在本系列的第一部分中, 我概述了如何使用不同的统计函数和 k 均值聚类来检测时间序列数据的异常。在第二部分中, 我分享了一些代码, 说明了如何将 k 均值应用于时间序列数据以及 k 均值的一些缺点。在这篇文章中, 我将分享:
- 如何使用 k 均值和影响 db 使用 firxdb python 客户端库检测 ekg 数据中的异常。
- 我是如何利用编年史来警惕异常的。
您可以在此存储库中找到我使用的代码和数据集。我借用了“乱鱼” 教程中的代码。这是相当不错的, 我建议检查出来。
如何利用 k 均值和影响 db 利用影响数据库 python 客户端库检测 ekg 数据中的异常
如果你读了第二部分, 那么你知道这些是我用来用 k-手段进行异常检测的步骤:
- 分段-通过水平转换将时间序列数据拆分为小片段的过程。
- 窗口-将分割数据乘以窗口函数以截断窗口前后的数据集的操作。术语 “窗口” 的名称来自于它的功能: 它允许您只查看窗口范围内的数据, 因为之前和之后 (或窗口外部) 的所有内容都乘以零。窗口允许您无缝地将重建后的数据拼接在一起。
- 聚类分析-对相似的窗口段进行分组并在聚类中查找质心的任务。质心位于集群的中心。从数学上讲, 它是由集群中所有点的算术平均位置定义的。
- 重建-重建时间序列数据的过程。从本质上讲, 您正在将正常的时间序列数据与最近的质心 (预测质心) 匹配, 并将这些质心拼接在一起, 以生成重建的数据。
- 正常误差-重建的目的是计算与时间序列预测的输出相关联的正常错误。
- 异常检测-由于您知道重建的正常错误是什么, 现在可以将其用作异常检测的阈值。超出该正常错误的任何重建错误都可以被视为异常。
在上一篇文章中, 我介绍了如何执行分段、窗口和群集以创建重建。在这篇文章中, 我将重点介绍我如何使用python cl来执行异常检测。但是, 在我们深入到异常检测之前, 让我们花点时间进行一些数据探索。首先, 我使用 cl 查询我的正常 ekg 数据并将其转换为数据框架。
client = InfluxDBClient(host='localhost', port=8086)
norm = client.query('SELECT "signal_value" FROM "norm_ekg"."autogen"."EKG" limit 8192')
norm_points = [p for p in norm.get_points()]
norm_df = pd.DataFrame(norm_points)
norm_df.head()接下来, 我删除时间戳并将 “cn/” 转换为数组。请记住, 只有在时间序列数据是规则的 (即 ti 和 ti+1 之间的间隔始终相同) 的情况下, 使用 k-宁对时间序列数据进行异常检测才是可行的。这就是为什么我可以排除以下任何分析的时间戳
阵列 (范数 _ df [“信号 _ value”])
在我们进入分段之前, 我们需要绘制正常的 ekg 数据并进行一些数据探索:
n_samples_to_plot = 300
plt.plot(ekg_data[0:n_samples_to_plot])
plt.xlabel("Sample number")
plt.ylabel("Signal value")
plt.show()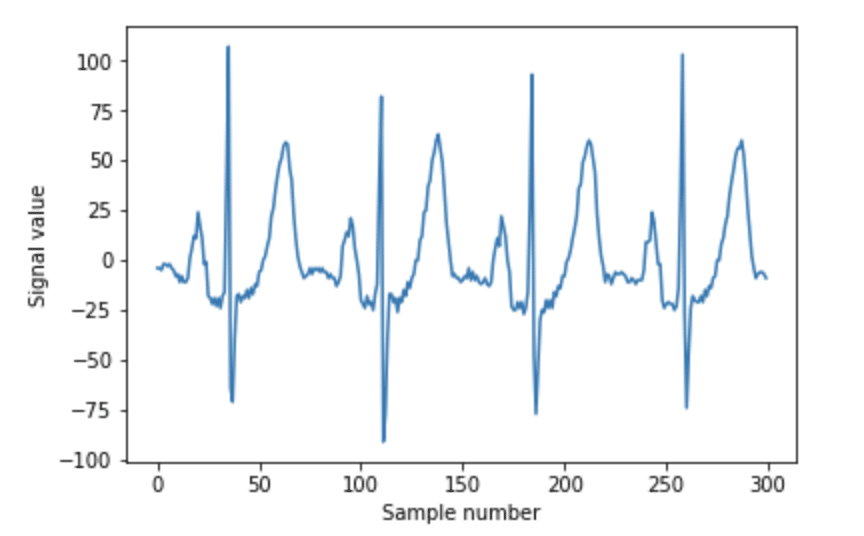
若要执行分段, 必须首先决定要将细分的时间长度。如果查看数据, 可以看到三个重复的形状。围绕 “样本数” 30、110、180和 260, 我们看到了一个陡峭的峰值, 称为 qrx 复合体。在每个 qrx 复合体之前, 都有一个小隆起。这被称为 p 波。紧跟在 qrx 复合体之后, 我们有 t 波。这是周期最大的第二高的山峰。我们要确保我们的段长度足够长, 可以封装其中的每一个波。由于 t 波的周期最长, 我们将该周期设置为等于段长度的位置 < cn/>。
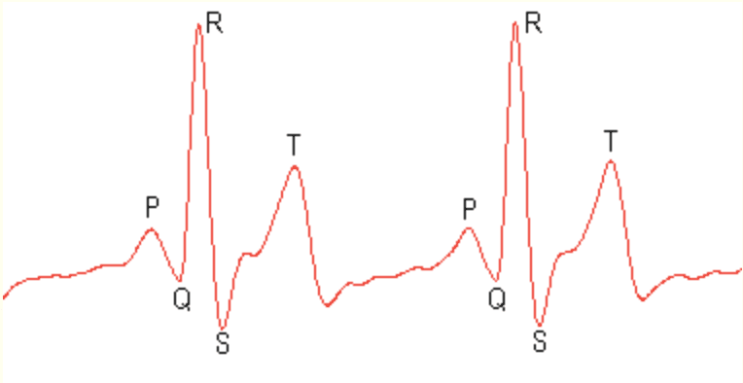
具有标记特征的正常 ekg 信号
然后使用此分割函数对 ekg 数据进行分段:
def sliding_chunker(data, window_len, slide_len):
""" Segmentation """
chunks = []
for pos in range(0, len(data), slide_len):
chunk = np.copy(data[int(pos):int(pos+window_len)])
if len(chunk) != window_len:
continue
chunks.append(chunk)
return chunks我将段存储在名为 < cn/> 的数组列表中:
slide_len = int(segment_len/2)
test_segments = sliding_chunker(
ekg_data,
window_len=segment_len,
slide_len=slide_len
)
len(test_segments)接下来, 我们执行上一篇文章中所述的重建, 并确定正常 ekg 数据的最大重建误差为8.8。
reconstruction = np.zeros(len(ekg_data))
slide_len = segment_len/2
for segment_n, segment in enumerate(test_segments):
# don't modify the data in segments
segment = np.copy(segment)
segment = segment * window
nearest_centroid_idx = clusterer.predict(segment.reshape(1,-1))[0]
centroids = clusterer.cluster_centers_
nearest_centroid = np.copy(centroids[nearest_centroid_idx])
# overlay our reconstructed segments with an overlap of half a segment
pos = segment_n * slide_len
reconstruction[int(pos):int(pos+segment_len)] += nearest_centroid
n_plot_samples = 300
error = reconstruction[0:n_plot_samples] - ekg_data[0:n_plot_samples]
error_98th_percentile = np.percentile(error, 98)
print("Maximum reconstruction error was %.1f" % error.max())
print("98th percentile of reconstruction error was %.1f" % error_98th_percentile)
plt.plot(ekg_data[0:n_plot_samples], label="Original EKG")
plt.plot(reconstruction[0:n_plot_samples], label="Reconstructed EKG")
plt.plot(error[0:n_plot_samples], label="Reconstruction Error")
plt.legend()
plt.show()现在, 我已准备好开始异常检测。首先, 我向 python 客户端查询异常数据。尽管数据是历史的, 但此脚本旨在模拟实时异常检测。我以32秒的间隔查询数据, 就像从数据流中收集数据一样。接下来, 我像以前一样创建重建, 并计算每个段的最大重建误差。最后, 我将这些错误写入一个名为 “cn/” 的新数据库.
while True:
end = start + timedelta(seconds=window_time)
query = 'SELECT "signal_value" FROM "anomaly_ekg"“ekg” 时间在哪里 & gt; “+ str (开始) +” \ ‘ 和时间 & lt; \ \ ‘ + str (结束) + ‘ 客户端 = 无法 fxdbclient (主机 = ‘ localhost ‘, 异常 _ stream = 客户端 (查询) 异常 _ pnts = [p 在异常 _ stream. get _ 点 ()] df _ 异常 = pd 中的 p。datackframe (异常 _ pnts) 异常 = np. 阵列 (df _ 异常 [“信号 _ value”) 窗口段 = 异常 * 窗口最近 _ centroid _ idx = clusterer.predict(windowed_segment.reshape(1,-1))错误 = nearest_centroid[0:n_plot_samples]-windowed_segment[0:n_plot_samples] max _ error = 错误. max () write _ time = start + time 增量 (秒 = 幻灯片 _ time) client. switch _ vecl (“错误 _ ekg”) json _ body = [{“masu要求 “:” 错误 “、” 标记 “: {” 错误 “:” 最大错误 “、}” 时间 “、” 写入时间 “、” 字段 “: {{” max _ 错误 “: 最大错误}}}} 客户端. write _ 点 (json _ body) 打印 (” query _ body: “+ 查询)
打印 (“最大错误:” + str (最大错误)) 启动 = 启动 + 时间增量 (秒 = 幻灯片 _ time) time.sleep(32)
我得到这个输出:

现在, 我可以将最大错误写入数据库, 我已准备好使用 kpacitor 设置阈值, 并对超过我正常最大重建错误8.8 的任何错误发出警报。
我是如何利用编年史来警惕异常的
为了使用卡帕克查, 影响数据的数据处理框架, 我需要写一个 tickscript, dsl 为 kappitor, 以警惕异常。因为我是一个新的 kafacitor 用户, 我选择使用编年史, 以帮助我管理我的提醒和自动生成一个 tickscript 为我。我真幸运!
首先, 我导航到 “管理任务” 页..。
接下来, 选择 “生成警报规则”:
现在我可以开始构建我的警报规则了。我命名我的警报, 选择警报类型..。
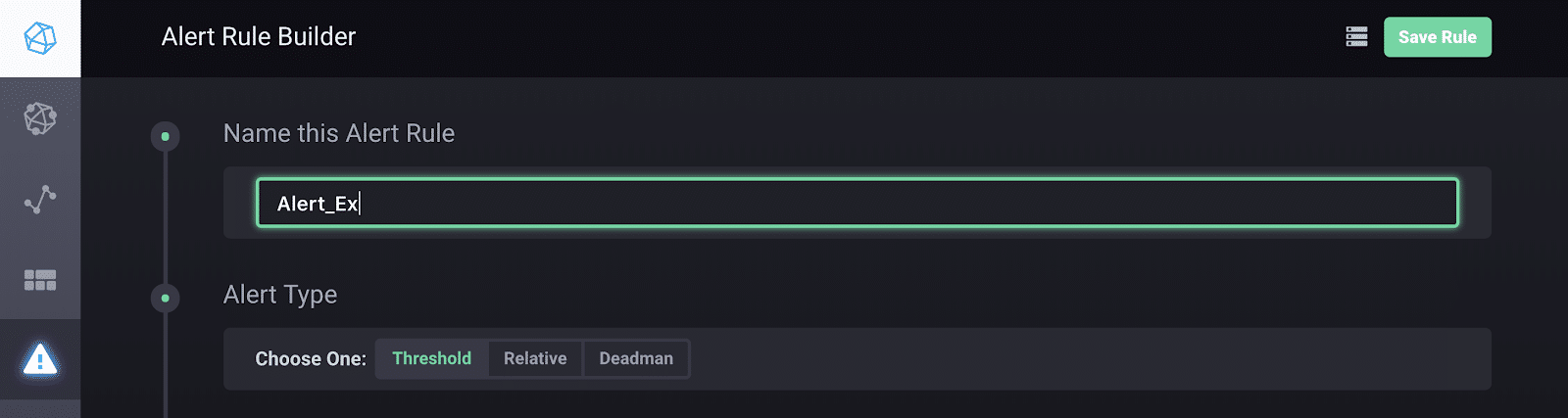
…… 并选择要提醒的字段值和阈值的条件。最后, 我指定要将这些警报发送到的位置..。
并配置连接。
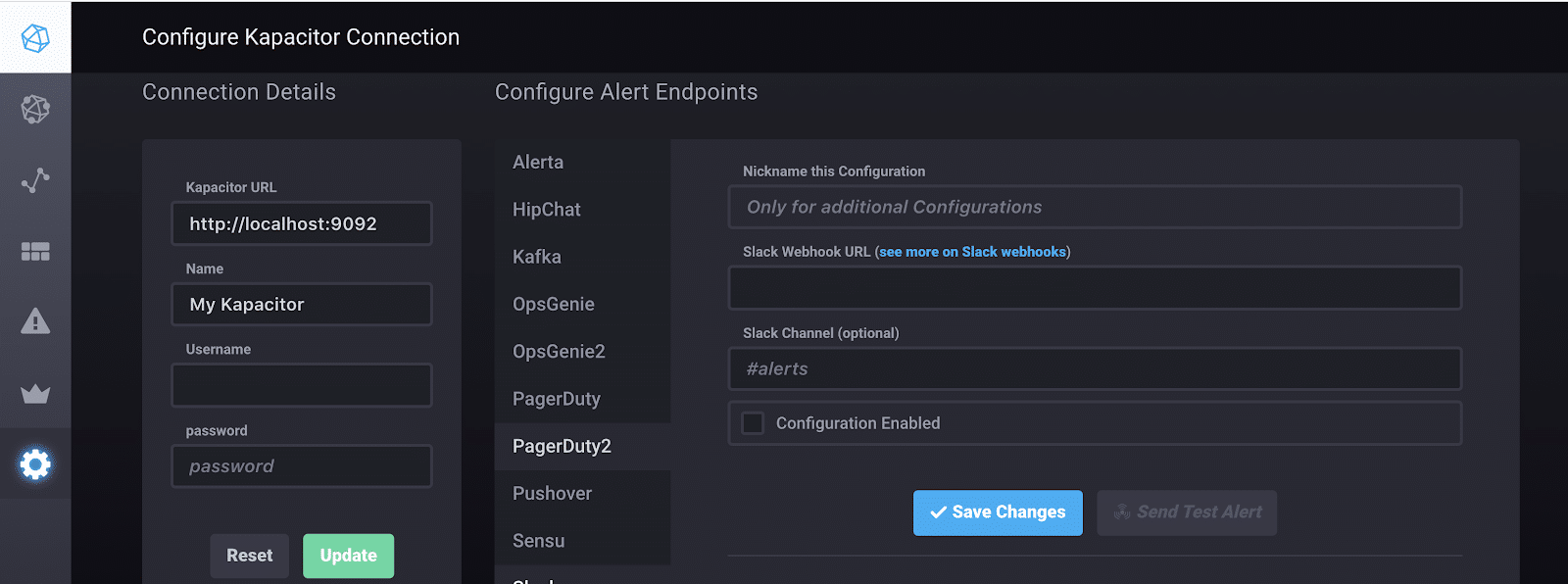
如果我返回到 “管理任务” 页面, 我现在可以查看自动生成的 tickscript。默认情况下, kafacitor 将这些警报写入 “chronograf” 数据库。如果我想更改输出数据库, 只需更改第25行。
var outputDB = 'chronograf'仅此而已!当我运行 while 循环并将错误发送到数据库时, 每次我的错误大于8.8 时, Kapacitor 都会使我放松。
如果我们看一下我的仪表板, 您可以看到我在包含异常的段上有一个大于8.8 的错误, 而 k王号能够检测到它。
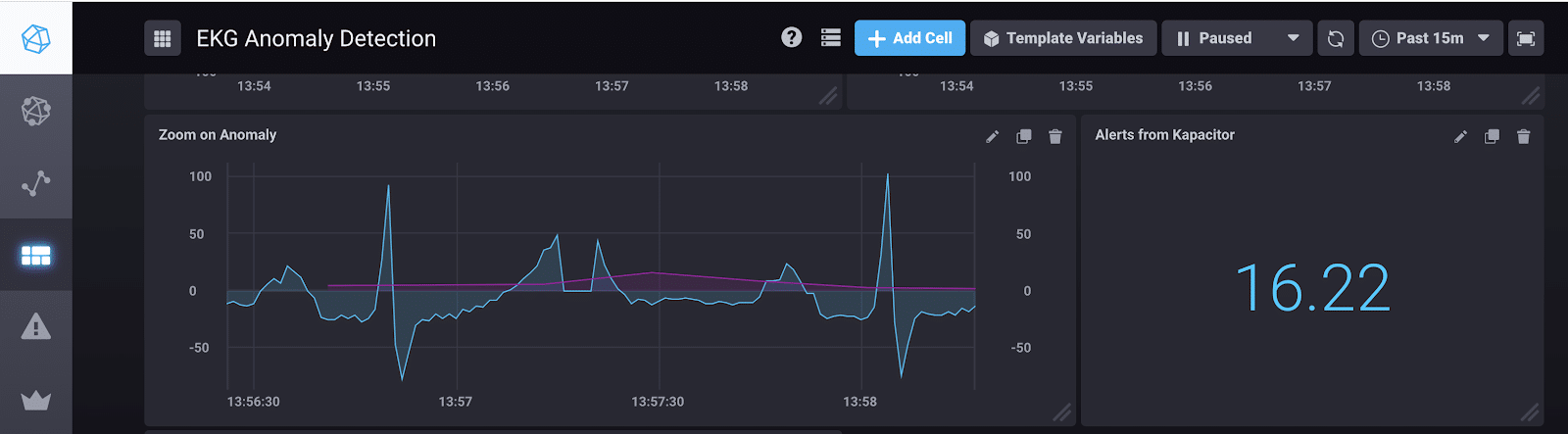
左单元格:品红色线表示每32个点的最大重建误差。它开始超过8.8 在异常发生在13:57:20 左右。
右单元格:我使用查询 “select 最大值 (” 值 “) as” 最大值 “从” ch6时 graf “显示异常的最大误差”警报” 限制 1 “
我希望这和以前的博客文章可以帮助你在你的异常检测之旅。如果你发现有什么困惑或随时向我求助, 请告诉我。您可以访问影响数据社区网站或@InfluxDB 调整我们。
最后, 为了一致性起见, 我也想用大脑休息来结束这个博客。这里有一些变色龙给你。