

Anaconda 是数据科学家、IT 专业人员和业务领导者的数据科学平台。它是 Python、R 等的分布。凭借 300 多个数据科学软件包,它很快成为任何项目的最佳平台之一。在本教程中,我们将讨论如何将 Anaconda 用于 Python 编程。以下是此博客中讨论的主题:
- 阿纳康达简介。
- 安装和设置。
- 如何在 Anaconda 中安装 Python 库?
- 阿纳康达导航器。
- 用例:
- Python 基础知识。
- 分析。
- 机器学习和 AI.
阿纳康达简介
Anaconda 是 Python 和R的开源发行版。它用于数据科学、机器学习、深度学习等。随着 300 多个数据科学库的可用性,对于任何程序员来说,在 Anaconda 上为数据科学工作都相当理想。

Anaconda 有助于简化包管理和部署。Anaconda 配备了多种工具,可使用各种机器学习和 AI 算法轻松从各种来源收集数据。它有助于获得易于管理的环境设置,只需单击一个按钮即可部署任何项目。
现在,我们知道 Anaconda 是什么,让我们尝试了解如何安装它,并设置一个环境来在我们的系统上工作。
安装和设置
要安装阿纳康达,你可以在这里。
下载页面
选择适合您的版本,然后单击下载。完成下载后,打开安装程序。

按照设置中的说明进行操作。不要忘记单击将 Anaconda 添加到路径环境变量

完成安装后,打开 Anaconda 提示符并键入 jupyter notebook 。
 阿纳康达提示
阿纳康达提示
您将看到如下图所示的窗口。

现在,我们已经知道如何使用 anaconda 为 python,让我们来看看我们如何可以在 anaconda 中为任何项目安装各种库。
在 Anaconda 中安装 Python 库
打开 Anaconda 提示符并检查库是否已安装。
检查 NumPy 是否已安装
由于 numpy 不存在命名模块,我们将运行以下命令来安装 numpy 。

完成安装后,您将获得图像中显示的窗口。
NumPy 安装完成
安装库后,只需尝试再次导入模块以确保。

正如您所看到的,在开始时没有错误,所以这就是我们在 Anaconda 中安装各种库的方式。
阿纳康达导航器
阿纳康达导航器
Anaconda 导航器是一个桌面 GUI,附带 Anaconda 发行版。它允许我们启动应用程序和管理 conda 包和环境,而无需使用命令行。
Python 基础知识

变量和数据类型
变量和数据类型是任何编程语言的构建基块列表、字典、集和元组是 Python 中的集合数据类型。
下面是如何在 Python 中使用变量和数据类型的示例。
#variable declaration
name = "Edureka"
f = 1991
print("python was founded in" , f)
#data types
a = [1,2,3,4,5,6,7]
b = {1 : 'edureka' , 2: 'python'}
c = (1,2,3,4,5)
d = {1,2,3,4,5}
print("the list is" , a)
print("the dictionary is" , b)
print("the tuple is" , c)
print("the set is " , d)运营商
Python 中的运算符用于值或变量之间的操作。Python 中有七种类型的运算符。
- 分配运算符。
- 算术运算符。
- 逻辑运算符。
- 比较运算符。
- 按位运算符。
- 成员资格运算符。
- 标识运算符。
下面是在 Python 中使用几个运算符的示例。
a = 10
b = 15
#arithmetic operator
print(a + b)
print(a - b)
print(a * b)
#assignment operator
a += 10
print(a)
#comparison operator
#a != 10
#b == a
#logical operator
a > b and a > 10
控制语句
语句(如 if else 、 、 break continue )用作控制语句,以获得最佳结果。我们可以在 Python 中的循环中使用这些语句来控制结果。下面是一个示例,用于演示如何使用控件和条件语句。
name = 'edureka'
for i in name:
if i == 'a':
break
else:
print(i)功能
Python 函数以高效的方式提供代码可重用性,我们可以为问题语句编写逻辑并运行一些参数以获取最佳解决方案。下面是一个示例,用于如何在 python 中使用函数。
def func(a):
return a ** a
res = func(10)
print(res)类和对象
由于 Python 支持面向对象的编程,因此我们也可以处理类和对象。下面是一个示例,举例说,我们可以在 python 中处理类和对象。
class Parent:
def func(self):
print('this is parent')
class Child(Parent):
def func1(self):
print('this is child')
ob = new Child()
ob.func()以下是 Python 中的一些基本概念。现在,谈到 Anaconda 中更大的包支持,我们可以与许多库合作。让我们来看看如何使用 python anaconda 进行数据分析。
分析
数据挖掘和分析工作流
这些是数据分析中涉及的某些步骤。让我们来看看数据分析在anaconda和我们可以使用的各种库中是如何工作的。
收集数据
数据收集与在程序中加载 CSV 文件一样简单。然后,我们可以利用相关数据来分析数据中的特定实例或条目。以下是在程序中加载 CSV 数据的代码。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('filename.csv')
print(df.head(5))
数据集的前五行
下面是我们如何根据要求筛选数据的示例。

print(df.isnull().sum())
#this will give the sum of all the null values in the dataset.
df1 = df.dropna(axis=0 , how= 'any')
#this will drop rows with null values
我们也可以删除空值。

框图
sns箱形图(x_df_”工资范围到])


散点图
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(16,8))
ax.scatter(df['Salary Range From'] , df['Salary Range To'])
ax.set_xlabel('Salary Range From')
ax.set_ylabel('Salary Range TO')
plt.show()
可视 化
一旦我们根据要求更改了数据,就有必要分析这些数据。实现此情况的一种方法是可视化结果。更好的可视化表示有助于对数据投影进行最佳分析。
下面是一个可视化数据的示例:
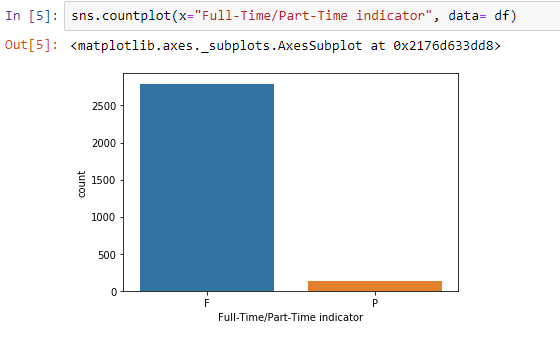 全职员工与兼职工人的条形图
全职员工与兼职工人的条形图
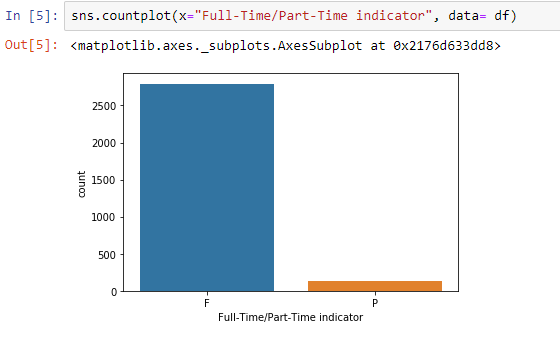 全职员工与兼职工人的条形图
全职员工与兼职工人的条形图


import matplotlib.pyplot as plt
fig = plt.figure(figsize = (10,10))
ax = fig.gca()
sns.heatmap(df1.corr(), annot=True, fmt=".2f")
plt.title("Correlation",fontsize=5)
plt.show()
分析
可视化后,我们可以对各种绘图和图形进行分析。假设我们正在处理作业数据,通过查看某个区域中特定作业的可视化表示形式,我们可以找出特定域中的作业数。
通过以上分析,我们可以假设以下结果
- 与全职工作相比,数据集中的兼职作业数量非常少。
- 而兼职工作不到500个,全职工作超过2500个。
- 在此基础上,可以构建预测模型。
有什么问题吗?在本文对 Anaconda Python 的评论中提及它们,我们将尽快与您回此。


