

在本文中,我将对深度学习的基础知识进行非常简单的介绍,而不管您以后可以选择何种语言、库或框架。
介绍
试图用良好的理解水平来解释深度学习可能需要相当长的时间,所以这不是本文的目的。
目的是帮助初学者了解这个领域的基本概念。然而,即使是专家也可能在以下内容中找到一些有用的东西。
冒着极其简单的风险(请原谅我的专家),我会尽量给你一些基本的信息。如果没有别的,这可能只是触发一种意愿,更深入地研究这个主题,为你们中的一些人。
您可能还喜欢:
深度学习和机器学习指南(第 1 部分)
一些历史
深度学习本质上是一个新潮的名字,一个主题已经存在了相当长一段时间,在神经网络的名称下。
当我在90年代早期开始研究(和热爱)这个领域时,这个学科已经广为人知了。事实上,第一步是在20世纪40年代(麦卡洛奇和皮特斯),但自那时以来,这方面的进展一直相当起伏,直到现在。该领域取得了巨大成功,在智能手机、汽车和许多其他设备上进行了深度学习。
那么,什么是神经网络,你能用它做什么?
好的,让我们暂时关注一下计算机科学的经典方法:程序员设计了一个算法,该算法对于给定的输入生成输出。
他或她准确地设计了函数 f(x) 的所有逻辑,以便:
y = f(x)
其中 x 和 y 分别是输入和输出。
但是,有时设计 f(x) 可能不是那么容易。例如,假设 x 是人脸的图像,y 是对应人员的姓名。这项任务对于自然大脑来说是如此难以置信地容易,而计算机算法很难执行!
这就是深度学习和神经网络发挥作用的地方。基本原则是:停止尝试设计f()算法,并尝试模仿大脑。
那么大脑如何活动呢?它使用几个几乎无限的(x,y)样本(训练集)来训练自己,在整个一步一步的过程中,f(x)函数会自动塑造自身。它不是由任何人设计的,只是从无休止的反复试验的精炼机制中浮现出来。
想想一个孩子每天看着身边熟悉的人:数十亿张快照,从不同的位置、视角、光线条件拍摄,每次进行关联,每次纠正和锐化自然神经网络下面。
人工神经网络是大脑中由神经元和突触组成的自然神经网络的模型。
典型的神经网络架构
为了保持简单(并与今天的机器的数学和计算能力生存),神经网络可以设计为一组层,每个层包含节点(大脑神经元的人工对应),其中每个图层中的节点连接到下一层中的每个节点cheeli.com.cn/wp-content/uploads/2019/09/Selection_031-256×300.png”宽度=”335″/*
每个节点都有一个状态,由两个限制(通常为 0 和 1)之间的浮动数字表示。当此状态接近其最小值时,该节点将被视为非活动(关闭),而当它接近最大值时,该节点被视为活动节点(打开)。你可以把它看作是一个灯泡;不严格地绑定到二进制状态,但也能够在两个限制之间的某种中间值。
每个连接都有一个权重,因此上一层中的活动节点可能或多或少地对下一层中的节点活动(兴奋连接)的贡献,而非活动节点不会传播任何贡献。
连接的权重也可能为负数,这意味着上一层中的节点对下一层中的节点不活动(抑制性连接)的贡献(或多或少)。
为简单起见,让我们描述一个网络的子集,其中上一层中的三个节点与下一层中的节点连接。同样,简单地说,假设上一层的前两个节点处于其激活的最大值 (1),而第三个节点的最小值 (0)。
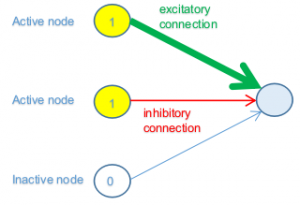
在上图中,上一层的前两个节点处于活动状态(开),因此,它们对下一层中的节点状态做出一些贡献,而第三个节点处于非活动状态(关闭),因此不会以任何方式(独立于其连接 w)八)。
第一个节点具有强(厚)正(绿色)连接权重,这意味着其对激活的贡献很大。第二个连接权重弱(薄)负(红色);因此,它有助于抑制连接的节点。
最后,我们有来自上一层传入连接节点的所有贡献的加权总和。
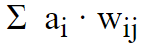
其中 a i是节点 i 和 w ij的激活状态,它是连接节点 i 与节点 j 的连接权重。
因此,鉴于此加权总和数,我们如何判断下一层中的节点是否会被激活?规则是否简单如”如果总和为正数,则激活,如果为负则不会”?
嗯,它可能是这样,但一般来说,这取决于你为一个节点选择的激活函数(以及哪个阈值)。
想想看;此最终数字可以是实数范围内的任何数字,而我们需要使用它来设置范围更有限的节点的状态(假设从 0 到 1)。然后,我们需要将第一个范围映射到第二个范围,以便将任意(负或正)数转换为 0.1 范围。
执行此任务的一个非常常见的激活函数是 sigmoid 函数
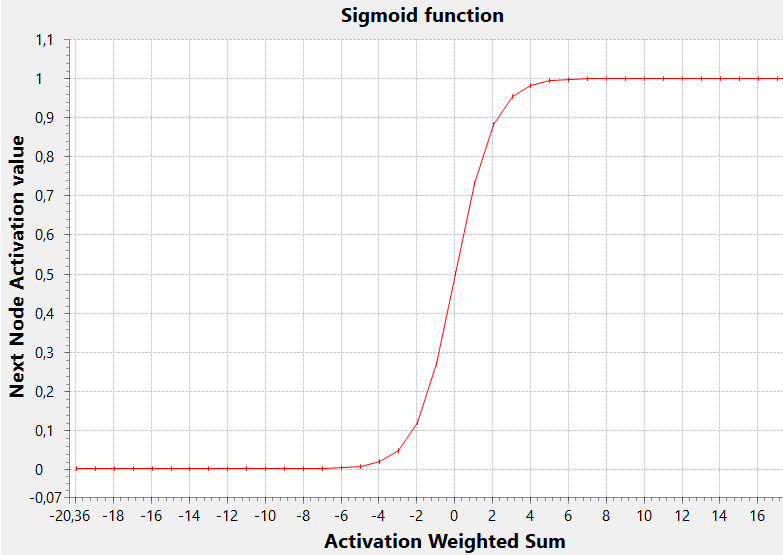
在此图中,阈值(y 值到达范围中间的 x 值,即 0.5)为零,但通常为任何值(负值或正值,导致 sigmoid 向左或向右移动)。
低阈值允许使用较低的加权总和激活节点,而高值阈值将仅确定具有高该总和值的激活。
可以通过考虑上一层中的附加虚拟节点(恒定激活值为 1)来实现此阈值。在这种情况下,实际上,此虚拟节点的连接权重可以充当阈值,并且上述总和公式可以被视为包含阈值本身
给定状态或权重值集可能会产生错误结果或大错误,而另一种状态可能会给出良好的结果,或者换句话说,小错误。
因此,在N 维状态空间中移动会导致小错误或大错误。此函数将权重域映射到错误值,是loss 函数。我们的头脑不能轻易想象在N+1空间中的这种功能。但是,我们可以对 N = 2: 阅读本文,您将看到的特殊情况有一个一般的想法。
训练神经网络包括找到一个良好的最小损失函数。为什么是一个好的最小值,而不是全局最小值?嗯,因为这个函数通常不可区分,所以你只能在一些梯度下降技术的帮助下在权重域中游荡,并希望不要:
- 使太大的步骤,可能会让你爬过一个良好的最低,而没有意识到它
- 使太小的步骤,可能会使你锁定一个不太好的本地最小值
这不是一件容易的事,嗯?这就是为什么这是深度学习的总体主要问题,以及为什么培训阶段可能需要数小时、数天或数周。这就是为什么你的硬件是这个任务的关键,为什么你经常必须停止培训,想想不同的方法和配置参数值,并重新开始!
但是,让我们回到网络的一般结构,这是一堆层。第一个层是输入 (x),而最后一个层是输出 (y)。
中间的图层可以是零、一个或多个。它们称为隐藏层,深度学习中的术语”深度”正好指网络可以有许多隐藏层,因此在训练过程中可能能找到更多与输入和输出相关的功能。
注意:在20世纪90年代,你会听说过多层网络而不是深层网络,但情况是一样的。只是现在,它变得更加清晰,一个层越远离输入(深),它就越可能捕获抽象特征。
另请参阅:
从程序员的角度设计Java中的神经网络
学习过程
在学习过程开始时,权重是随机设置的,因此第一层中的给定输入集将传播并生成随机(计算)输出。然后,将此输出与所呈现的输入所需的输出进行比较;差值是网络误差(损耗函数)的度量。
然后,此错误用于在生成该错误的连接权重中应用调整,此过程从输出层开始,逐步向后返回第一个层。
应用调整的金额可以是小或大,通常以称为学习速率的系数定义。
该算法被称为反向传播,并在1986年,在鲁默哈特,欣顿和威廉姆斯的研究后,成为流行。
记住中间的名字:杰弗里·辛顿。他经常被一些人称为”深度学习的教父”,是一位不知疲倦的照亮的科学家。例如,他现在正在研究一种叫做胶囊神经网络的新范式,这听起来像是该领域的又一场伟大的革命!
反向传播的目标是通过训练集对每次迭代的权重进行适当的修正,从而逐步减少网络的总体误差
问题总结为在 n 维曲面中查找最小值,同时用蒙眼罩四处走动:您可以找到局部最小值,并且从来不知道您是否能做得更好。
如果学习速率过小,则过程可能太慢,并且网络可能会在本地最小值停滞。另一方面,学习率大可能会导致跳过全局最小值并使算法出现偏差。
事实上,在培训阶段,问题往往是减少误差的过程不收敛,错误会增大而不是缩小!
今天
为什么这个领域现在取得如此巨大的成功?
主要原因有二:
- 培训所需的大量数据(来自智能手机、设备、物联网传感器和互联网) 的可用性
- 现代计算机的计算能力可以大大减少训练阶段(请注意,几天或几周的培训阶段并不罕见!
想深入领域?这里有几本好书:
- 亚当·吉布森,乔希·帕特森,奥赖利媒体公司
- 实用卷积神经网络由莫希特·塞瓦克,雷扎尔·卡里姆博士,普拉迪普贾里,帕克出版