
想象一下快速聚合和处理来自多个销售点 (POS) 系统的大量数据以进行实时分析的挑战。在这种速度至关重要的场景中,Kafka 和 ClickHouse 的结合成为了一个强大的解决方案。 Kafka 擅长处理高吞吐量数据流,而 ClickHouse 以其闪电般快速的数据处理能力而脱颖而出。它们共同构成了强大的二人组,能够构建顶级分析仪表板,提供及时、全面的见解。本文探讨了如何集成 Kafka 和 ClickHouse,将大量数据流转换为有价值的、真实的时间分析。
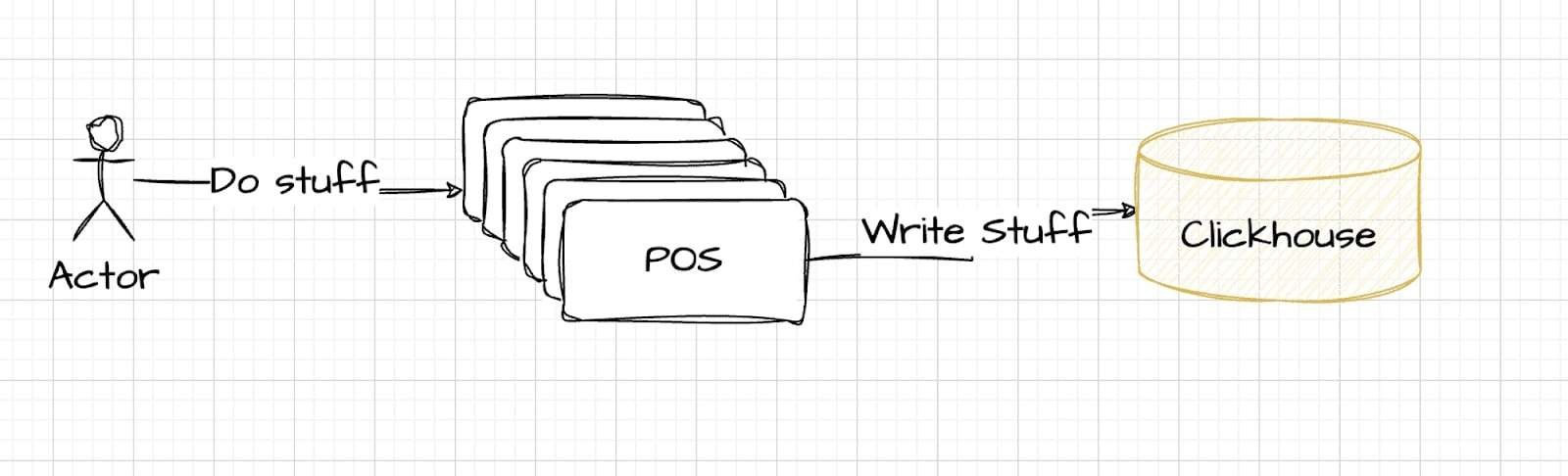
此图描述了最初的、简单的方法:数据直接从 POS 系统流到 ClickHouse 进行存储和分析。虽然看似有效,但这种有点幼稚的解决方案可能无法很好地扩展或处理实时处理需求的复杂性,从而为涉及 Kafka 的更强大的解决方案奠定了基础。
了解 ClickHouse 中数据插入的挑战
简单的方法可能会导致您在开始使用 ClickHouse 时陷入常见的陷阱或第一个“致命罪”(有关更多详细信息,请参阅 ClickHouse 的常见入门问题)。您可能会在数据插入期间遇到此错误,该错误在 ClickHouse 日志中可见,或者作为对 INSERT 请求的响应。掌握这个问题需要了解 ClickHouse 的架构,特别是“部分”的概念。
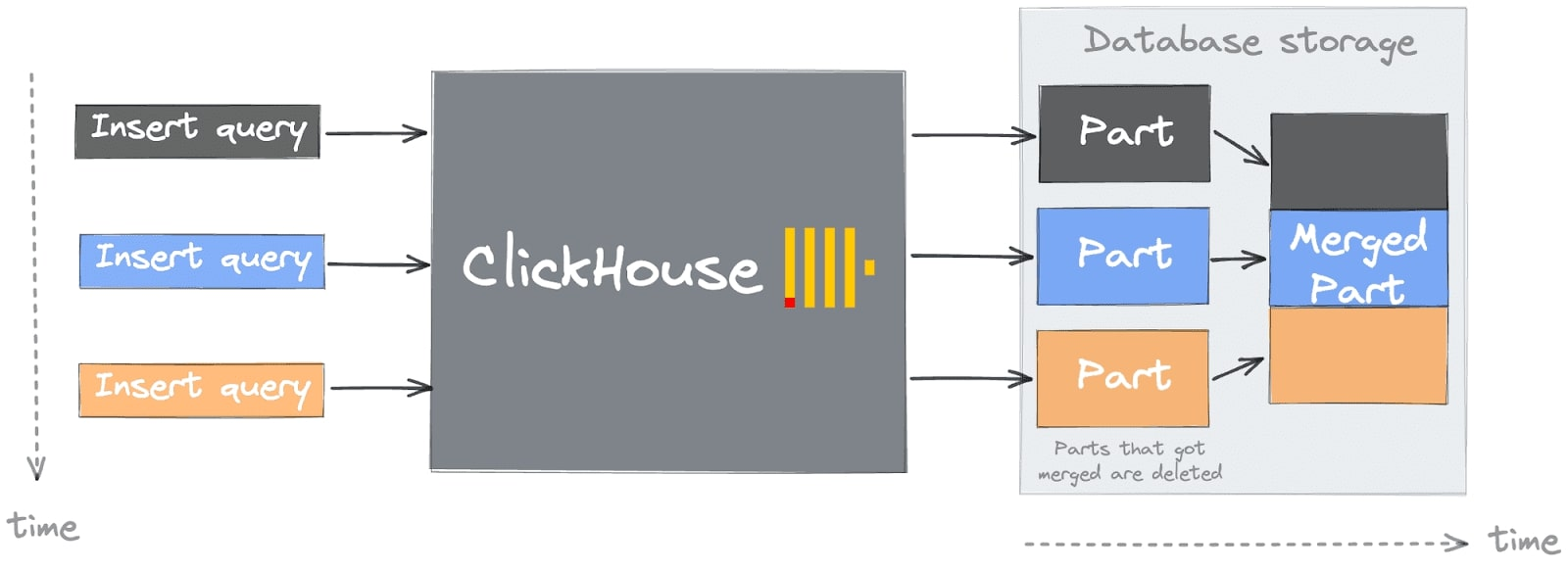
在精确管理、利用速度和并行性的情况下,将数据引入 ClickHouse 是最有效的。如图所示,最佳过程涉及由中央系统协调的批量插入,而不是单独的、不受控制的数据流:
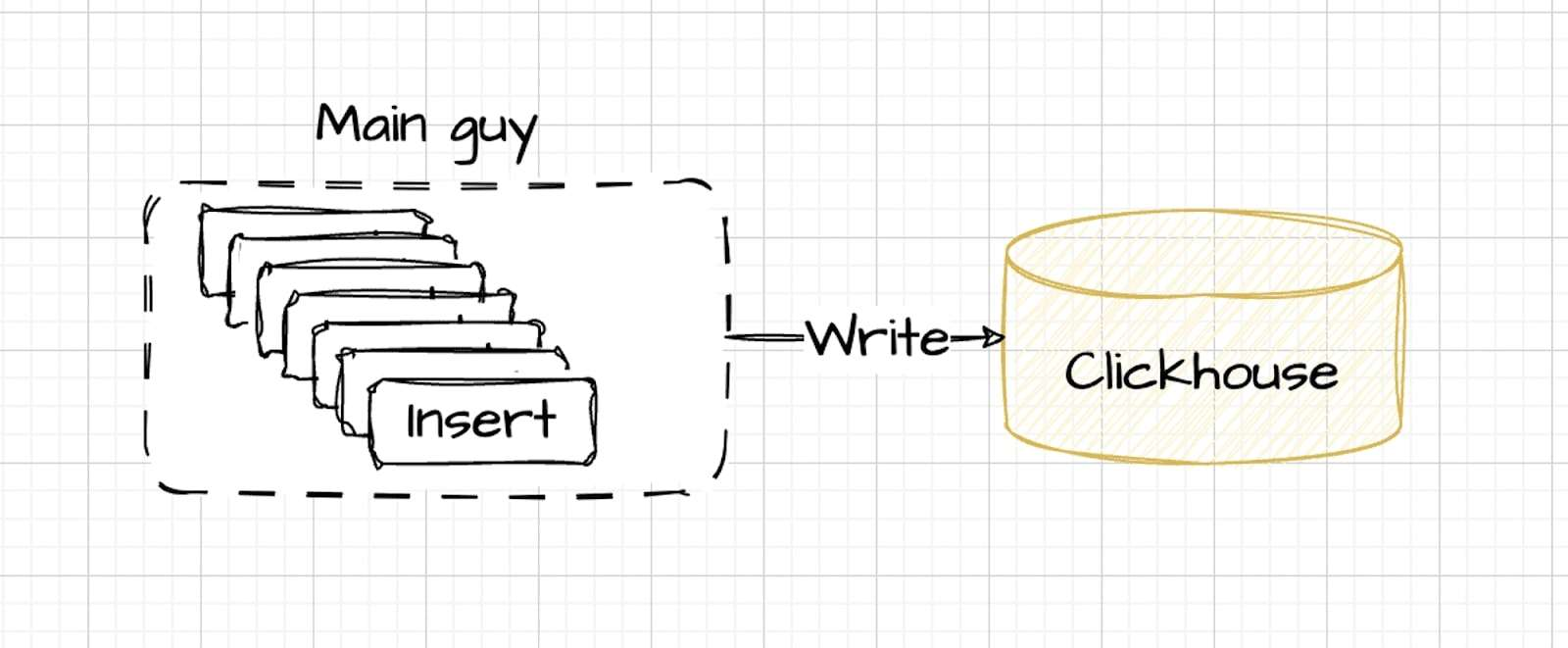 在最佳设置中,数据由管理流量的主控制器插入,动态调整速度,同时保持受控并行性。该方法保证了数据处理的高效性,符合ClickHouse的最佳性能条件。
在最佳设置中,数据由管理流量的主控制器插入,动态调整速度,同时保持受控并行性。该方法保证了数据处理的高效性,符合ClickHouse的最佳性能条件。
这就是为什么在实践中,通常在 ClickHouse 之前引入缓冲区:
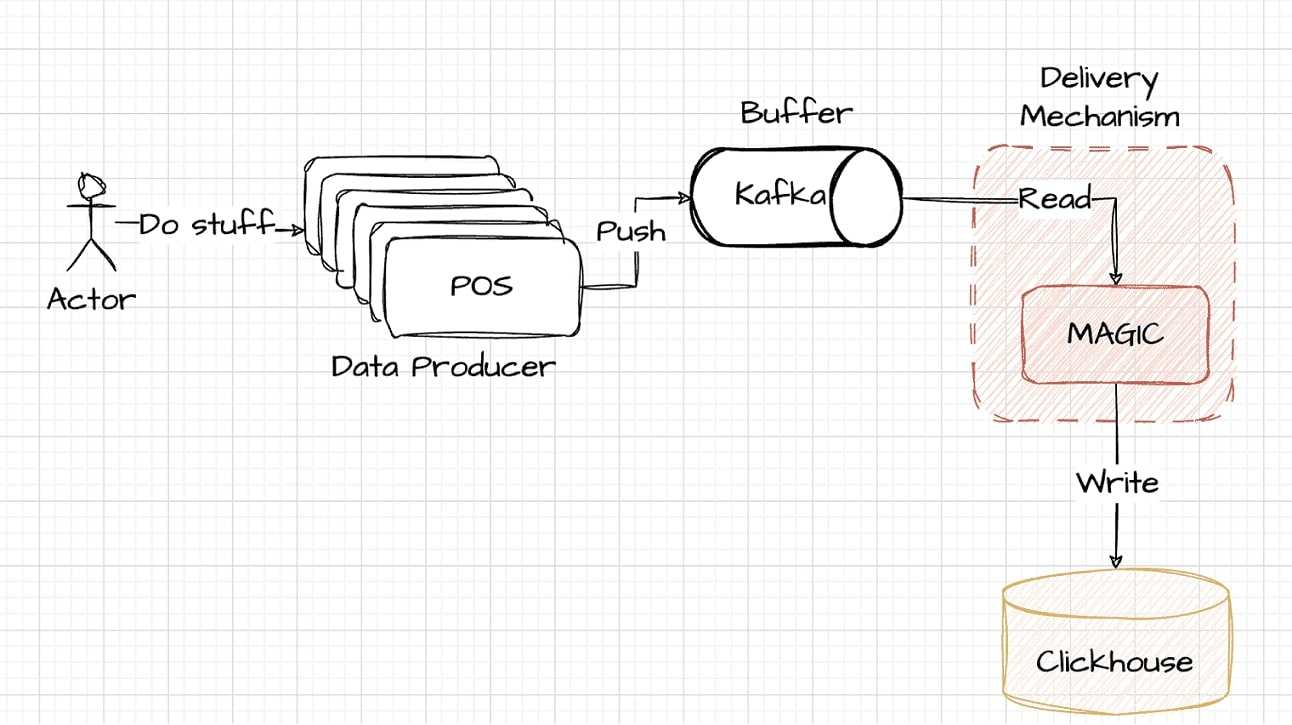 Kafka 的集成需要额外的编码来将数据从 POS 系统传输到 ClickHouse。该架构的这个元素虽然功能强大且可扩展,但也带来了复杂性,我们将在本文后面更详细地探讨这一点。
Kafka 的集成需要额外的编码来将数据从 POS 系统传输到 ClickHouse。该架构的这个元素虽然功能强大且可扩展,但也带来了复杂性,我们将在本文后面更详细地探讨这一点。
从 Kafka 到 ClickHouse 的数据传输
将数据从 Kafka 传输到 ClickHouse 的关键阶段包括读取 Kafka 主题、将数据转换为 ClickHouse 兼容的格式以及写入 将此格式化数据放入 ClickHouse 表中。这里的权衡在于决定在哪里执行每个阶段。
每个阶段都有自己的资源需求:
- 读取阶段:此初始阶段会消耗 CPU 和网络带宽来从 Kafka 主题中提取数据。
- 转换过程:转换数据需要使用 CPU 和内存。这是一个简单的资源利用阶段,计算能力会重塑数据以符合 ClickHouse 的规范。
- 写入阶段:最后一步是将数据写入 ClickHouse 表,这也需要 CPU 能力和网络带宽。这是一个例行过程,确保数据在分配了资源的 ClickHouse 存储中找到自己的位置。
集成时,平衡这些资源的使用至关重要。
现在,让我们研究一下将 Kafka 与 ClickHouse 链接起来的各种方法。
ClickHouse 的 Kafka 引擎
利用 ClickHouse 中的 Kafka 引擎将数据直接提取到表中。附图直观地展示了高级流程:
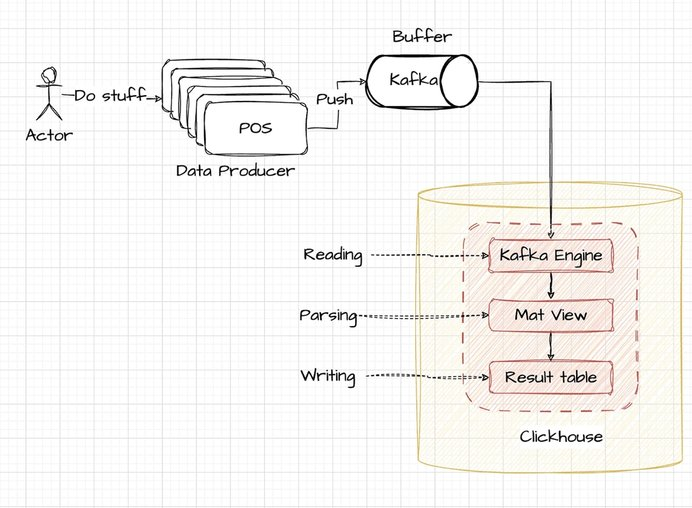
考虑到这种情况,POS 终端被设计为以结构化 JSON 格式输出数据,每个条目以换行符分隔。这种格式通常非常适合日志摄取和处理系统。
{"user_ts": "SOME_DATE", "id": 123, "message": "SOME_TEXT"}
{“user_ts”:“SOME_DATE”,“id”:1234,“message”:“SOME_TEXT”}要在 ClickHouse 中设置 Kafka 引擎,我们首先使用 Kafka 引擎在 ClickHouse 中创建一个主题包装器。提供的示例文件中对此进行了概述:示例 kafka_stream_engine。 sql
-- Clickhouse 队列包装器
在集群“{cluster}”上创建表 demo_events_queue (
-- JSON 内容架构
user_ts 字符串,
id UInt64,
消息字符串
) 引擎 = 卡夫卡设置
kafka_broker_list = 'KAFKA_HOST:9091',
kafka_topic_list = '主题名称',
kafka_group_name = 'uniq_group_id',
kafka_format = 'JSONEachRow'; -- 格式在此查询中,确定了三件事:
- 数据架构:包含三个已定义列的 ClickHouse 表结构;
- 数据格式:指定为“JSONEachRow”的格式,适合解析换行符分隔的 JSON 数据;
- Kafka 配置:包含 Kafka 主机和主题的设置,用于将数据源与 ClickHouse 链接起来。
设置的下一步涉及在 ClickHouse 中定义一个目标表来存储处理后的数据:
/example_projects/clickstream /kafka_stream_engine.sql#L12-L23
--存储数据的表
在集群“{cluster}”上创建表 demo_events_table (
主题字符串,
偏移量 UInt64,
分区 UInt64,
时间戳 DateTime64,
user_ts 日期时间64,
id UInt64,
消息字符串
) Engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/demo_events_table', '{replica}')
按 toYYYYMM(时间戳)分区
ORDER BY(主题、分区、偏移量);该表将使用 ReplicatedMergeTree 引擎构建,提供强大的数据存储功能。除了基础数据列之外,该表还将包含从 Kafka Engine 提供的元数据派生的附加列,以丰富数据存储和查询功能。
/example_projects/clickstream /kafka_stream_engine.sql#L25-L34
-- 交付管道
创建物化视图 Readings_queue_mv TO demo_events_table AS
选择
——kafka引擎虚拟专栏
_topic 作为主题,
_offset 作为偏移量,
_partition 作为分区,
_timestamp 作为时间戳,
-- 复杂日期解析的示例
toDateTime64(parseDateTimeBestEffort(user_ts), 6, 'UTC') 作为 user_ts,
ID,
信息
FROM demo_events_queue;集成过程的最后一步是在 ClickHouse 中设置一个物化视图,将 Kafka Engine 表与目标表连接起来。该物化视图将自动将数据从 Kafka 主题转换并插入到目标表中,确保数据得到一致且高效的处理和存储。
这些配置共同促进了将数据从 Kafka 流式传输到 ClickHouse 的强大管道:
选择计数(*)
来自 demo_events_table
查询 ID:f2637cee-67a6-4598-b160-b5791566d2d8
┌─count()─┐
│ 6502 │
└──────────┘
一组 1 行。已用时间:0.336 秒。在 ClickHouse 中部署所有三个阶段(读取、转换和写入)时,对于较小的数据集,此设置通常更易于管理。但是,对于更大的工作负载,它可能无法有效地扩展。在重负载下,ClickHouse 通常会优先考虑查询操作,这可能会导致资源竞争时数据传输延迟增加。在规划大容量数据处理时,这是一个重要的考虑因素。
虽然 Kafka Engine 集成可以正常运行,但它也带来了一些挑战:
- 偏移量管理:Kafka 中格式错误的数据可能会导致 ClickHouse 停顿,需要手动干预来删除偏移量,这是一项艰巨的任务。
- 可观察性有限:由于操作是 ClickHouse 内部的,因此监控更加复杂,并且在很大程度上依赖于分析 ClickHouse 日志来了解系统行为。
- 可扩展性问题:在 ClickHouse 内部执行解析和读取可能会阻碍高负载期间的扩展,从而可能导致资源争用问题。
利用 Kafka Connect
Kafka Connect 提供了一种不同的方法,将数据管理的复杂性从 ClickHouse 重新分配到 Kafka。
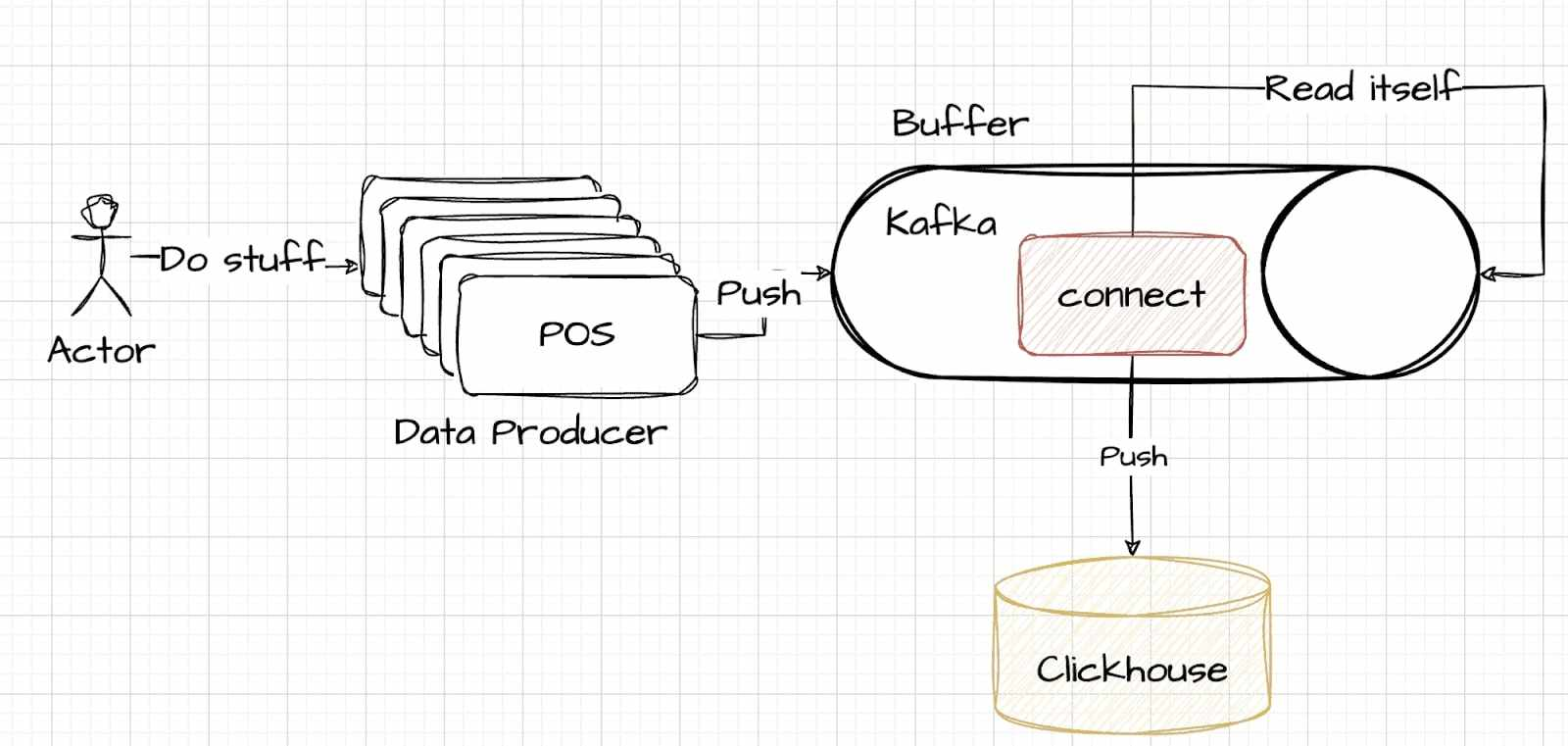
此策略需要仔细决定在何处处理复杂的数据管理问题。在此模型中,读取、解析和写入等任务在 Kafka Connect 中管理,Kafka Connect 作为 Kafka 系统的一部分运行。这种方法的权衡类似,但涉及将处理负担从数据存储侧转移到缓冲侧。 此处提供了一个说明性示例来演示如何建立此连接。
选择外部编写器
外部写入器方法代表了一种优质解决方案,为那些准备进行更多投资的人提供卓越的性能。它通常涉及负责数据处理的外部系统,位于缓冲区(Kafka)和存储(ClickHouse)层之外。该设置甚至可以与数据生成源位于同一位置,从而提供高水平的效率和速度。下图简化了此配置,展示了如何将外部编写器集成到数据管道中:
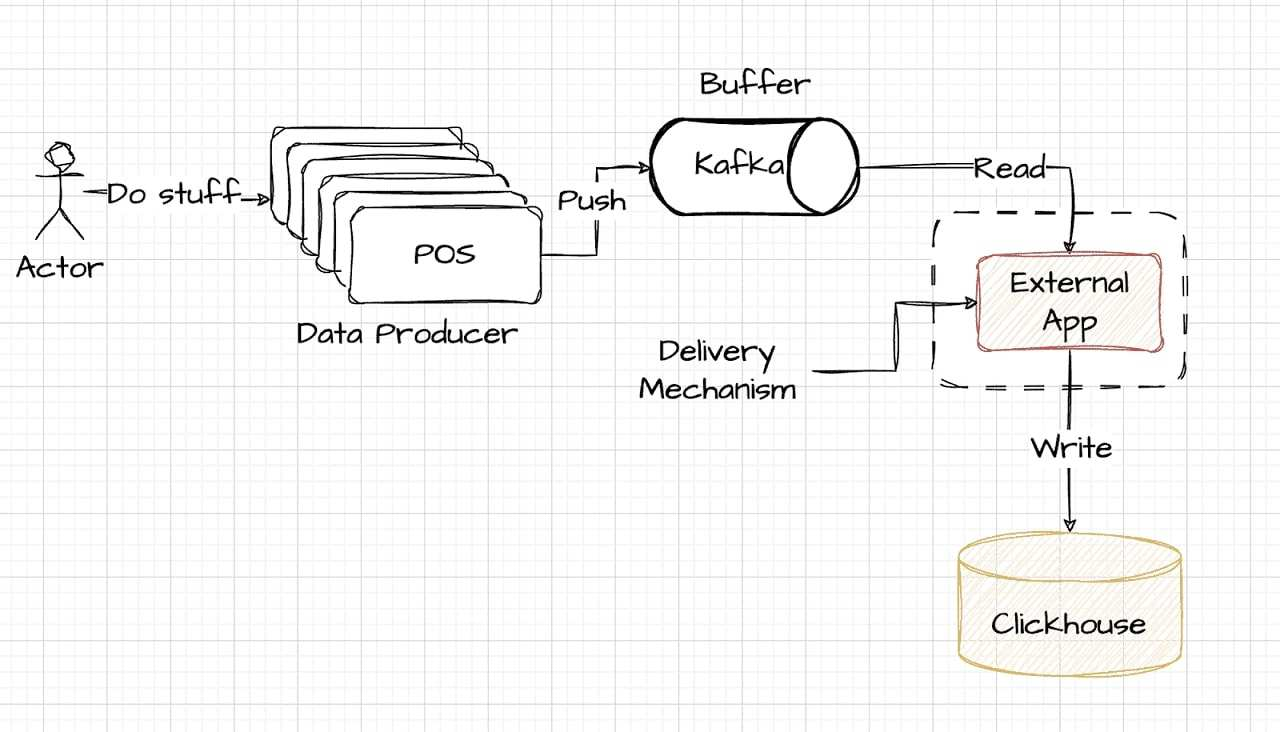
通过 DoubleCloud 的外部编写器
为了使用 DoubleCloud Transfer 实现外部编写器方法,设置涉及两个主要组件:源端点和目标端点,以及传输机制本身。使用 Terraform 可以有效管理此配置。此设置中的一个关键元素是源端点的解析器规则,这对于准确解释和处理传入数据流至关重要。此配置的详细信息如下:
/example_projects/clickstream /transfer.tf#L16-L43
解析器 {
json {
模式{
字段{
场地 {
名称=“用户_ts”
类型=“日期时间”
键=假
必需 = 假
}
场地 {
名称=“id”
类型=“uint64”
键=假
必需 = 假
}
场地 {
名称=“消息”
类型=“utf8”
键=假
必需 = 假
}
}
}
null_keys_allowed = false
add_rest_column = true
}
}DoubleCloud Transfer 中的解析器配置与 ClickHouse 中的 DDL 规范的作用类似。这对于确保正确解释和处理传入数据至关重要。建立源端点后,下一步是添加目标数据库,这通常更简单:
/example_projects/clickstream /transfer.tf#L54-L63</a>
clickhouse_target {
clickhouse_cleanup_policy = "删除"
联系 {
地址 {
cluster_id = doublecloud_clickhouse_cluster.target-clickhouse.id
}
数据库=“默认”
用户=“管理员”
}
}最后,将它们链接在一起进行传输:
/example_projects/clickstream /transfer.tf#L67-L75
资源“doublecloud_transfer”“clickstream-transfer”{
name =“点击流传输”
项目 ID = var.项目 ID
源 = doublecloud_transfer_endpoint.clickstream-source[count.index].id
目标 = doublecloud_transfer_endpoint.clickstream-target[count.index].id
类型=“INCRMENT_ONLY”
激活=真
}完成这些步骤后,您使用 DoubleCloud Transfer 的数据传输系统现已投入运行。此设置可确保数据从源数据库到目标数据库的无缝流动,从而有效管理整个流程。
DoubleCloud 的 EL(t) 引擎 Transfer 将队列引擎集成到 ClickHouse 交付中,解决常见挑战:
- 自动偏移管理:Transfer 通过未解析的表自动处理损坏的数据,最大限度地减少手动偏移管理的需要。
- 增强可观察性:与 ClickHouse 中的有限监控不同,Transfer 提供专用仪表板和警报,用于实时洞察数据延迟、行数和传输字节数等传输指标。< /里>
- 动态可扩展性:Transfer 的交付作业托管在 Kubernetes、EC2 或 GCP 上,允许独立于 ClickHouse 进行可扩展操作。
Transfer 还提供了开箱即用的功能来增强其功能:
- 自动架构演变:自动将向后兼容的架构更改与目标存储同步。
- 自动死信队列:通过将损坏的数据重定向到 ClickHouse 表中指定的死信队列 (DLQ),有效管理损坏的数据。
通过 Clickpipe 的外部写入器
ClickPipes 提供了一种简化且高效的解决方案,用于从各种来源提取数据。其用户友好的界面可以轻松快速地进行设置。 ClickPipes 专为高需求场景而设计,拥有强大、可扩展的架构,可提供一致的性能和可靠性。虽然 ClickPipes 在功能方面与 DoubleCloud Transfer 相似,但它不支持自动架构演变。有关详细的设置说明,请在此处获取综合指南。
结论
在本文中,我们探索了将 Kafka 与 ClickHouse 集成的各种方法,重点关注 Kafka Engine、Kafka Connect、DoubleCloud Transfer 和 ClickPipes 等选项。这些方法中的每一种都具有独特的优势和考虑因素,适合不同的数据处理要求和运营规模。从资源管理到系统可扩展性,选择正确的方法对于实现最佳数据处理至关重要。
要进一步探索 Kafka 和 ClickHouse 的协同作用,请考虑深入研究 DoubleCloud 堆栈。他们提供了富有洞察力的 Terraform 示例,对于那些希望在数据处理工作流程中实现这些强大工具的人来说,这些示例可以成为一个很好的起点。如需更详细的指导,请查看他们的 Terraform 示例 .




