
在任何分析项目中,原始的数字表格往往无法完整地反映实际情况。通过将数据转化为我们大脑能够快速理解的视觉形式,可视化工具能够简化数据的复杂性,从而突出那些在原始数据中可能被忽略的趋势、异常值以及市场格局的变化。
这一点在金融和交易领域尤为重要,因为清晰的可视化结果能够帮助人们发现潜在的风险、机会及规律,而这些因素会直接影响关于持仓规模、交易时机及信心水平的决策。
今天,我们将利用FMP API来分析盈利数据:提取近1000只股票的各类公告信息、业绩意外情况以及股价反应,从而找出盈利公布后股票价格走势中的可操作性规律。
具体来说,我们将构建以下内容:
-
行业热力图:按行业或市值区间划分,展示盈利公布后3/10天内股价反应最强烈的股票。
-
每股收益散点图
:分析每股收益超预期是否能够带动股价上涨,结果会以不同颜色区分不同行业,并附有回归分析结果。
-
收益分布曲线图
:按行业和市值区间显示盈利公布后3天内的股价波动情况。
-
大型科技股时间序列图
:追踪AAPL、MSFT、NVDA等大型科技股在盈利公布后的价格走势变化。
-
月度季节性分析
:揭示盈利公布后股价回报或业绩意外情况中存在的周期性规律。
-
市场格局对比图
:分析在不同市场环境下,各行业的表现稳定性。
学习内容涵盖:
先决条件
要顺利完成这个学习任务,你需要熟悉Python语言以及pandas库中的基本数据操作功能。
本教程以代码实现为核心内容。我会重点讲解分析流程及图表所揭示的信息,但不会详细解释每一行Python代码。因此,你需要具备阅读pandas代码、处理循环结构以及理解基本绘图逻辑的能力,这样才能顺利跟随学习步骤进行操作。
你需要准备以下工具:
-
Python 3.10或更高版本
-
金融建模预备API密钥
-
已安装pandas、numpy、matplotlib、seaborn、scipy等库
- 足够的计算资源以及耐心,以便在庞大的股票样本集上运行相关代码
数据提取
在本文的第一部分,我们需要收集进行可视化分析所需的所有数据。通过使用FMP的股票筛选API,我们将获取纳斯达克的股票信息。第一次调用该API会返回1,000只股票的信息。
import requests
import pandas as pd
import numpy as np
import json
from datetime import datetime, timedelta
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
token = '您的FMP令牌'
url = f'https://financialmodelingprep.com/stable/company-screener'
querystring = {"apikey":token,"country":"US", "exchange": "NASDAQ", "isActiveTrading": True, "isEtf": False, "isFund": False}
resp = requests.get(url, querystring).json()
df_universe = pd.DataFrame(resp)
df_universe = df_universe[df_universe['exchangeShortName'] == 'NASDAQ']
df_universe
这样我们就得到了1,000只股票的信息!接下来,我们会根据这些股票的市值将它们分成不同的组别,以便后续能更清楚地分析数据结果,并且我们只会保留四列必要的信息:股票代码、公司名称、市值以及所属行业。
bins = [0,
250_000_000, # 2.5亿美元
2_000_000_000, # 20亿美元
10_000_000_000, # 100亿美元
200_000_000_000,# 200亿美元
float("inf");
labels = ["微型", "小型", "中型", "大型", "巨型"]
df_universe["marketCap"] = pd.cut(df_universe["marketCap"], bins=bins, labels=labels, right=False)
df_universe = df_universe[['symbol', 'companyName', 'marketCap', 'sector']]
df_universe
现在,我们需要使用FMP的收益报告API来获取这些股票的收益数据。我们将遍历每一只股票,收集该接口提供的所有收益信息。
symbols = df_universe['symbol'].to_list()
all_dfs = []
for symbol in symbols:
url = f"https://financialmodelingprep.com/stable/earnings?symbol={symbol}"
params = {"apikey": token}
resp = requests.get(url, params=params)
if resp.status_code != 200:
print(f"错误信息:{symbol} - 状态码:{resp.status_code},内容:{resp.text}")
continue
data = resp.json()
if not data:
print(f"没有找到{symbol}的相关数据")
continue
df_symbol = pd.DataFrame(data)
df_symbol["symbol"] = symbol
all_dfs.append(df_symbol)
# 将所有股票的收益数据合并成一个DataFrame
df_earnings = pd.concat(all_dfs, ignore_index=True)
df_earnings = df_earnings.dropna(subset=['epsActual', 'epsEstimated', 'revenueActual','revenueEstimated'])
df_earnings
接下来,我们将计算这些股票的收益和营收的变动幅度,并将其转化为百分比形式,这样我们就可以进行有意义的比较了!我们只会保留2010年以后的数据。
df_earnings["eps_surprise"] = ((df_earnings["epsActual"] - df_earnings["epsEstimated"]) /
abs(df_earnings["epsEstimated"]) * 100).round(2)
df_earnings["revenue_surprise"] = ((df_earnings["revenueActual"] - df_earnings["revenueEstimated"]) /
abs(df_earnings["revenueEstimated"]) * 100).round(2)
df_earnings = df_earnings[['symbol', 'date', 'eps_surprise', 'revenue_surprise']]
df_earnings["date"] = pd.to_datetime(df_earnings["date"])
df_earnings = df_earnings[df_earnings["date"] > "2009-12-31"]
最后,作为收集可视化所需数据的最后一步,我们将使用FMP的历史指数完整图表API,遍历数据框中的所有股票,获取这些股票的历史每日价格,并计算在财报发布前3天和后10天内这些股票的回报率。
unique_symbols = df_earnings["symbol"].unique()
price_results = []
print(f"正在处理{len(uniquesymbols)}个股票......")
for symbol in unique_symbols:
# 获取这些股票的全部历史价格数据
url = f"https://financialmodelingprep.com/stable/historical-price-eod/full"
params = {"apikey":token, "symbol":symbol, "from":'2009-10-01'}
resp = requests.get(url, params=params)
if resp.status_code != 200:
print(f"处理{symbol}时出现错误:{resp.status_code}")
continue
data = resp.json()
hist_df = pd.DataFrame(data)
hist_df["date"] = pd.to_datetime(hist_df["date"])
hist_df = hist_df.sort_values("date").reset_index(drop=True)
# 找到与该股票相关的财报记录
earnings_symbol = df_earnings[df_earnings["symbol"] == symbol].copy()
for _, row in earnings_symbol.iterrows():
earn_date = pd.to_datetime(row["date")).date()
# 计算3天窗口内的数据
pre3_mask = (hist_df["date"].dt.date < earn_date) & \
(hist_df["date"].dt.date >= earn_date - timedelta(days=10))
pre3 = hist_df[pre3_mask].tail(3)
post3_mask = (hist_df["date").dt.date > earn_date) & \
(hist_df["date"].dt.date <= earn_date + timedelta(days=10))
post3 = hist_df[post3_mask].head(3)
pre3_start = pre3["close"].iloc[0] if len(pre3) >= 3 else None
pre3_end = pre3["close"].iloc[-1] if len(pre3) >= 3 else None
post3_end = post3["close"].iloc[-1] if len(post3) >= 3 else None
pct_pre_3d = ((pre3_end - pre3_start) / pre3_start * 100) if pre3_start and pre3_end else None
pct_post_3d = ((post3_end - pre3_start) / pre3_end * 100) if pre3_end and post3_end else None
# 计算10天窗口内的数据
pre10_mask = (hist_df["date"].dt.date < earn_date) & \
(hist_df["date"].dt.date >= earn_date - timedelta(days=20))
pre10 = hist_df[pre10_mask].tail(10)
post10_mask = (hist_df["date"].dt.date > earn_date) & \
(hist_df["date"].dt.date <= earn_date + timedelta(days=20))
post10 = hist_df[post10_mask].head(10)
pre10_start = pre10["close"].iloc[0] if len(pre10) >= 10 else None
pre10_end = pre10["close"].iloc[-1] if len(pre10) >= 10 else None
post10_end = post10["close"].iloc[-1] if len(post10) >= 10 else None
pct_pre_10d = ((pre10_end - pre10_start) / pre10_start * 100) if pre10_start and pre10_end else None
pct_post_10d = ((post10_end - pre10_start) / pre10_end * 100) if pre10_end and post10_end else None
price_results.append({
"symbol": symbol,
"earn_date": earn_date,
"month": earn_date.month,
"pct_pre_3d": round(pct_pre_3d, 2) if pct_pre_3d else None,
"pct_post_3d": round(pct_post_3d, 2) if pct_post_3d else None,
"pct_pre_10d": round(pct_pre_10d, 2) if pct_pre_10d else None,
"pct_post_10d": round(pct_post_10d, 2) if pct_post_10d else None,
"eps_surprise": row["eps_surprise"],
"revenue_surprise": row["revenue_surprise"]
})
df_earnings = pd.DataFrame(price_results)
df_earnings.dropna inplace=True)
df_earnings = df_universe.merge(df_earnings, on="symbol")
df_earnings
如您所见,在代码的末尾,我们还将最初的数据集合并到了一起,因此现在所有的信息,比如名称、市值以及所属行业,都集中在了一个数据集中。
利用图表和可视化工具进行数据分析
行业热力图
首先,我们将展示按行业和市值类别划分的平均3天收益后回报的行业热力图。这种直观的可视化方式能够突出那些反应最为强烈的领域,帮助交易者迅速找到适合用于盈利策略的高阿尔法值行业和市值区间。
# 计算平均3天收益后回报及每股收益惊喜幅度
agg = (
df_earnings
.dropna(subset=['pct_post_3d', 'pct_post_10d', 'eps_surprise', 'marketCap', 'sector'])
.groupby(['sector', 'marketCap'])
.agg(
avg_post3d=(' pct_post_3d', 'mean'),
avg_post10d>('pct_post_10d', 'mean'),
avg_eps_surprise=('eps_surprise', 'mean')
)
.reset_index()
)
# 绘制热力图:平均3天收益后回报
heatmap_3d = agg.pivot(index='sector', columns='marketCap', values='avg_post3d')
plt.figure(figsize=(12, 8))
sns.heatmap(
heatmap_3d,
annot=True,
fmt('.2f',
cmap='RdYlGn',
center=0,
linewidths=0.5,
linecolor='grey'
)
plt.title('按行业和市值区间划分的平均3天收益后回报')
plt.xlabel('市值区间')
plt.ylabel('行业')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()

消费周期类行业和材料行业表现非常好,中小市值股票的平均回报率超过了1.1%;房地产行业也表现良好,其中中小市值股票的回报率更是高达4.0%;能源和金融行业则保持稳定,回报率接近于零。而科技行业的收益增长幅度相对较小,低于1.1%,这表明大型科技公司的盈利报告可能不会带来立竿见影的积极影响。
在分析了3天期的热力图之后,我们现在将进一步研究按行业和市值类别划分的平均10天收益后回报的行业热力图。这种分析方式延长了时间跨度,有助于我们了解市场动量的持续性,从而判断哪些行业能够维持或逆转短期的市场反应。
# 绘制平均10天收益后回报的热力图
heatmap_10d = agg.pivot(index='sector', columns='marketCap', values='avg_post10d')
plt.figure(figsize=(12, 8))
sns.heatmap(
heatmap_10d,
annot=True,
fmt('.2f',
cmap='RdYlGn',
center=0,
linewidths=0.5,
linecolor='grey'
)
plt.title('按行业和市值区间划分的平均10天收益后回报')
plt.xlabel('市值区间')
plt.ylabel('行业')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
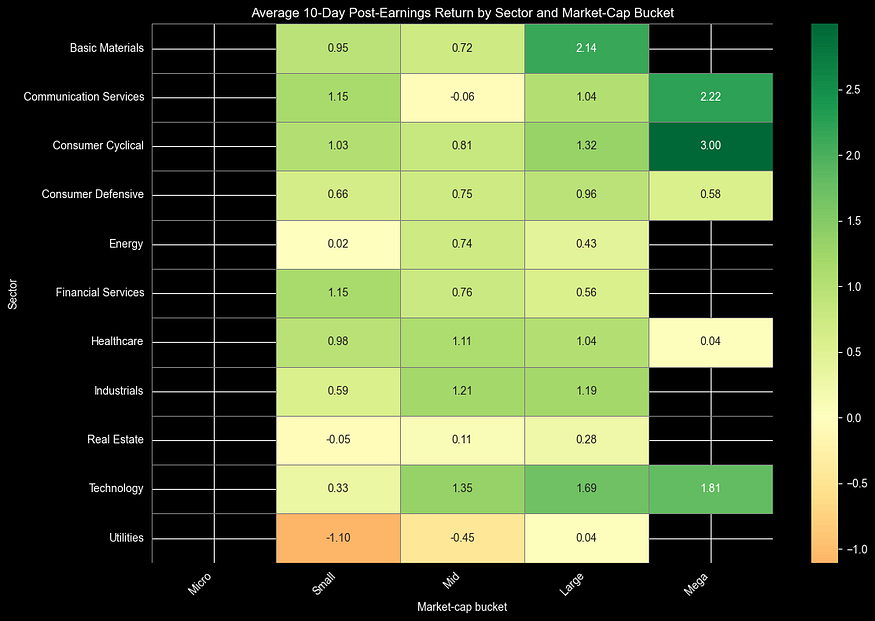
消费板块中的周期性股票表现尤为突出,其涨幅峰值达到了3.2%(尤其是那些规模较大的公司);而工业和医疗保健板块的中大型公司股票也呈现出稳定的上涨趋势,涨幅约为1.1%。房地产板块在经历了连续三天的强劲走势后,涨幅有所回落。科技板块中,那些规模较大的科技公司的股价也出现了小幅上涨(涨幅为1.8%),但总体而言,其活跃程度仍低于周期性行业。
大型科技股时间序列图
通过进一步分析这些热力图,我们现在来看一下大型科技股的时间序列数据。该图表展示了AAPL、MSFT、NVDA等几只大型科技股在财报发布后10天内的股价走势。
在这里,气泡图是一种非常合适的可视化工具,因为它能够同时展示多种信息:x轴代表财报发布日期,y轴代表财报发布后10天内的股价涨幅,气泡的大小反映了每股收益意外变动的幅度,而颜色则说明了这种变动是超出预期还是低于预期。这样一来,我们就能轻松地识别出那些异常的数据点,并了解是否某些重大的业绩变化确实会导致股价出现较大的波动。
# 定义一些大型科技股的代码
tech_tickers = ['AAPL', 'MSFT', 'NVDA', 'AMZN', 'GOOG/GOOGL', 'META']
# 过滤出这些大型科技股的相关数据
df_tech = (
df_earnings[df_earnings['symbol'].isin(tech_tickers)]
.dropna(subset=['earn_date', 'pct_post_10d', 'eps_surprise'])
.sort_values('earn_date')
.assign(
earn_date=lambda x: pd.to_datetime(x['earn_date'])
)
)
# 创建时间序列图:以财报发布日期为横轴,财报发布后10天内的股价涨幅为纵轴,气泡的大小和颜色则反映每股收益意外变动的幅度
plt.figure(figsize=(14, 8))
# 绘制散点图
scatter = plt.scatter(
df_tech['earn_date'],
df_tech['pct_post_10d'],
s=np.abs(df_tech['eps_surprise']) * 50 + 20, # 根据每股收益意外变动的幅度来确定气泡的大小
c=df_tech['eps_surprise'],
cmap='RdYlBu_r',
alpha=0.7,
edgecolors='black',
linewidth=0.5
)
plt.colorbar(scatter, label='每股收益意外变动幅度 (%)')
plt.xlabel('财报发布日期')
plt.ylabel('财报发布后10天内的股价涨幅 (%)')
plt.title('大型科技股:财报发布后10天内的股价走势与时间的关系\n气泡的大小和颜色反映每股收益意外变动的幅度')
plt.grid(True, alpha=0.3)
# 添加趋势线
z = np.polyfit(pd.to_numeric(df_tech['earn_date'], df_tech['pct_post_10d'], 1)
p = nppoly1d(z)
plt.plot(df_tech['earn_date'], p(pd.to_numeric(df_tech['earn_date'])), "r--", alpha=0.8, linewidth=2, label=f'趋势线:{z[0]:.3f}x + {z[1]:.1f}')
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()

2018年左右那个巨大的红色气泡,几乎可以肯定代表的是AAPL在2018年第四季度的业绩不佳(具体公告发布于2019年1月,但相关数据属于2018财年的第四季度)。这个气泡之所以如此显眼,是因为:
-
气泡的大小反映了每股收益意外变动的幅度非常大(苹果公司大幅下调了业绩预期,实际业绩比预期低了约10%)
-
红色
表示这一业绩变动是负面的
-
在图表中的位置较低
,说明财报发布后10天内的股价涨幅非常小(大约为-10%左右)
这就是苹果那次臭名昭著的“iPhone需求预警”,正是这一事件引发了2019年1月的市场恐慌。这个例子很好地说明了:一个异常事件是如何导致整个趋势线向下移动的。
每股收益意外值散点图
在确定了主要的科技行业发展趋势之后,我们现在来看看每股收益意外值散点图。这种图表用于验证一个简单的假设:即业绩超出预期是否会导致股价上涨,而业绩低于预期是否会导致股价下跌?我们在x轴上标注每股收益的意外值,在y轴上标注财报发布后的股价回报率,然后添加一条回归线来显示两者之间的平均关系。
# 准备数据:删除缺失值,并在需要时转换earn_date字段(此处未使用)
df_plot = (
df_earnings
.dropna(subset=['eps_surprise', 'pct_post_3d', 'pct_post_10d', 'sector'])
.copy()
)
# 1. 散点图:每股收益意外值与3天后的股价回报率,按行业分类显示颜色
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.scatterplot(
data=df_plot,
x='eps_surprise',
y='pct_post_3d',
hue='sector',
alpha=0.6,
s=40
)
# 整体回归线
slope, intercept, r_value, p_value, std_err = stats.linregress(df_plot['eps_surprise'], df_plot['pct_post_3d'])
line = slope * df_plot['eps_surprise'] + intercept
plt.plot(df_plot['eps_surprise'], line, 'red', linestyle='--', linewidth=2,
label=f'y = {slope:.3f}x + {intercept:.2f}\nR²={r_value**2:.3f}')
plt.xlabel('每股收益意外值 (%)')
plt.ylabel('3天后的股价回报率 (%)')
plt.title('按行业划分的每股收益意外值与3天后股价回报率的关系')
plt.legendbbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, alpha=0.3)
# 2. 散点图:每股收益意外值与10天后的股价回报率,按行业分类显示颜色
plt.subplot(1, 2, 2)
sns.scatterplot(
data=df_plot,
x='eps_surprise',
y='pct_post_10d',
hue='sector',
alpha=0.6,
s=40
)
# 整体回归线
slope10, intercept10, r_value10, p_value10, std_err10 = stats.linregress(df_plot['eps_surprise'], df_plot['pct_post_10d'])
line10 = slope10 * df_plot['eps_surprise'] + intercept10
plt.plot(df_plot['eps_surprise'], line10, 'red', linestyle='--', linewidth=2,
label=f'y = {slope10:.3f}x + {intercept10:.2f}\nR²={r_value10**2:.3f}')
plt.xlabel('每股收益意外值 (%)')
plt.ylabel('10天后的股价回报率 (%)')
plt.title('按行业划分的每股收益意外值与10天后股价回报率的关系')
plt.legendbbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 可选:按行业分类的相关性汇总表
corr_3d = df_plot.groupby('sector')[['eps_surprise', 'pct_post_3d]].corr().unstack().xs('pct_post_3d', level=1, axis=1)['eps_surprise']
corr_10d = df_plot.groupby('sector')[['eps_surprise', 'pct_post_10d')).corr().unstack().xs('pct_post_10d', level=1, axis=1]['eps_surprise']
corr_df = pd.DataFrame({
'Corr.eps_3Day': corr_3d.round(3),
'Corr.eps_10Day': corr_10d.round(3)
}).sort_values('Corr.eps_10Day', ascending=False)
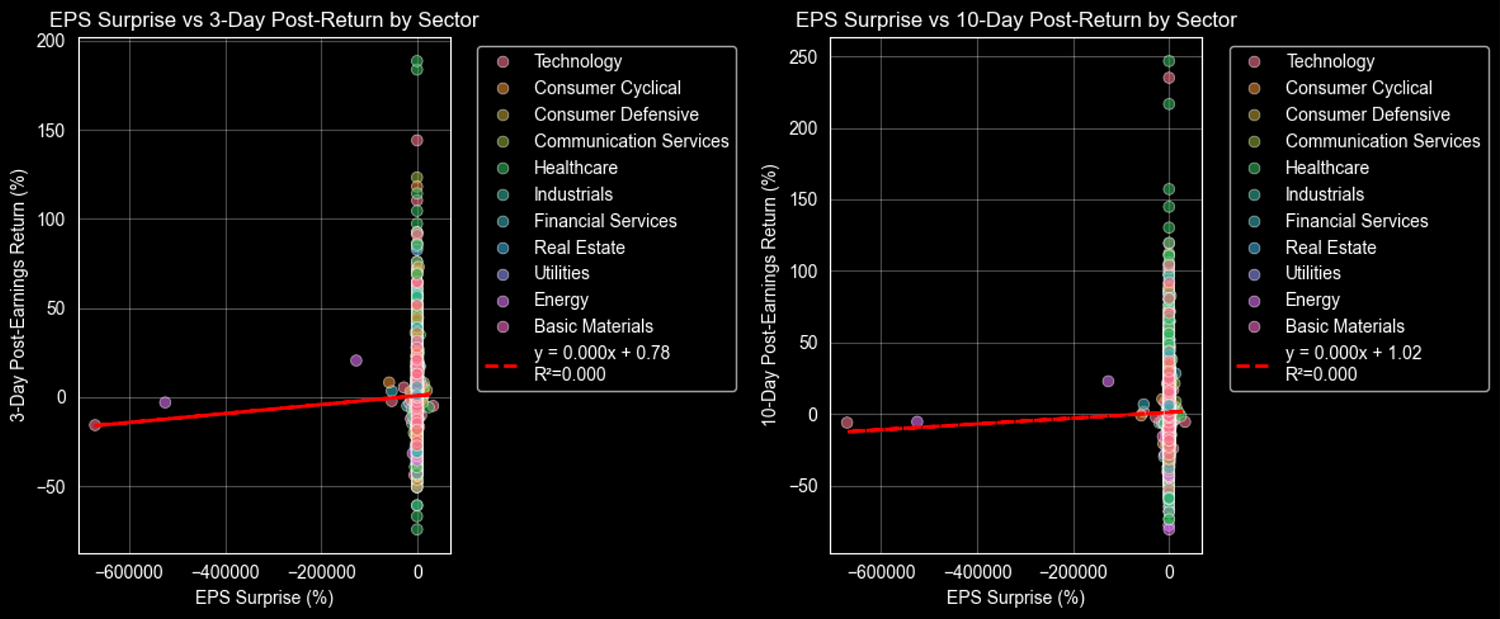
这条红色虚线趋势线展示了这种典型的关系:每当每股收益的实际表现超出预期1%时,股票在3到10天内通常会上涨0.05%到0.1%。这种平缓的上升趋势说明,虽然意外的好消息确实能带来一定的涨幅,但它们并不能确保股价会出现大幅波动。
你会发现,属于消费周期类行业的股票,其走势主要集中在右上角(即业绩超出预期后股价会上涨);而房地产行业的股票则表现出更明显的上涨趋势。线条周围较大的波动范围说明,除了这些意外因素之外,还有许多其他因素会影响股票的走势。
收益分布图
热力图显示的是平均值,但平均值往往无法反映实际风险。而 violin 图则能展示收益的完整分布情况,包括收益幅度的大小以及收益分布的尾部是否集中。在这里,我们按照行业和市值区间来绘制了股票在盈利公告后3天内的收益分布图。
# 准备数据
df_plot = (
df_earnings
.dropna(subset=['pct_post_3d', 'sector', 'marketCap'])
.copy()
)
# 1. violin 图:按行业划分的盈利公告后3天内的收益分布
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
sns.violinplot(
data=df_plot,
x='sector',
y='pct_post_3d',
inner='quartile',
palette='Set2'
)
plt.title('按行业划分的盈利公告后3天内的收益分布')
plt.xlabel('行业')
plt.ylabel('盈利公告后3天内的收益百分比')
plt.xticks(rotation=45, ha='right')
plt.grid(True, alpha=0.3)
# 2. violin 图:按市值区间划分的盈利公告后3天内的收益分布
plt.subplot(1, 2, 2)
sns.violinplot(
data=df_plot,
x='marketCap',
y='pct_post_3d',
inner='quartile',
palette='Set3'
)
plt.title('按市值区间划分的盈利公告后3天内的收益分布')
plt.xlabel('市值区间')
plt.ylabel('盈利公告后3天内的收益百分比')
plt.xticks(rotation=45, ha='right')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 总结统计表
summary = df_plot.groupby(['sector', 'marketCap'])['pct_post_3d'].agg(['mean', 'median', 'std', 'count']).round(2)
print("总结统计:按行业和市值区间划分的盈利公告后3天内的收益的平均值/中位数/标准差/数量")
print.summary)
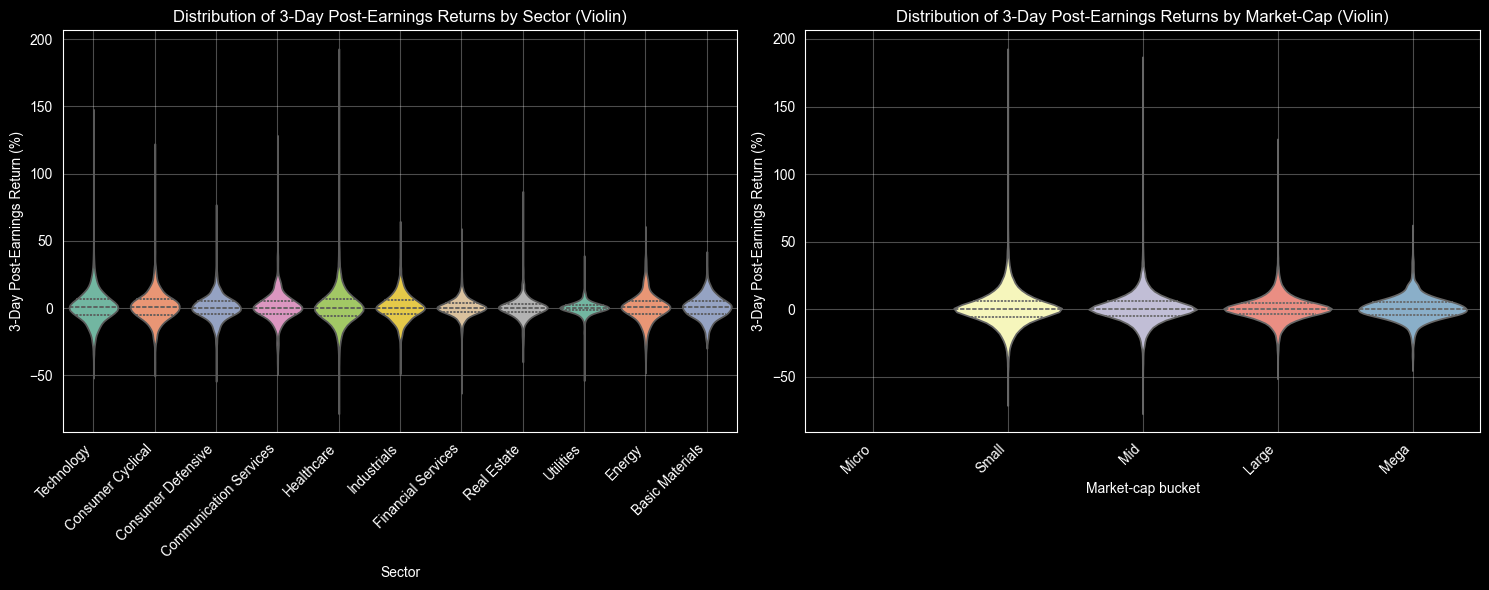
所有的 violin 图都显示,收益值大多集中在零附近,波动幅度也较小(±5%),这说明盈利公告后的市场反应通常比较混乱,没有明显的趋势。由于市场会迅速消化这些预期,因此很难通过这些数据获得可预测的投资机会。消费周期类行业和材料行业的股票偶尔会出现超预期的上涨走势,而小市值股票的波动性最大,这也意味着它们的风险更高,但偶尔也会带来较高的收益。并不是所有的可视化图表都能揭示出“阿尔法效应”;这个例子恰恰说明了这一点——要理解市场规律确实非常困难。
月度季节性因素
在观察到回报率分布接近零这一现象之后,现在让我们通过四个图表来分析月度季节性变化:平均3/10天后的回报率、每股收益的意外变动情况,以及每月发生的各类事件的数量。这些数据能够揭示出一些日历效应以及系统性的季节性偏差,而这些因素即便会导致个体数据的波动较大,仍然会影响投资者进入市场的时机选择。
# 1. 确保“earn_date”是日期类型
df_month = (
df_earnings
.dropna(subset=['earn_date', 'pct_post_3d', 'pct_post_10d', 'eps_surprise'])
.copy()
)
df_month['earn_date'] = pd.to_datetime(df_month['earn_date'])
# 2. 获取月份编号和名称
df_month['month_num'] = df_month['earn_date'].dt.month
df_month['month_name'] = df_month['earn_date'].dt.strftime('%b')
# 3. 按月份汇总各项数据
monthly_agg = (
df_month
.groupby('month_num')
.agg(
pct_post_3d_mean=('pct_post_3d', 'mean'),
pct_post_10d_mean>('pct_post_10d', 'mean'),
eps_surprise_mean>('eps_surprise', 'mean'),
n_obs=('earn_date', 'count')
)
.reset_index()
.sort_values('month_num')
)
# 保持月份顺序和名称的一致性
month_order = monthly_agg['month_num'].tolist()
month_labels = df_month.drop_duplicates('month_num').set_index('month_num')[‘month_name’.reindex(month_order)
monthly_agg['month_name'] = month_labels.values
# 4. 绘制条形图
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('收益公告后回报率的月度季节性变化及每股收益惊喜效应', fontsize=16)
# 3天平均回报率
axes[0, 0].bar(monthly_agg['month_name'], monthly_agg['pct_post_3d_mean'], color='skyblue')
axes[0, 0].set_title('各月份的3天平均收益回报率')
axes[0, 0].set_ylabel('回报率 (%)')
axes[0, 0].grid(alpha=0.3)
# 10天平均回报率
axes[0, 1].bar(monthly_agg['month_name'], monthly_agg['pct_post_10d_mean'], color='lightgreen')
axes[0, 1].set_title('各月份的10天平均收益回报率')
axes[0, 1].set_ylabel('回报率 (%)')
axes[0, 1].grid(alpha=0.3)
# 平均每股收益惊喜效应
axes[1, 0].bar(monthly_agg['month_name'], monthly_agg['eps_surprise_mean'], color='salmon')
axes[1, 0].set_title('各月份的平均每股收益惊喜效应')
axes[1, 0].set_ylabel('每股收益惊喜效应')
axes[1, 0].grid(alpha=0.3)
# 数据观测数量
axes[1, 1].bar(monthly_agg['month_name'], monthly_agg['n_obs'], color='gold')
axes[1, 1].set_title('各月份的收益公告事件数量')
axes[1, 1].set_ylabel('数量')
axes[1, 1].grid(alpha=0.3)
for ax in axes.ravel():
ax.set_xlabel('月份')
ax.tick_params(axis='x', rotation=0)
plt.tight_layout()
plt.show()

1月和10月的3天平均回报率通常最高,约为0.8%,而5月和7月的回报率则较低。10天的趋势也呈现出类似的模式,但波动幅度较小,2月和8月的回报率达到峰值。1月和5月的每股收益惊喜效应略为负值,这可能是由于对比对象较为不利;而7月、8月和12月由于节假日的原因,收益公告事件的数量较少。虽然存在一定的季节性规律,但其影响幅度很小,大约仅为0.5%。
不同市场环境下的情况
最后,在分析了那些细微的月度变化规律之后,我们将研究市场环境对不同行业10天收益表现的影响:会上方会展示热力图,下方则会用条形图来显示各行业的具体数据。这种分析有助于验证之前的研究结果——这些规律在牛市、熊市以及COVID疫情期间是否依然存在——同时也能帮助我们发现市场转换带来的投资机会,以及各种市场环境对行业收益的影响程度。
# 准备数据并提取年份信息
df_regimes = (
df_earnings
.dropna(subset=['earn_date', 'pct_post_10d', 'sector'])
.copy()
)
df_regimes['earn_date'] = pd.to_datetime(df_regimes['earn_date'])
df_regimes['year'] = df_regimes['earn_date'].dt.year
# 定义市场阶段(根据你的数据或市场历史来调整年份划分)
# 例如:牛市(2023-2025年),熊市/过渡期(2022年),新冠疫情时期(2020-2021年)等
def assign_regime(year):
if year >= 2023:
return '牛市(2023年及以后)'
elif year == 2022:
return '熊市(2022年)'
elif 2020 <= year <= 2021:
return '新冠疫情恢复期'
elif 2018 <= year <= 2019:
return '疫情前的时期'
else:
return '更早的阶段'
df_regimes['market_regime'] = df_regimes['year'].apply.assign_regime)
# 1. 数据汇总:按行业和市场阶段计算平均10天收益率
agg_data = (
df_regimes
.groupby(['sector', 'market_regime'])['pct_post_10d']
.agg(['mean', 'count'])
.reset_index()
.query('count >= 5') # 过滤样本数量较少的市场阶段
)
# 2. 可视化展示:首先使用热图进行快速浏览
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
pivot_heatmap = agg_data.pivot(index='sector', columns='market_regime', values='mean')
sns.heatmap(pivot_heatmap, annot=True, fmt='.2f', cmap='RdYlGn', center=0, linewidths=0.5)
plt.title('平均10天收益回报率:行业×市场阶段热图')
# 3. 条形图展示:按市场阶段分类,并按行业进行堆叠显示
plt.subplot(2, 1, 2)
regime_order = agg_data.groupby('market_regime')[‘mean’].mean().sort_values(ascending=False).index
sns.barplot(data=agg_data, x='market_regime', y='mean', hue='sector',
palette='Set2', order=regime_order)
plt.title('按市场阶段划分的平均10天收益率(按行业颜色区分)')
plt.ylabel('10天收益回报率%')
plt.xlabel('市场阶段')
plt.xticks(rotation=45, ha='right')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()
# 5. 总结表格
print("按行业和市场阶段划分的平均收益率(样本数量至少为5个):")
print(agg_data.pivot(index='sector', columns='market_regime', values='mean').round(2))
# 6. 排名:不同市场阶段下表现最佳的/最差的行业
print("\n按市场阶段划分的表现最佳/最差的行业:")
for regime in regime_order:
regime_data = agg_data[agg_data['market_regime'] == regime].sort_values('mean', ascending=False)
print(f"\n{regime}:")
print(regime_data[['sector', 'mean', 'count]].round(2).head(3))
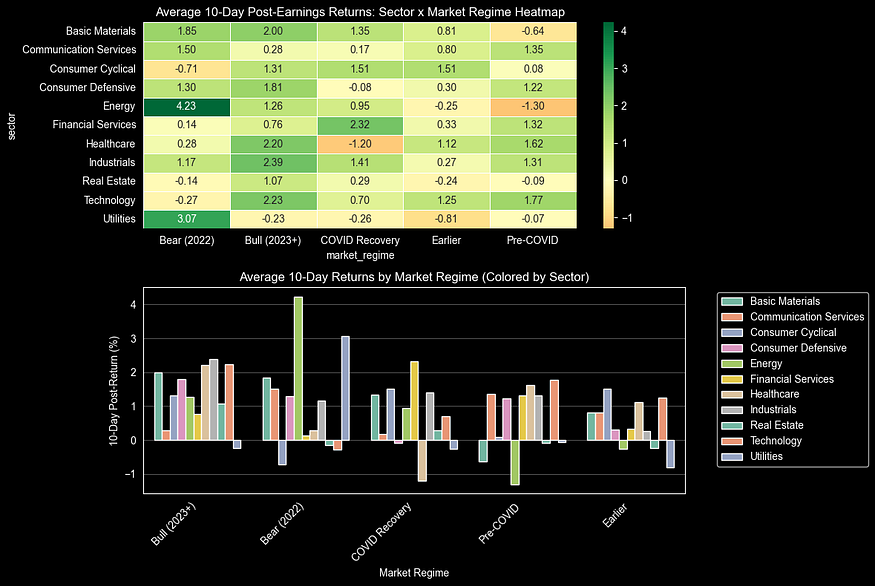
在牛市期间(2023年及以后)和新冠疫情恢复期,消费周期类行业表现良好(收益回报率约为1.5%–2%),但在2022年的熊市中表现不佳。公用事业类行业在新冠疫情之前就已经出现了负收益。图表中的底部数据表明,在新冠疫情期间,整体收益率为正(约1%),其中基础材料和工业类行业的表现最为强劲。当前的牛市环境下这些行业的收益回报率依然为正,但幅度已有所下降。不同市场阶段下,各行业的领先地位会发生变化,并没有哪个行业能始终表现出色。
我们从这些分析中得到了什么?
通过六个相互关联的可视化图表,我们将15年的收益数据转化成了一个清晰且引人入胜的故事。
每个图表都针对某个具体问题进行解读,但结合起来看,它们描绘出了一个更全面的图景:收益意外变化确实会影响市场,但其影响在不同领域和时期是有所差异的。某些行业、阶段或市场环境往往能带来稳定的投资机会,而另一些则不然。
数据向我们展示了以下结论:
-
虽然不存在绝对确定的盈利机会,但特定领域确实存在投资机会:总体而言,市场的效率较高,收益与收益意外变化的关联性较弱,因此回报水平通常接近于零;不过,在不同时间段和市场环境下,消费周期类股票和原材料行业依然具有上涨潜力。因此,选择合适的行业进行投资非常重要。
-
不同的时间窗口会带来不同的投资结果:对于中盘房地产股来说,3天内的市场反应能带来约4%的收益;而对于消费周期类大盘股而言,10天内的市场反应则能使它们获得约3.2%的收益。切勿假设所有市场的反应都会以相同的速度发生。
-
对大型科技股的过度炒作并不会永远持续下去:气泡图显示,从2020年到2022年,AAPL、MSFT和NVDA等公司的股票确实带来了较高的回报,但自那以后这些股票的走势开始下滑,这说明市场对这些股票的热情正在减退。因此,不要去追逐那些曾经被过度炒作的股票。
-
把握市场节奏有助于获得更好的投资收益
:1月和10月,市场在公布收益后往往会出现略高的回报(约0.8%),而7月和8月的流动性通常较低。将季节性因素与行业选择结合起来,才能获得更高的投资收益。
-
不同的市场环境会决定哪些行业会成为赢家
:在COVID疫情恢复期间以及2023年之后的牛市中,消费周期类行业的表现往往不佳,而工业类行业则取得了较好的成绩。并没有所谓的“永远最优秀的行业”,只有目前来看表现最好的行业。因此,要根据当前的市场环境来选择投资对象。
-
具体的操作建议
:在牛市期间,1月份选择中盘至大盘的消费周期类股票进行投资,这样的策略能够结合所有这些有利因素,从而提高投资成功的概率。因为此时行业选择、季节性因素以及市场环境都处于有利的状态。
最后的思考
这个分析案例充分说明了可视化技术在金融领域的重要性:单纯的收益数据和意外变化表格是无法揭示这些规律的。
-
热力图能够立刻显示出哪些行业在市场中表现最佳。
-
各种分析方法也让我们认识到一个残酷的事实:市场的波动往往非常剧烈。因此,不能简单地套用过去的分析方法来预测未来的市场走势。
散点图清楚地展示了收益与收益意外变化之间的弱相关性。
气泡图则记录了大型科技股在整个市场发展过程中的表现变化。
努力解读这些数据所带来的回报是显而易见的:你从被动观察转变为了主动识别市场规律。你不仅能够了解发生了什么,还能知道这些事件发生的时间和地点。在交易和分析中,理解复杂市场的本质往往比掌握一个完美的公式更为重要。
通过可视化的方式讲述故事,就能将数据转化为直观的理解。而基于证据的直觉,每次都能带来比盲目猜测更好的结果。