
作为数据库管理员或应用开发者,大家肯定有过SQL优化经历。数据库上执行的SQL千差万别,且伴随着业务快速迭代、数据分布特征变化、热点变化、数据库版本升级等持续动态变化,这些都使得SQL优化如同三餐般不可或缺。
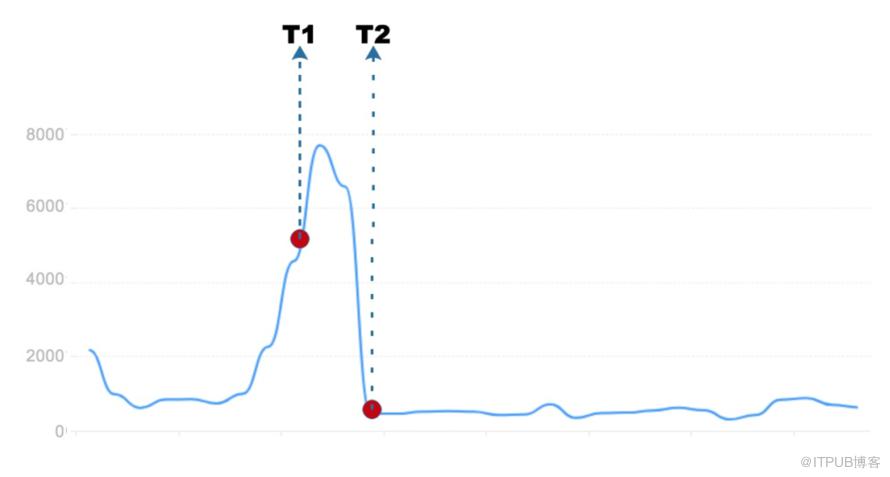
看似相同的过程,但每次都充满不一样的挑战:如何利用综合手段实现快速准确的问题定位?例如问题SQL,仅仅从慢日志中分析是远远不够的。依据数据库领域专家经验或工具辅助,如何精准地识别瓶颈点,得出修复/优化建议?如何全面地评估优化效果、影响面(包括副作用,如对相关SQL,写操作的影响等),做上线前的安全评估?对于复杂的部署(如大规模的分库分表场景),如何选择灰度策略、变更窗口、安全稳妥地推进线上变更?如何持续的跟踪效果,做到万无一失?除此之外,我们还要考虑两个重要的时间点,如下图所示,一个简单的慢SQL趋势,T1代表我们发现数据库实例性能异常的时间点,从此刻开始着手慢SQL的优化,T2是优化过程完毕时间点,实例恢复常态。在传统的优化处理中,这一过程一般完全依赖人力驱动,常常会暴露出两个方面的严重不足:
- T1过于偏后,即异常发现不及时、响应不及时,即使发现时,问题可能已堆积多时,重病已缠身,已处在故障的边缘;
- T2-T1 所代表的处理时间过长,一方面严重影响用户体验,另一方面大大增加故障风险。
除了上述的两个问题, 我们还面临着另外两个更为严峻的挑战:
- 如何实现持续优化?在第一时间发现问题及时优化,避免问题积累,保证稳定的同时保持数据库实例持续处在最佳运行状态;
- 如何缩短处理时长,最大限度减少影响,采用综合治理手段保证数据库实例稳定性,实现标本兼治?
传统方式依赖人力驱动,这两方面的局限性会显得尤为突出,常常处于故障驱动、疲于应对、四处救火的状态。随着业务规模发展,实例规模扩大,所有这些问题也随之被放大,并且大概率会进入即使投入更多人力也没有办法解决的恶性循环状态。破解之道
自动SQL优化服务是阿里云数据库自治服务(DAS)中最为核心服务之一,以自优化的自治能力实现SQL优化的闭环。
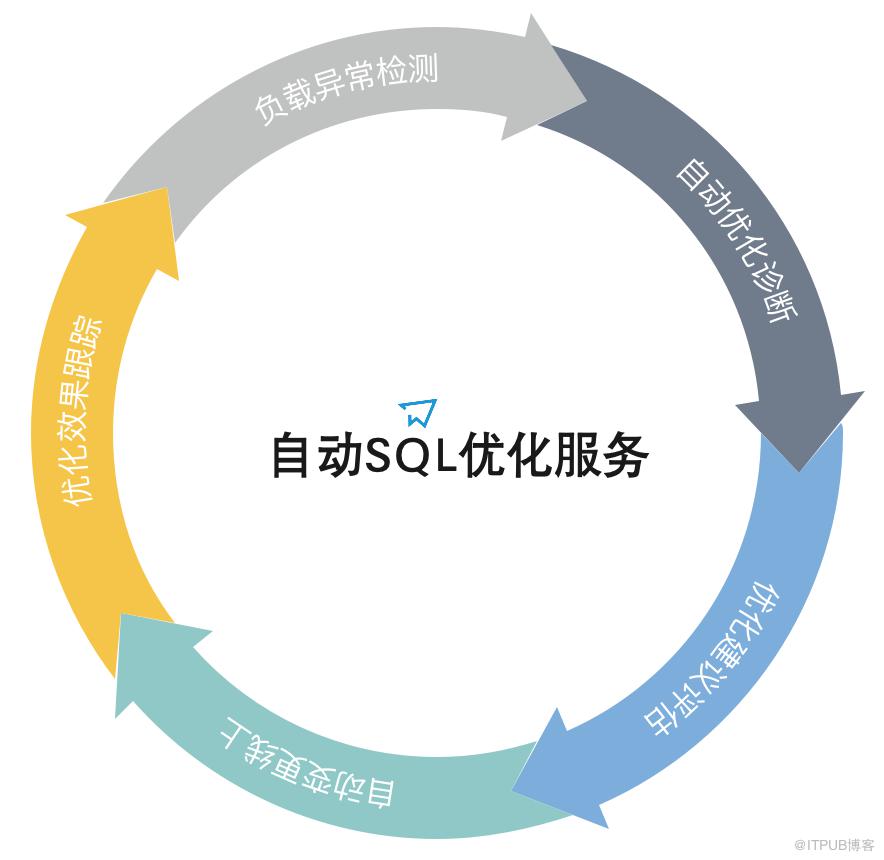
如上图其闭环能力具体体现几个方面:1)负载(Workload)异常检测,识别数据库业务变化,问题SQL的快速识别与定位,如新增慢SQL,性能恶化SQL,不高效SQL等;2)针对问题SQL,自动调用SQL诊断优化服务生成优化建议,如最优索引的创建、SQL语句改写、引擎推荐等等;3)自动完成优化建议风险评估,根据数据库实例负载情况、实例画像自动生成灰度计划,自动编排优化任务;4)自动选取运维窗口,依据灰度计划,完成相关线上变更,目前阶段主要支持索引的自动上线变更;5)针对上线的变更,启动多维度的优化效果跟踪,持续实时全面的性能回归风险评估,符合预期,自动计算优化收益,不符预期,自动回滚。依托该全自动优化闭环,将重人工的被动式优化转变为以智能化为基础的主动式持续优化,最终实现SQL优化的无人值守。试想下,它就如同一群数据库专家7×24小时地守护在你的数据库旁边,不知疲倦,时刻保持数据库系统运行在最佳优化状态。当然,为了上述的目标,实现过程中面临诸多挑战:精准性,如何构建异常检测机制,实现优化时机的精准识别,问题SQL的精准定位;专业性,需要强大的专业性优化诊断后盾,没有有效的专业诊断,优化就无从谈起;安全性,线上无小事,线上变更如何做到安全可控;全面性,优化效果的全面多维度跟踪,全面实时评估,也是保证安全性的要求;联动性,对于复杂的线上问题,有时需要综合治理,如突发的恶性慢SQL问题,DAS的自动SQL限流,自动SQL优化需要形成联动效应,实现问题的标本兼治;规模性,如何构建具备足够扩展性的服务架构,以支撑几十万级、百万级的大规模自动优化。下面将从多个纬度进一步解读DAS的解决方案。
1、实现架构
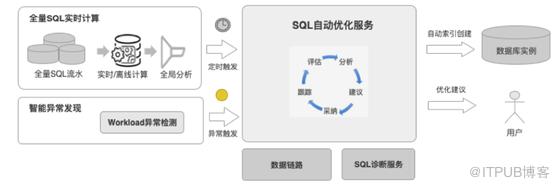
DAS 自动SQL优化是一个基于数据驱动的闭环流程,上图简单描述了整个流程:
- 异常事件,异常事件是触发自动SQL优化的引信,异常事件由DAS事件中心统一管理,异常事件产生自实时异常检测、离线分析、workload检测、告警系统等等。
- 诊断发起:自动SQL优化服务从事件中心收到异常事件后,会对实例进行初步判断,向诊断引擎发起诊断请求并处理诊断结果(一条或多条建议),完成有效性评估,生成新的优化事件发送至事件中心,驱动下一步优化流程。
- 建议推送:用户进入DAS“自治中心”,在未开启全自治模式下,用户可以选择是否接受优化建议,在自主决策下触发后续自动化优化流程;
- 变更上线:选择运维窗口期,下发变更命令,并确认执行情况;
- 效果跟踪和衡量:当优化建议生效后,决策引擎会启动跟踪任务,对被优化的SQL及相关SQL进行性能跟踪,如果性能出现衰退,则自动回滚。通常跟踪24小时后,如无回滚则计算收益。
2、问题发现
SQL优化支持多种场景的SQL异常发现,概况起来为以下三种:
- 定时触发
常规性在运维窗口期,定期对用户实例发生的慢SQL进行离线分析,发起SQL优化。
- 部分SQL性能恶化触发
Workload异常检测算法会实时发现性能恶性SQL,触发SQL自动优化。对于复杂的线上问题,自动SQL优化和DAS的自动SQL限流会形成联动效应,发起SQL自动优化,相关详情请参见:《业务异常只能看着数据库崩溃?看看应急处理利器——自动SQL限流》
- 实例workload变化触发
随着业务SQL的上线和下线,数据库负载、数据量发生变化,现有索引不能很好匹配当前业务的性能要求,发起实例Workload层面的诊断优化。
3、诊断能力
DAS的SQL诊断优化服务是自动SQL优化强大后盾,它采用基于代价模型方式,也就是采用和数据库优化器相同的方式去思考优化问题,最终会以执行代价的方式量化评估所有的可能推荐候选项,最终作出可靠推荐。该服务已在阿里巴巴集团内部稳定运行将近3年多时间,日平均诊断量在5万左右,支撑着整个集团业务应用的SQL优化,3年多来,SQL诊断成功率保持在98%以上,针对慢SQL的推荐率保持在75%以上。相关详情请参见:《耗时又繁重的SQL优化,以后就都交给TA吧!》
4、安全变更
安全变更体现在变更前的安全检查、灰度的变更策略、变更后的性能跟踪。安全检查:为降低风险,变更仅发生在运维窗口期,同时我们会进行主备延迟、实例负载和表空间判断,各指标都在安全范围内时才进行变更。灰度的变更策略:如大量分库分表场景,为降低风险,自动生成灰度计划,分批变更。变更过程中,系统会监控实例的主备延迟,一旦延迟超过阈值,立刻暂停该库的全部索引变更任务,并保障每个库仅允许一个变更任务执行。效果评估:效果评估算法会对被优化的SQL及相关SQL模板进行性能跟踪,避免出现性能恶化导致故障。性能跟踪的算法基于决策树模型,对SQL模板优化后的性能指标与优化前进行对比,综合判断SQL模板在该时刻是否发生了性能衰减。业务往往是以天为周期变化,默认跟踪时间为24小时,没有回滚,则认为本次优化成功,并计算实际优化收益。久经考验
DAS的自动SQL优化服务云上发布前,已在阿里巴巴集团内部稳定无故障运行将近2年多时间,截止到2020年4月,自动SQL优化已累计优化超4200万慢SQL,集团全网慢SQL下降92%左右。
更为重要的是,自动SQL优化服务已经构建了有效的主动式分析,反馈系统,线上失败案例,自动优化中的回滚案例会自动沉淀到案例系统,时刻不停地驱动着自动优化闭环、诊断服务在快速迭代中成长。