
Paramount+ 流媒体平台在本赛季 NFL 中超越了自己,在亚足联冠军赛和现在的超级碗期间打破了收视率记录,被誉为“历史上收视率最高的电视转播”。 paramountpressexpress.com/cbs-sports/releases/?view=109259-cbs-sports-presentation-of-super-bowl-lviii-是历史上观看次数最多的电视转播,拥有 12.34 亿观众-platforms” rel=”noopener noreferrer” target=”_blank”>平均观众人数为 1.234 亿。曾有超过 2 亿人观看过该游戏,大约占美国人口的 2/3。它还设立了一个新的基准,成为有史以来观看次数最多的超级碗。
考虑到这种程度的兴趣,派拉蒙+最终确定了他们的将于 2023 年初迁移到多区域架构。
此后,该流媒体平台一直在 Google Cloud 中的多个区域运行,并在 分布式 SQL 数据库,可跨多个远程位置运行。在此之前,数据库层带来了最大的架构挑战,促使他们开始寻找多主分布式数据库:
<块引用>
“Paramount+ 托管在单个主(又名读/写)数据库上。单个垂直扩展的主数据库只能让我们前进到目前为止。虽然团队考虑对数据进行分片并将其分散,但我们的过去的经验告诉我们,这将是一个费力的过程。我们开始寻找一个新的多主数据库,其标准是,由于应用程序的现有性质,我们必须确保坚持使用关系数据库。这个范围缩小了降低了标准,经过一些内部研究和概念验证,我们将范围缩小到数据库领域的新玩家 YugabyteDB。”
– 来自 Paramount+ 团队成员的引述
那么如何才能在多个区域实现这种级别的应用可扩展性和高可用性呢?在本博客中,我将使用示例应用程序来分析 Paramount+ 等服务如何在多区域设置中进行扩展。
正确构建多区域架构的关键组件
跨多个区域扩展应用程序层通常是理所当然的事情。只需选择最合适的云区域,在其中部署应用程序实例,然后使用全局负载均衡器自动路由和负载平衡用户请求。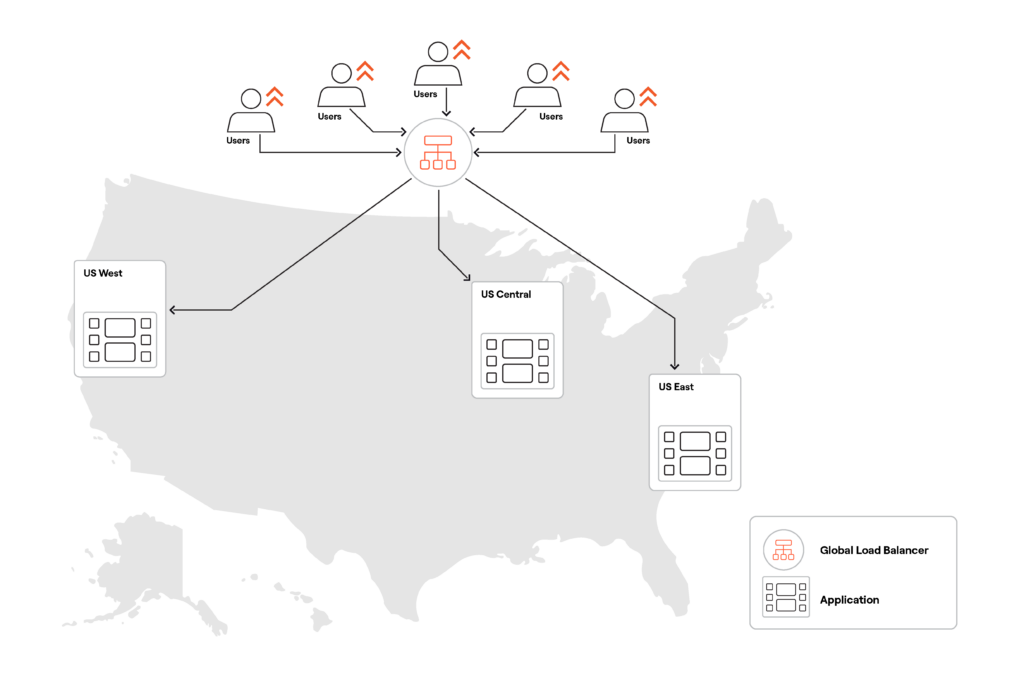
处理多区域数据库部署时,事情会变得更加复杂,特别是对于需要低延迟和数据不一致的事务性应用程序。
通过部署具有处理所有用户读写请求的单个主数据库实例的数据库实例,可以实现全局数据一致性。
但是,这种方法意味着只有靠近数据库云区域(美国东部)的用户才会体验到读写请求的低延迟。
距离数据库云区域较远的用户将面临更高的延迟,因为他们的请求传输的距离更长。此外,服务器、数据中心或托管数据库的区域发生中断可能会导致应用程序不可用。
因此,在设计多区域服务或应用程序时,正确选择数据库至关重要。
现在,让我们使用 YugabyteDB 进行实验,这是 Paramount+ 用于超级碗比赛的分布式数据库及其全球流媒体平台。
用于多区域应用程序的两种 YugabyteDB 设计模式
YugabyteDB 是一个基于 PostgreSQL 构建的分布式 SQL 数据库,本质上充当 PostgreSQL 的分布式版本。通常,数据库部署在跨多个服务器、可用区、数据中心或区域的多节点配置中。
Yugabyte 数据库将数据分片到所有节点,然后通过让所有节点处理读写请求来分配负载。 Raft 共识协议确保了事务一致性在集群节点之间同步复制更改。
在多区域数据库部署中,区域之间的延迟对应用程序性能的影响最大。虽然没有针对多区域部署的万能解决方案(使用 YugabyteDB 或任何其他分布式事务数据库),但您可以从多个 全局应用程序的设计模式并配置您的数据库,使其最适合您的应用程序工作负载。
YugabyteDB 提供八种常用的设计模式来平衡读写延迟与高可用系统的两个关键方面:恢复时间目标 (RTO) 和恢复点目标 (RPO)。
现在,让我们通过研究示例多区域应用程序的延迟来回顾八个设计模式列表中的两个 – 全局数据库和追随者读取。
设计模式#1:全局数据库
全局数据库设计模式 假设数据库分布在多个(即三个或更多)区域或区域。如果一个可用区出现故障,其他可用区的节点将在几秒内 (RTO) 检测到中断,并继续为应用程序工作负载提供服务,而不会丢失任何数据 (RPO=0)。
使用 YugabyteDB,您可以通过定义 首选区域。所有分片/Raft 领导者都将位于首选区域,为该区域附近的用户提供低延迟读取,并为较远的用户提供可预测的延迟。
我在美国东部、中部和西部配置了一个三节点 YugabyteDB 集群(如下),并将美国东部区域配置为首选区域。每个区域托管一个连接到首选区域(美国东部)节点的应用程序实例。
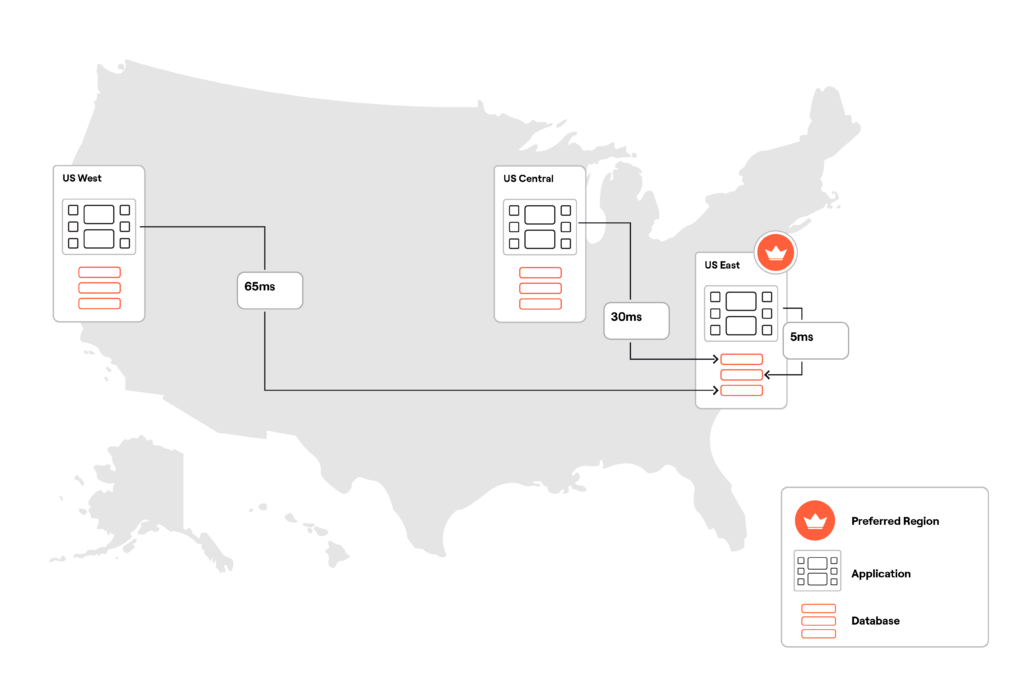 在此配置中,应用程序实例和数据库之间的往返延迟因距首选区域的距离。例如,来自美国东部的应用实例距首选区域 5 毫秒,而来自美国西部的实例距首选区域 65 毫秒。美国西部和中部应用实例不直接连接到其本地区域的数据库节点,因为这些节点仍会自动将所有请求路由到首选区域的领导者地区。
在此配置中,应用程序实例和数据库之间的往返延迟因距首选区域的距离。例如,来自美国东部的应用实例距首选区域 5 毫秒,而来自美国西部的实例距首选区域 65 毫秒。美国西部和中部应用实例不直接连接到其本地区域的数据库节点,因为这些节点仍会自动将所有请求路由到首选区域的领导者地区。
我们的示例应用程序是一个电影推荐服务,它接受用户问题使用简单的英语并使用生成式 AI 堆栈(OpenAI、Spring AI 和 PostgreSQL pgvector 扩展)为用户提供相关的电影推荐。
假设您想看一部结局意想不到的太空冒险电影。您连接到电影推荐服务并发送以下 API 请求:
http GET {app_instance_address}:80/api/movie/search \
提示=='一部关于太空冒险的电影,结局出乎意料'\
等级==7 \
X-Api-Key:superbowl-2024应用程序通过将为提示参数生成的嵌入与数据库中存储的电影概述的嵌入进行比较来执行向量相似性搜索。然后,它会识别最相关的电影并以 JSON 格式发回以下响应(如下):
http GET {app_instance_address}:80/api/movie/search \
提示=='一部关于太空冒险的电影,结局出乎意料'\
等级==7 \
X-Api-Key:superbowl-2024现在,所有区域的读取延迟始终很低并且具有可比性:

