
介绍:
在本教程中, 我将向您展示使用 twitter 的 api 从 twitter 获取推特的最简单方法。
我们将获取一些推文, 将它们存储到一个数据框架中, 并做一些交互式可视化, 以获得一些见解。
为了访问 twitter 的 api, 您需要具备以下信息:
- 消费者 api 密钥
- 消费者 api 密钥
- 访问令牌
- 访问令牌机密
这是一个非常简单的5分钟过程, 以获得这些。你只需要登录你的推特账户, 进入这个链接, 点击 ‘ 创建一个应用 ‘, 只需按照步骤操作。
创建应用并填充应用详细信息后, 只需进入应用详细信息, 转到密钥和令牌选项卡, 单击 “生成”, 您就会拥有您的密钥和令牌。
获取推文
我们首先将密钥和令牌存储在变量中
access_token = 'paste your token here'
access_token_secret = 'paste your token secret here'
consumer_key = 'paste your consumer key here'
consumer_secret = 'paste your consumer secret here'接下来, 我们导入我们现在将使用的库:
import tweepy
import numpy as np
import pandas as pd鸣叫是我们将用来访问推特 api 的图书馆。如果您没有这些库中的任何一个, 则只需为缺少的库运行点安装即可。
现在, 我们使用凭据进行身份验证, 如下所示:
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)一旦我们被认证, 就像在微博上挑选我们想搜索的任何话题, 看看人们在这个话题的背景下在推特上谈论什么一样简单。
例如, 让我们选择一个非常通用的词 “食物”, 看看人们在推特上谈论什么:
for tweet in api.search('food'):
print(tweet.text)api.search通常返回一个小插曲的很多属性 (其中之一就是小插曲本身)。其他属性包括推特用户发送推特的用户名、他们有多少关注者、推特被转发的情况以及许多其他属性 (我们稍后将看到如何获取其中的一些属性)。
目前, 我感兴趣的只是小插曲本身, 所以我回来 tweet.text 了。
其结果如下所示:

默认情况下, api.search 返回15条推特, 但如果我们想要更多的推特, 我们可以通过添加来获得多达 100条 count = 100 推特。计数只是我们可以在其他方面玩的论点之一, 比如语言、位置等。如果您有兴趣根据自己的喜好过滤结果, 您可以在这里查看。
此时, 我们成功地获取了15行代码以下的推文。
如果你想获得更多的推特和它们的属性, 并做一些数据可视化继续阅读
如果我们有兴趣一次获得 1 0 0多条推特, 就像我们的情况一样, 我们就不能仅仅通过使用 api.search 来做到这一点。我们需要使用 tweepy.Cursor 它, 这将使我们能够得到我们想要的尽可能多的推特。我并没有深入地试图理解机构服务所做的工作, 但我们的例子中的一般想法是, 它将允许我们阅读100条推特, 将它们本质上存储在一个页面中, 然后阅读接下来的100条推特。
为了我们的目的, 最终的结果是, 它只会继续获取推特, 直到我们要求它通过打破循环来停止。
我将首先 DataFrame 使用我们需要的列创建一个空。
df = pd.DataFrame(columns = ['Tweets', 'User', 'User_statuses_count',
'user_followers', 'User_location', 'User_verified',
'fav_count', 'rt_count', 'tweet_date'])
接下来, 我将定义一个函数, 如下所示。
def stream(data, file_name):
i = 0
for tweet in tweepy.Cursor(api.search, q=data, count=100, lang='en').items():
print(i, end='\r')
df.loc[i, 'Tweets'] = tweet.text
df.loc[i, 'User'] = tweet.user.name
df.loc[i, 'User_statuses_count'] = tweet.user.statuses_count
df.loc[i, 'user_followers'] = tweet.user.followers_count
df.loc[i, 'User_location'] = tweet.user.location
df.loc[i, 'User_verified'] = tweet.user.verified
df.loc[i, 'fav_count'] = tweet.favorite_count
df.loc[i, 'rt_count'] = tweet.retweet_count
df.loc[i, 'tweet_date'] = tweet.created_at
df.to_excel('{}.xlsx'.format(file_name))
i+=1
if i == 1000:
break
else:
pass让我们从里到外看看这个函数:
- 首先, 我们遵循同样的方法, 在一个 for 循环中获取每个小插曲, 但这次是从.
tweepy.Cursor - 在内部
tweepy.Cursor, 我们传递api.search我们想要的属性: - q = 数据:数据将是我们传递到流函数中的任何文本, 要求我们
api.search搜索, 就像我们在前面的示例中传递 “food” 一样。 - 计数 = 100:在这里, 我们将推特的数量设置为返回到 100
api.search, 通过,这是最大可能的数量。 - lang = “en”:在这里, 我只是过滤结果返回推文只在英语。
- 现在, 既然我们投入
api.search了,tweepy.Cursor就不会只停在前 1 0 0条推特上。相反, 它将永远持续下去;这就是为什么我们使用i作为一个计数器来停止循环在1000次迭代之后。 - 接下来, 我在
DataFrame.loc每次迭代中使用 pandas 和我i的计数器中的方法来填充我感兴趣的属性。 - 我在每列中传递的属性都是不言而喻的, 您可以查看 twitter api 文档中的其他属性, 并使用这些属性。
- 最后, 我使用 “df. to _ excel” 将结果保存到 excel 文件中, 在这里, 我使用占位符 {}, 而不是在函数中命名该文件, 因为我希望能够在运行函数时自己命名该文件。
现在, 我可以按如下方式调用我的函数, 再次查找有关食品的推特, 并命名我的文件 “my_tweets
好了, 现在我可以在目录中打开 excel 工作表以查看结果或在我的结果中获取结果 DataFrame , 如下所示:
df.head()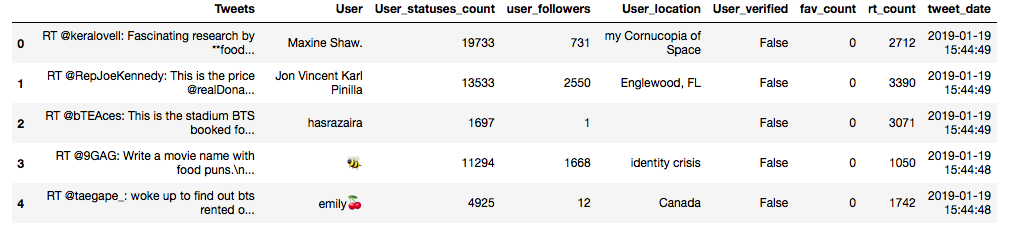
好的, 太好了!一切都按计划进行。
让我们分析一些推文
在本节中, 我们将对20000多条推特进行一些交互式可视化, 我已经流式传输和保存了这些推文, 以获得一些见解。
我将在本文的基础上使用详细说明来生成一些可视化效果, 而无需详细介绍使用的细节。如果你有兴趣了解更多关于剧情功能的细节, 你可以检查文章, 它是一个很好的资源。请注意, 如果您想使用实际的交互式可视化效果, 您需要转到此链接, 因为我将它们作为图片发布到下面。
让我们导入我们的库:
from textblob import TextBlob
from wordcloud import WordCloud, STOPWORDS
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot
import cufflinks
cufflinks.go_offline()
cufflinks.set_config_file(world_readable=True, theme='pearl', offline=True)让我们来看看我们 DataFrame 的:
df.info()
好了, 在这里, 我们有 226, 782 推特和一些值缺失的 “用户” 和 “用户 _ 位置。
缺少一些用户位置是有意义的, 因为并不是所有的推特用户都将自己的位置放在自己的个人资料上。
对于用户, 我不知道为什么这17个条目丢失, 但无论如何, 对于我们在这里的范围, 我们将不需要处理缺失的值。
让我们还可以快速查看我们的前5行 DataFrame :
df.head()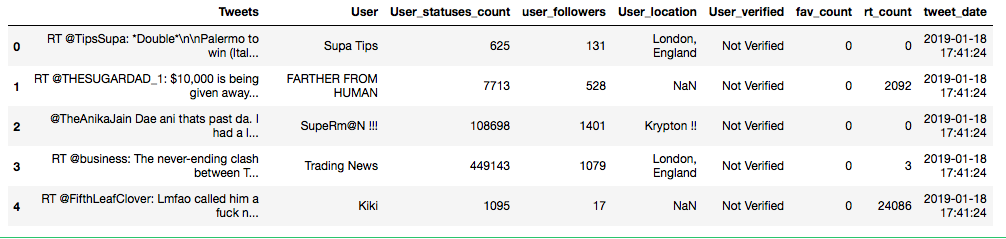
我想在这一点上增加一个 DataFrame 专栏, 表明一个小插曲的情绪。
我们还需要添加另一个列与推特剥离无用的符号, 然后运行情绪分析仪对那些清理推特是更有效的。
让我们从编写推特清理功能开始:
def clean_tweet(tweet):
return ' '.join(re.sub('(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)', ' ', tweet)感伤. 极性 > 0: 返回 “正” elif analysis.sentiment.polarity = = 0: 返回 “中性” 其他: 返回 “负”
现在, 让我们创建新列:
df['clean_tweet'] = df['Tweets'].apply(lambda x: clean_tweet(x))
df['Sentiment'] = df['clean_tweet'].apply(lambda x: analyze_sentiment(x))让我们看看一些随机行, 以确保我们的函数正常工作。
示例 (3, 000 行):
n=3000
print('Original tweet:\n'+ df['Tweets'][n])
print()
print('Clean tweet:\n'+df['clean_tweet'][n])
print()
print('Sentiment:\n'+df['Sentiment'][n])
示例 (第20行):
n=20
print('Original tweet:\n'+ df['Tweets'][n])
print()
print('Clean tweet:\n'+df['clean_tweet'][n])
print()
print('Sentiment:\n'+df['Sentiment'][n])
好吧, 看来我们的功能在起作用。请注意, 通过直接将我们的文本提供给类似的 textblob 情绪分析仪来进行情绪分析, 不会为所有推特产生100% 完美的结果。为了做到这一点, 我们需要做一些更详细的文本预处理, 但为了本教程的目的, 我们到目前为止已经足够了。
此时, 我们已准备好进行一些数据可视化。
我有兴趣看到的一些事情是:
- 所有推特的情绪分布 (大多数推特都有积极、消极或中性的背景吗?
- 最受欢迎的推特的情绪分布。
- 推特的情绪分布与平均人气。
- 最不受欢迎的推特的情绪分布。
- 用户的推特频率与拥有大量关注者之间是否存在关联?
- 用户是经过验证的用户还是对上述相关性没有影响?
- 所有推特用户使用的最常用词汇是什么?
- 流行的推特用户最常用的词汇是什么?
- 推特用户平均使用的词汇是什么?
- 最不受欢迎的推特用户最常用的单词是什么?
情绪分配
整体:
df['Sentiment'].value_counts().iplot(kind='bar', xTitle='Sentiment',
yTitle='Count', title='Overall Sentiment Distribution')
要玩这个互动可视化, 请转到这里的原始帖子
最受欢迎的:
下面我刚刚创建了一个新 DataFrame 的从我们原来的一个过滤与转发计数以上或等于50k值 _ count (). iplot (种类 = “bar”, xtitle = ‘ 情绪 ‘, ytitle = “计数”, 标题 = “情绪分布为 < br > 流行推特 (50k 以上) ‘)
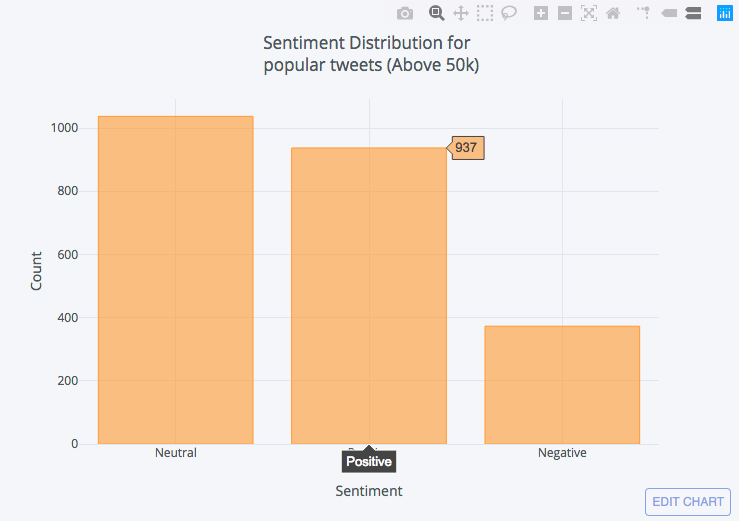
要玩这个互动可视化, 请转到这里的原始帖子。
平均受欢迎程度:
DataFrame使用500到 10, 000 之间的转发计数, 从我们原来的一个过滤中创建一个新的。
df_average = df[(df['rt_count'] <= 10000) & (df['rt_count'] >=500)]
df_average['Sentiment'].value_counts().iplot(kind='bar', xTitle='Sentiment',
yTitle='Count', title = ('Sentiment Distribution for <br> averagely popular tweets (between 500 to 10k)'))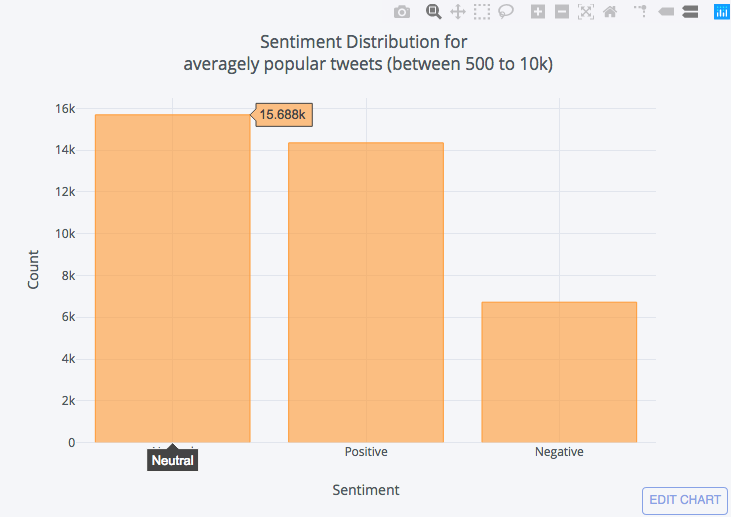
要玩这个互动可视化, 请转到这里的原始帖子
最不受欢迎的:
DataFrame通过使用小于或等于100的转发计数进行筛选, 从我们原来的版本中创建一个新的。
df_unpopular = df[df['rt_count'] <= 100]
df_unpopular['Sentiment'].value_counts().iplot(kind='bar', xTitle='Sentiment',
yTitle='Count', title = ('Sentiment Distribution for <br> unpopular tweets (between 500 to 10k)'))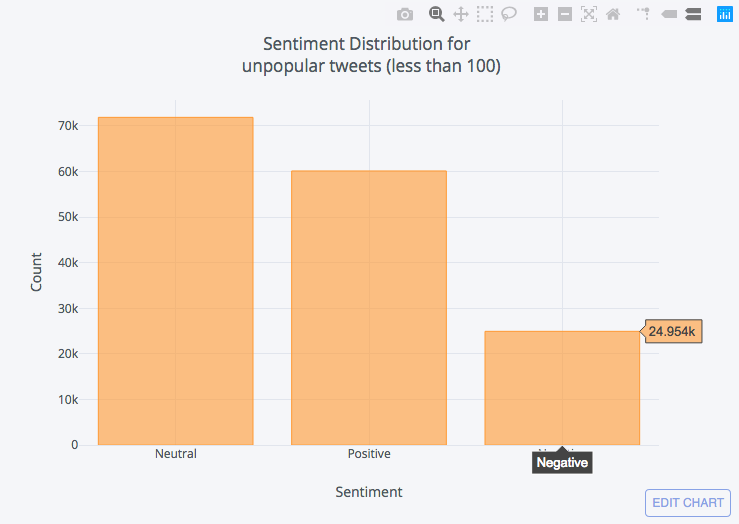
要玩这个互动可视化, 请转到这里的原始帖子。
从上面的图表中, 我们可以得出这样的结论:
- 一般来说, 大多数推特都是中性的。
- 大多数人倾向于对积极的事情进行调侃, 而不是对消极的事情进行调整。
- 推特情绪对转发统计影响不大。
推文频率与关注者的相关性
让我们一起:
- 绘制每个用户的状态数与每个用户的关注者数。
- 区分我们的绘图中经过验证的用户和未经验证的用户。
df.iplot(x='User_statuses_count', y = 'user_followers', mode='markers'
, categories='User_verified',layout=dict(
xaxis=dict(type='log', title='No. of Statuses'),
yaxis=dict(type='log', title='No. of followers'),
title='No. of statuses vs. No. of followers'))在这里, 我将这些值放在日志比例上, 以减少异常值的影响。
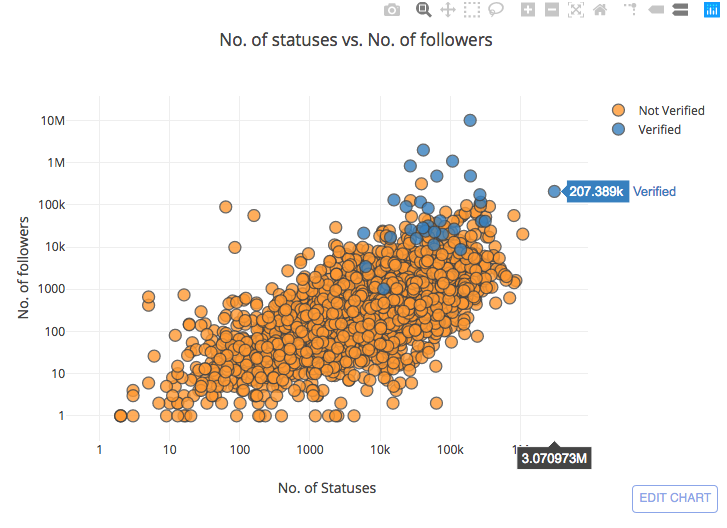
要玩这个互动可视化, 请转到这里的原始帖子。
注意: 在上面的图表中, 我没有使用完整的 200000 + 数据集, 因为它非常慢, 将其加载为交互式图表
从图表中, 我们总结了两件事:
- 推特的频率确实可能是关注者数量的促成因素之一。
- 经过验证的用户倾向于遵循与未经验证的用户相同的分布, 但他们大多集中在上地区, 超过未经核实的用户的关注者较多 (这是有道理的, 因为大多数经核实的用户都有望成为公众人物)。
让我们来看看最常用的单词
为了可视化最常用的单词, 我们将使用云这个词, 这是完成这样一个任务的好方法。word 云为我们提供了一个图像, 显示了一段不同大小的文本中使用的所有单词, 其中以较大大小显示的单词的使用频率更高。
为了获得有意义的结果, 我们需要通过删除塞子来过滤我们的推特。停止词通常是在句子中充当填充物的常用词, 在自然语言处理中删除这些词是常见的做法, 因为尽管我们用它们来理解一个句子作为人, 但它们并没有增加任何意义计算机在处理语言时, 它们实际上在数据中起到噪声的作用。
云库这个词有一个内置的停止词列表, 我们已经在上面导入了, 可以用来过滤掉我们文本中的停止词。
首先, 我们需要创建加入我们的所有推特, 如下所示:
all_tweets = ' '.join(tweet for tweet in df['clean_tweet'])接下来, 我们创建 “云” 一词:
wordcloud = WordCloud(stopwords=stopwords).generate(all_tweets)请注意, 上面我没有使用 wordcloud 库中包含的内置停止词列表。我使用的是一个更大的列表, 其中包括吨的停止词在几种语言, 但我不会粘贴在这里, 以避免占用无用的空间, 在本教程中, 因为它是一个非常大的列表 (你可以找到这样的列表, 如果你在网上搜索)。无论如何, 如果你想使用内置列表, 你可以忽略上面的代码, 并使用下面:
wordcloud = WordCloud(stopwords=STOPWORDS).generate(all_tweets)最后, 我们绘制 “云” 一词, 并将其显示为图像:
plt.figure(figsize = (10,10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
我们还可以绘制单词的频率如下:
df_freq = pd.DataFrame.from_dict(data = wordcloud.words_, orient='index')
df_freq = df_freq.head(20)
df_freq.plot.bar()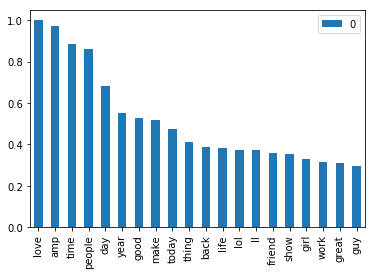
让我们再次做同样的事情, 只针对流行的推特, 只需更改这一段代码:
all_tweets = ' '.join(tweet for tweet in df_popular['clean_tweet'])wordcloud:
 单词频率:
单词频率: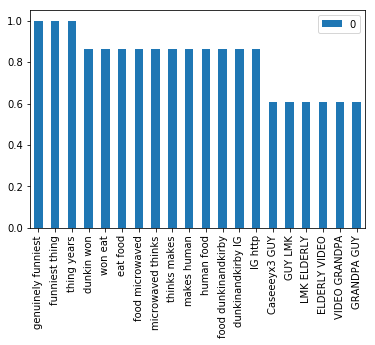
现在你也有了如何做到这一点的想法, 对于普通的和不受欢迎的推特。
就这样!
我希望你发现这个教程有用。
这篇文章最初是张贴在https://oaref.blogspot.com/