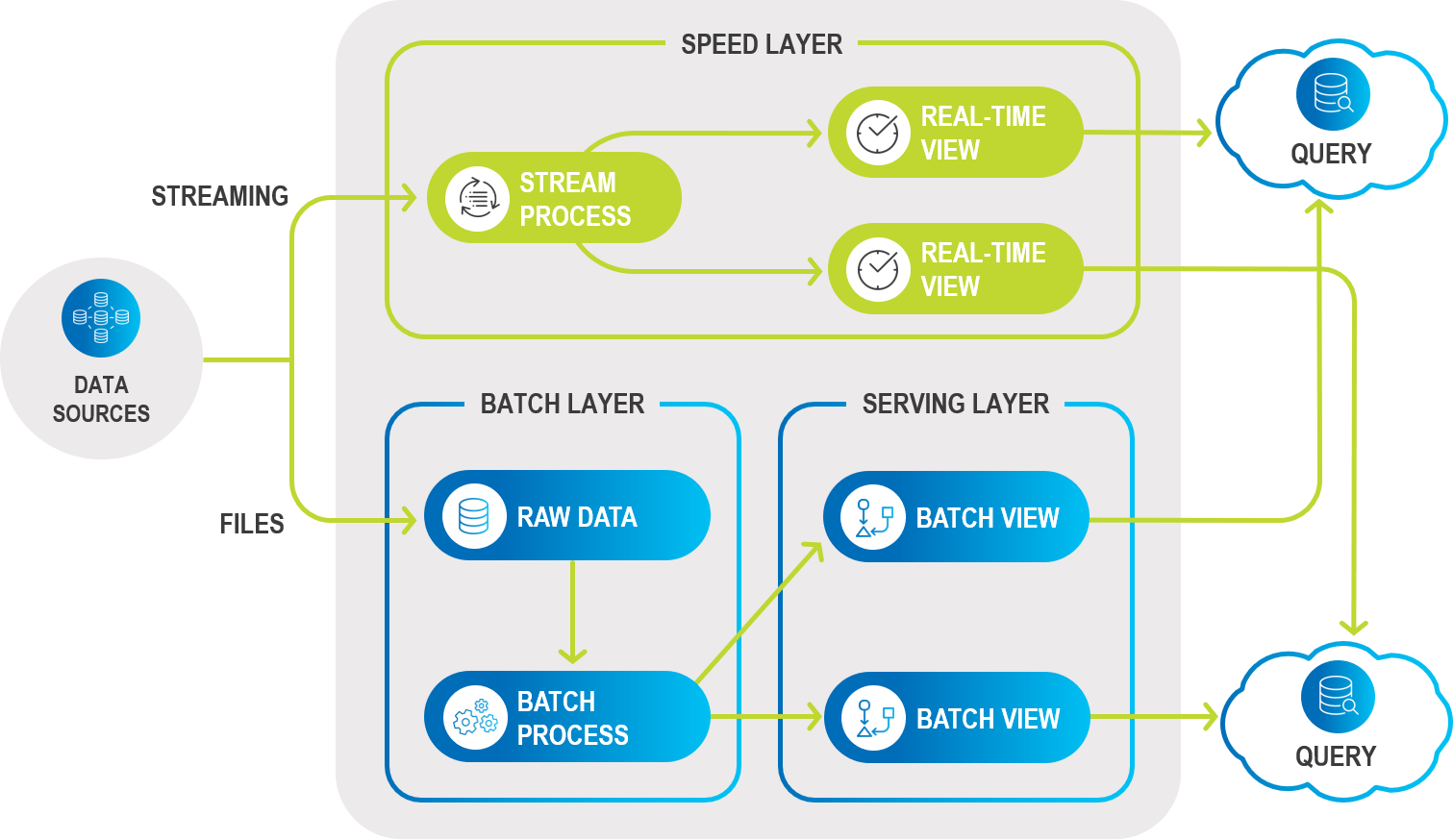
通过直接引入数据,或者从选定的消息代理引入统一数据层,并使用统一 API 从单个平台自动管理数据层(上游和下游),可以大大简化和加速此过程。
下面的代码显示交易数据如何自动加载到您的历史批处理层,每个日期。在这种情况下,2018 年前的数据被视为历史数据或非操作数据。
可以自定义将数据加载到历史层(Hadoop、S3)的业务策略。例如,高交易的股票可以存储在操作速度层比其他股票长。
|
lambda.policy.trade.class=策略。阈值存档策略 |
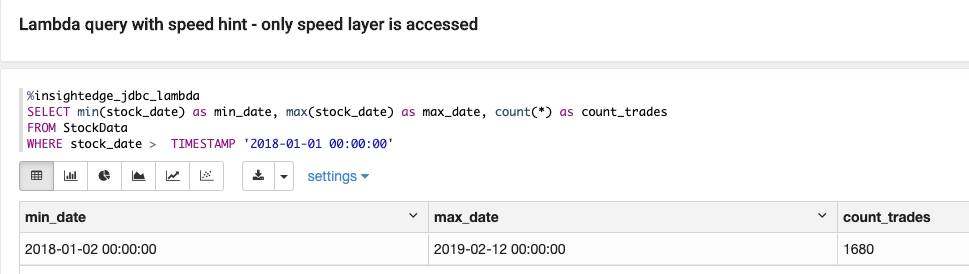
即使定义的数据已移动到外部数据存储,它完全可用于通过统一 API 进行查询、分析和模拟,该 API 也将访问操作层。如果查询仅与操作速度层上的数据相关,则根本不访问批处理层。例如,可以使用”最近 90 天”参数来查找 RAM 和 SSD 上的数据,因此可以在 37 毫秒内提取数据,而无需访问批处理层。

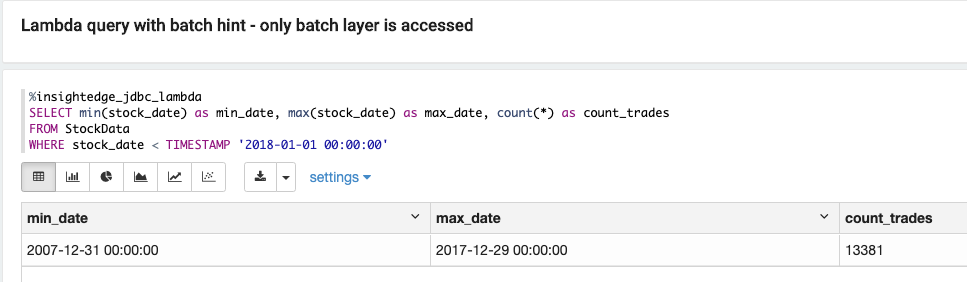
如果查询的数据超过 90 天,则可以在 1,545 毫秒内从批处理层提取数据,而无需访问速度层。

在此示例中,从速度和批处理图层在 1,530 毫秒内获取早于 90 天或小于 90 天的数据
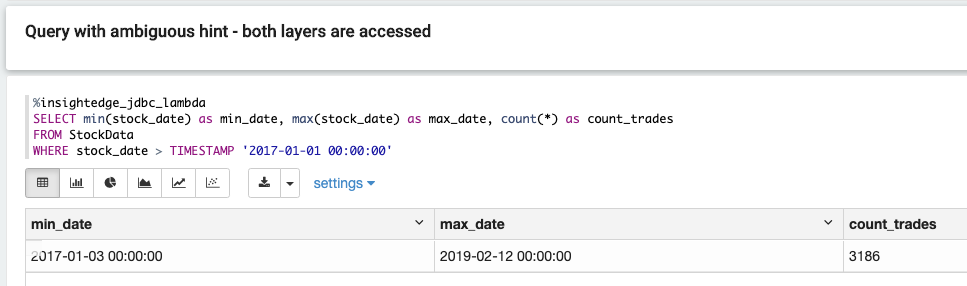

来自多个来源的数据(如交易、头寸、市场数据和衍生品(外汇、利率、股票))通过Kafka和ETL工具流式传输到单个平台。使用定义的业务策略,此数据在 RAM、持久内存、SSD 和外部数据存储技术之间智能分层。从引入数据的那一刻起,它立即可用于连续和按需查询、交互式报告和模拟。
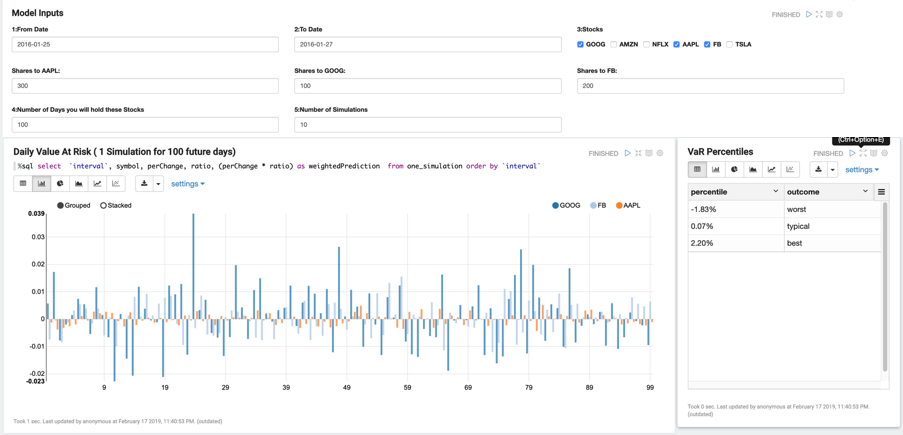
一个明显的好处是,无论数据位于何处,无论数据位于何处,均可从单个 API 检索和运行高级分析和 ML,无论数据位于何处 — RAM、SSD、持久内存,还是历史层(Hadoop、AWS S3、Azure Blob 存储等)。第二个好处是速度。
加快分析,做出更明智的交易决策,对交易分析师来说,成功与失败是分不一分的。拥有统一的数据层可以提供对流数据和热数据的必要访问,以及以银行创建和维护竞争优势的速度快速访问历史数据,从而将风险降至最低并提高交易决策的盈利能力。