
你们的团队在第20周为第一批工作空间推出了基于大语言模型的摘要功能,现在发布后的文档也该准备好了。你们需要一个能够向统计专家出示的、具有因果意义的数值作为依据。
问题在于,第二批工作空间仍在等待这一功能的推出。同一周二,整个产品线都进行了重新设计,而第20周恰好也是用户参与度出现上升的时期。如果在第20周之后对这两组工作空间进行比较,就会将这一功能的因果效应与产品的重新设计、季节性因素,以及最初决定哪些工作空间属于第一批推出的标准等因素混在一起来考虑了。
在2026年,大多数企业级SaaS团队都是按照这种方式推出人工智能功能的:一次只为一组工作空间推出,分批进行,遵循预先制定的发布计划。由于没有进行随机分配,因此A/B测试也无法得出准确的因果结论。最终得到的只是一个大家争论不休的数字而已。
我们可以将这种现象称为发布计划陷阱:虽然你有真实的数据和合理的实验设计,但最终的比较结果却是完全无效的。对于那些分批推出人工智能功能的数据科学家来说,这就是导致后续出现错误因果结论的主要原因。
在生成式人工智能功能的测试中,这种模式依然被沿用:假设是这些人工智能功能能够提高用户参与度,而分批推出的方式正是用来验证这一假设的。
然而,这种分批发布的机制实际上破坏了实验设计的科学性。简单的A/B测试假定所有工作空间都是随机分配的,但实际上从未真正进行过这样的随机分配,因此即使实验设计本身没有问题,测量结果也会出现偏差。
差异分析法正是为了解决这个问题而存在的。它通过比较每组工作空间在不同时间点的表现变化,来消除时间趋势的影响,从而得出一个具有因果意义的结论——即便没有进行随机分配,这种方法也能产生可靠的结果。
在本教程中,你将使用差异分析法来测量这一人工智能功能在企业级工作空间中的真实因果效应,并会看到具体的Python代码示例以及相关的合成SaaS产品数据集。
学习完本教程后,你将知道如何进行差异分析法的计算,如何检验其关于“各组变化趋势平行”的假设,以及当这个假设不成立时应该采取什么措施。
目录
为什么A/B测试在分阶段推广模式下会失效
随机分配是使A/B测试成为一种有效的因果分析方法的关键。当你通过抛硬币来决定哪位用户能使用新功能时,实验组与对照组在所有干扰因素(即那些同时影响哪些用户接受实验处理以及最终结果的因素)上都会呈现出相同的分布情况。因此,在分配之后如果出现任何结果差异,这种差异就纯粹是实验处理带来的因果效应,没有其他原因。
然而,在企业级工作环境中分阶段推广这一方法会从三个方面破坏这种随机分配机制:
1. 分阶段的分配方式本身并不具有随机性。
产品团队会选择某些工作环境作为第一阶段进行测试,原因可能包括这些工作环境的管理员参与度最高、用户数量最多,或者它们与客户支持团队的合作最为紧密。而这些因素实际上都会直接影响测试结果。因此,无论是否启用新功能,第一阶段的工作环境本来就会表现出更高的用户参与度。
2>时间顺序的安排会引入时间趋势效应
从第20周(第一阶段启动)到第30周(第二阶段启动),产品的性能会得到提升,用户上手体验也会改善,销售团队也能签下更多的大客户。如果简单地用“第20周之后的用户参与度减去第20周之前的参与度”来进行比较,那么这些因素带来的影响就会与新功能本身的效果混在了一起,导致结果出现偏差。
3>在实验组内部,新功能的采用情况本身也存在选择性
即使在那些被赋予了新功能的工作环境中,也不是所有用户都会使用它。技术能力较强的用户会立即使用,而参与度较低的用户则可能会等待数月才使用。将使用了新功能的用户与没有使用的用户进行比较,就会产生选择偏差——因为在测量结果之前,这两组用户在某些方面就已经存在系统性差异了,而这本来就是随机分配机制所无法避免的问题。
A/B测试假定这三个问题都不存在,但分阶段推广模式却必然会导致这些问题出现。这种简单的比较方法只能得到一个数字,而这个数字实际上反映的只是表面上的用户参与度而已。
差异分析法能解决什么问题
差异分析法用于比较实验组与对照组在一段时间内的结果变化情况。通过将两组的变化量相减,就可以消除所有共同存在的时间趋势因素(比如产品性能的提升、季节性变化等),从而准确得出仅由实验处理带来的效果。
举个具体的例子:假设我们想要对比两个社区中咖啡店的季度营收变化。在第三季度,其中一个社区出现了新的竞争对手,而另一个社区则没有。
虽然这两个社区都面临着相同的市场趋势、当地经济的复苏以及节日消费高峰等因素,但差异分析法可以通过消除两者共有的这些影响因素,从而准确反映出新竞争对手对其中某个社区的具体影响。
分阶段推广模式实际上也建立了完全相同的分析结构:第一阶段被选中的工作环境就相当于那个出现了新竞争者的社区,而第二阶段的工作环境则用于作为对照组进行比较。
数学上,这一现象被表述为一个2×2的表格:行代表不同的组别(实验组、对照组),列代表不同的时间阶段(处理前、处理后),而每个单元格则记录了该组在该时间阶段的平均结果:
-
A = 第1组用户在第20周之前的平均任务完成情况(以咖啡店为例:Q2季度的收入情况,或位于新竞争者进入的社区)
-
B = 第1组用户在第20周之后的平均任务完成情况(以咖啡店为例:Q3季度的收入情况,仍在同一社区)
-
C = 第2组用户在第20周之前的平均任务完成情况(以咖啡店为例:Q2季度的收入情况,位于未受新竞争者影响的社区)
-
D = 第2组用户在第20周之后的平均任务完成情况(以咖啡店为例:Q3季度的收入情况,仍在同一社区)
处理前 处理后
实验组(第1组): A B
对照组(第2组): C D
简单的处理后差异: B - D (受组别差异影响)
简单的处理前后的变化: B - A (受时间趋势影响)
差分法估计的因果效应: (B - A) - (D - C) ← 这就是真正的因果效应B - A代表第1组在处理前后的变化,但这个数值同时包含了处理效果以及所有可能的时间趋势对结果的影响。D - C则代表第2组在相同时间范围内、在相同时间趋势影响下的变化情况(且没有接受任何处理)。将这两个数值相减,就可以得到仅由处理效果带来的变化。
反事实情景指的是如果第1组没有接受处理,其结果会是什么样。差分法正是通过以下方式来构建这一反事实情景的:第1组的反事实发展轨迹等于其在处理前的水平,再按照第2组在处理后的发展趋势继续发展。而实际的第1组发展轨迹与这个反事实轨迹之间的差异,就是差分法估计得出的因果效应。
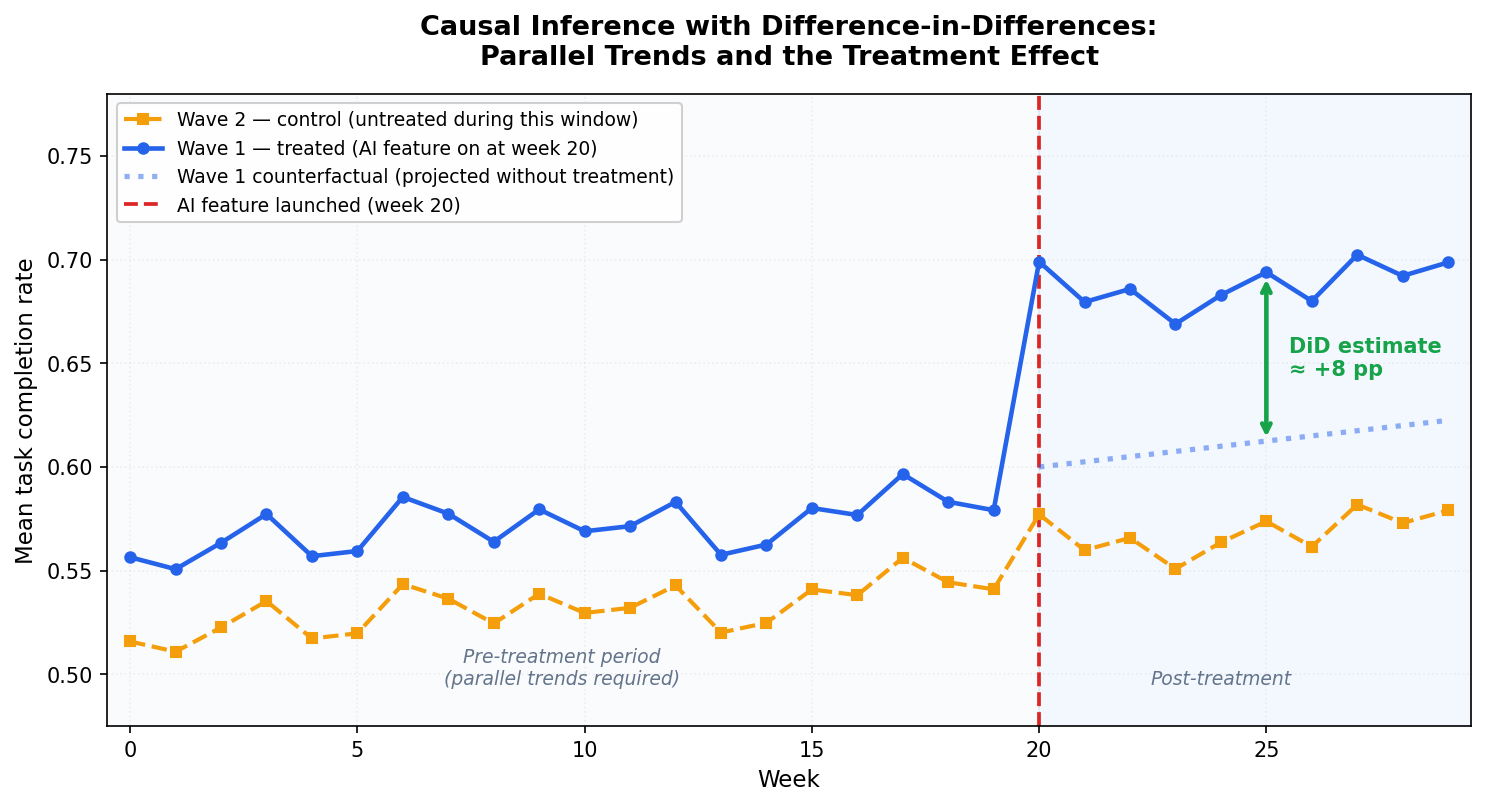
图1:利用差分法进行因果推断。蓝色实线代表第1组的实际发展轨迹;橙色虚线代表第2组(对照组,在这一时间段内未接受任何处理)的发展轨迹;蓝色点线代表反事实情景,即如果第1组按照第2组在处理后的发展趋势发展,其结果会是什么样。绿色箭头表示差分法估计得出的因果效应:实际的第1组发展轨迹与反事实情景之间的差异。
在第20周之前,第1组和第2组的发展轨迹非常接近,这正是“平行趋势”这一要求得到满足的表现。到了第20周,第1组的发展速度超过了第2组以及其反事实情景(即蓝色点线所代表的轨迹)。这种处理后的发展差异,就是差分法估计得出的因果效应。
差分法能够同时消除两种类型的偏差:首先,实验组和对照组之间的永久性差异会被抵消,因为差分法关注的是不同时期结果的变化情况;其次,那些对两组都会产生影响的共同因素(如产品改进、市场季节性变化等)也会被抵消,因为这两组都会受到这些因素的影响。
差异性双重检验要求一个前提:即处理组与对照组在处理开始前的变化趋势必须相同、且变化速度也必须一致。只有满足这一条件,才能将这种共同的趋势延续下去,并将处理后出现的任何差异归因于该处理措施本身。如果在治疗前这两种趋势就已经出现了分歧,那么差异性双重检验就会产生偏差,再复杂的回归分析也无法纠正这一问题。
“变化趋势相同”正是你将在第三步中验证的假设。
配套练习笔记本
本教程中的所有代码,包括合成数据集、差异性双重检验的回归分析代码、用于检测变化趋势是否平行的图表,以及用于验证处理前趋势是否一致的测试代码,都保存在GitHub上这个关于产品实验与因果推断的系列教程仓库中的一个Jupyter笔记本文件中。
你可以克隆这个笔记本文件,运行一次`generate_data.py`脚本,那么本文中提到的所有输出结果都会被准确重现。具体地址为:github.com/RudrenduPaul/product-experimentation-causal-inference-genai-llm
先决条件
你需要安装Python 3.11或更高版本,并且需要熟悉pandas库以及基本的回归分析方法。即使你没有因果推断方面的经验,也可以跟随本教程进行学习,因为本文会在相关概念首次出现时就对其进行详细解释。在第二步中,你会遇到“聚类标准误差”和“固定效应”这些概念,本文会说明它们的作用及其重要性,但不会从零开始推导这些公式。
请安装以下教程所需的软件包:
pip install numpy pandas statsmodels linearmodels matplotlib为了获取合成数据集,请克隆配套的仓库:
git clone https://github.com/RudrenduPaul/product-experimentation-causal-inference-genai-llm.git
cd product-experimentation-causal-inference-genai-llm
python data/generate_data.py --seed 42 --n-users 50000 --out data/synthetic_llm_logs.csv设置实验环境
这个数据集模拟了一个SaaS产品,该产品的“AI摘要”功能分两批推出:第一批用户在第20周获得这一功能,第二批用户则在第30周获得;总共有50,000名用户,每位用户的记录中都包含一行与遥测数据相关的信息。
数据生成脚本会设定这样一个机制:在处理后的阶段,使用者所在工作空间中的任务完成率会增加5个百分点。由于你事先已经知道了这一实际情况,因此可以用来检验差异性双重检验的估计结果是否能够准确反映这一效应。
请加载数据并查看其结构:
import pandas as pd
df = pd.read_csv("data/synthetic_llm_logs.csv")
print(df.shape)
print(df[["wave", "signup_week", "workspace_id", "task_completed"]].head())
print("\n各批用户数量:", df.wave.value_counts().to_dict())
print("每批用户的处理周数:",
df.groupby("wave").treatment_week.first().to_dict())
预期输出:
(50000, 16)
波次 注册周数 工作区ID 任务完成情况
0 2 10 36 0
1 2 51 44 1
2 2 2 28 1
3 1 15 20 1
4 1 29 0 1
各波次的用户数量:{2: 25063, 1: 24937}
每波次的处理周数:{1: 20, 2: 30}
具体操作过程如下:您加载了50,000条数据记录,每条记录对应一位用户。第1波次共有约24,937位用户,他们分布在25个不同的工作区中;第2波次也有约25,063位用户,同样分布于25个工作区中。treatment_week这一列记录了每位用户的 workspace何时启用了AI摘要功能:第1波次的用户是在第20周,而第2波次的用户则是在第30周。task_completed这一列反映了实验结果,即AI是否成功完成了用户的任务。
需要强调的一个重要细节是:signup_week这一字段记录了用户首次使用该产品的日期,我们利用它作为时间索引,将用户分为“处理前组”和“处理后组”。例如,如果在第22周注册的用户是在功能上线之后使用的该产品,那么他们的体验就属于“处理后组”;而如果在第14周注册的用户,则属于“处理前组”。
这种分类方法之所以可行,是因为每位用户都有一条与他们初次使用产品时的体验相关的数据记录。而在那些每个用户在不同时期都有多条数据记录的面板数据集中,就需要使用与数据记录时间相关的字段作为索引了。
为了保证分析结果的准确性,我们只考虑那些在第2波次功能上线之前注册的用户(即signup_week < 30)。这样一来,第2波次就成为了真正的对照组,因为它还没有接受任何处理;而第1波次则已经接受了10周的处理。
analysis = df[df signup_week < 30].copy()
analysis["post"] = (analysissignup_week >= 20).astype(int)
analysis["treated"] = (analysis.wave == 1).astype(int)
print(analysis.groupby(["treated", "post"])
.agg(n=("user_id", "count"),
mean_completion=("task_completed", "mean"))
.round(3))
预期输出:
n meancompletion
treated post
0 0 9590 0.556
1 4878 0.555
1 0 9633 0.592
1 4738 0.643
具体分析过程如下:我们首先筛选出了位于分析窗口内的数据(即第0周至第29周的数据),然后创建了两个指示变量。post这一变量的值为1,表示用户属于第20周之后使用的群体;否则值为0。treated这一变量的值为1,表示用户属于第1波次;否则值为0。通过groupby操作,我们可以得到DiD 2x2表格中的四组数据:(treated=0, post=0)、(treated=0, post=1)、(treated=1, post=0)、(treated=1, post=1)。这四组的平均值就是进行初步DiD分析所需的所有数据。
步骤1:简单的2x2 DiD分析
首先从最基础的版本开始。手动计算这四个单元格的平均值,然后求这些平均值的差异:
cells = analysis.groupby(["treated", "post")).task_completed.mean()
wave2_pre = cells.loc[(0, 0)] # 对照组,处理前
wave2_post = cells.loc[(0, 1)] # 对照组,处理后
wave1_pre = cells.loc[(1, 0)] # 处理组,处理前
wave1_post = cells.loc[(1, 1)] # 处理组,处理后
did_effect = (wave1_post - wave1_pre) - (wave2_post - wave2_pre)
print(f"第1阶段的变化量:{wave1_post - wave1_pre:+.4f}")
print(f"第2阶段的变化量:{wave2_post - wave2_pre:+.4f}")
print(f>差异效应: {did_effect:+.4f})
预期输出:
第1阶段的变化量: +0.0515
第2阶段的变化量: -0.0013
差异效应: +0.0527 (真实值 = +0.05)
具体操作过程如下:首先计算这四个单元格的平均值,然后分别计算第1阶段和处理组在处理前后的任务完成度变化量,再计算对照组在同一时间窗口内的变化量,最后将这些变化量相减。差异效应就是那些无法被共同影响第2阶段变化的因素所解释的部分。
在这个数据集上,简单的2x2分析得出的结果是+0.053,这个数值与真实值+0.05非常接近。但是你不能将这个结果直接用于产品评估。因为你不清楚这个数值对应的标准误差是多少,也就无法判断+0.053是真正的效应还是只是抽样误差造成的。此外,你也没有进行协变量调整,因此如果处理组中恰好有更多活跃用户,那么这部分+0.053可能实际上反映了用户参与度的差异。最后,你的数据中也存在工作区之间的相关性问题,而这种问题在简单的2x2分析中是无法被考虑到的。第2步的方法可以解决这三个问题。
第2步:使用固定效应进行回归分析
当没有协变量时,回归分析得出的差异效应估计值与2x2分析的结果是相同的。但是回归分析还能为你带来以下三个好处:
-
标准误差和p值能够被正确计算出来
-
可以通过协变量调整来减少方差,从而提高估计结果的准确性
-
由于考虑了工作区内的相关性,因此得到的结果更具稳定性
回归模型的公式为:outcome ~ treated + post + treated:post + controls。其中treated:post这个交互项的系数就是你所求的差异效应估计值。
import statsmodels.formula.api as smf
did_model = smf.ols(
"task_completed ~ treated * post + C(engagement_tier)",
data=analysis
).fit(
cov_type="cluster",
cov_kwds={"groups": analysis.workspace_id}
)
print(did_model.summary().tables[1])
预期输出:
================================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------------------
截距 0.8301 0.007 126.538 0.000 0.817 0.843
C(engagement_tier)[T_light] -0.4027 0.006 -63.168 0.000 -0.415 -0.390
C(engagement_tier)[T.medium] -0.1766 0.007 -25.931 0.000 -0.190 -0.163
treated 0.0367 0.005 6.885 0.000 0.026 0.047
post -0.0056 0.008 -0.684 0.494 -0.022 0.011
treated:post 0.0541 0.011 4.981 0.000 0.033 0.075
================================================================================================
具体操作过程如下:你需要对任务完成情况与treated指标、post指标、它们之间的交互作用,以及代表用户参与程度的分类控制变量进行普通最小二乘回归分析。
treated:post系数就是差异-in-differences方法的估计结果。处于同一工作空间的用户会受到相同因素的影响,因此他们的结果存在相关性;通过按workspace_id对数据进行分组,就可以消除这种相关性。
在这个数据集上,treated:post系数的值为+0.054,聚类后的p值小于0.001。而实际值应为+0.050。这个估计结果的误差仅为真实值的0.4%,且其标准误差已经考虑到了工作空间层面的相关性,因此这个结果是可以用来作为产品评价依据的。
关于这种回归分析,还有一些实际需要注意的事项:
-
控制变量必须是时间不变的(例如用户参与程度、注册群体等)。如果控制变量本身会随着处理措施的变化而改变,那么就会导致估计结果出现偏差。
-
只有交互作用项才具有因果解释意义。截距项和水平项仅能反映各组之间的基线差异,无法说明其他因果关系。
-
必须使用聚类误差估计方法。如果不进行聚类处理,标准误差会缩小3到10倍,测试统计量的数值也会被人为夸大,从而导致结果看起来比实际更显著。
步骤3:检验平行趋势假设
只有当在开始处理措施之前,第1波和第2波的数据变化方向和速度相同时,差异-in-differences方法才有效。你可以通过绘制或制作表格,展示处理措施实施前这两波数据在每周的平均值来验证这一假设。
import matplotlib.pyplot as plt
import numpy as np
df_plot = df[df.signup_week < 30].copy()
weekly = (df_plot.groupby(["signup_week", "wave"])
.task_completed.mean()
.reset_index()
.pivot(index="signup_week", columns="wave", values="task_completed"))
# 使用3周滚动平均法消除每周数据采样带来的噪声
smoothed = weekly.rolling(3, center=True, min_periods=2).mean()
TREATMENT_WEEK = 20
pre_idx = smoothed.index[smoothed.index < TREATMENT_week]
post_idx = smoothed.index[smoothed.index >= TREATMENT_WEEK]
# 计算差异-in-differences方法的反事实结果:第1波处理前的平均值加上第2波处理后的变化量
wave1_pre_mean = smoothed.loc[pre_idx, 1].mean()
wave2_pre_mean = smoothed.loc[pre_idx, 2].mean()
counterfactual = wave1_pre_mean + (smoothed.loc[post_idx, 2].values - wave2_pre_mean)
fig, ax = plt.subplots(figsize=(10, 5.5))
ax.axvspan(-0.5, TREATMENT_WEEK, alpha=0.04, color="#94A3B8", zorder=0)
ax(axvspan(TREATMENT_week, 29.5, alpha=0.06, color="#3B82F6", zorder=1))
ax.plot(smoothed.index, smoothed[2], "s--", color="#F59E0B", linewidth=2,
markersize=4, label="第2波数据——对照组(在此期间未接受处理)", zorder=3)
ax.plot(smoothed.index, smoothed[1], "o-", color="#2563EB", linewidth=2.2,
markersize=4, label="第1波数据——实验组(在第20周启用了AI功能)", zorder=4)
ax.plot(post_idx, counterfactual, ":", color="#2563EB", linewidth=2.2,
label="第1波数据的反事实结果(未接受处理时的预期值)", zorder=4)
ax.axvline(TREATMENT_WEEK, color="#DC2626", linestyle="--", linewidth=1.8,
label="AI功能于第20周推出")
ax.text(9.5, 0.508, "处理措施实施前\n(需要满足平行趋势假设)", fontsize=9, ha="center", color="#64748B", style="italic")
ax.text(24, 0.508, "处理措施实施后", fontsize=9, ha="center", color="#64748B", style="italic")
ax.set_xlabel("周数", fontsize=11)
ax.set_ylabel("平均任务完成率", fontsize=11)
ax.set_title("图2:基于数据的平行趋势检验\n(3周滚动平均值,5万用户数据)", fontsize=12, fontweight="bold", pad=14)
ax.legend(loc="upper left", fontsize=9, framealpha=0.92)
ax.set.xlim(-0.5, 29.5)
ax.setylim(0.50, 0.72)
ax.grid(True, alpha=0.18, linestyle=":")
ax.tick_params(labelsize=10)
plt.tight_layout()
plt.savefig("parallel_trends.png", dpi=150, bbox_inches="tight")
print("文件parallel_trends.png已保存")
预期结果(图2,数据驱动验证):
保存文件 parallel_trends.png
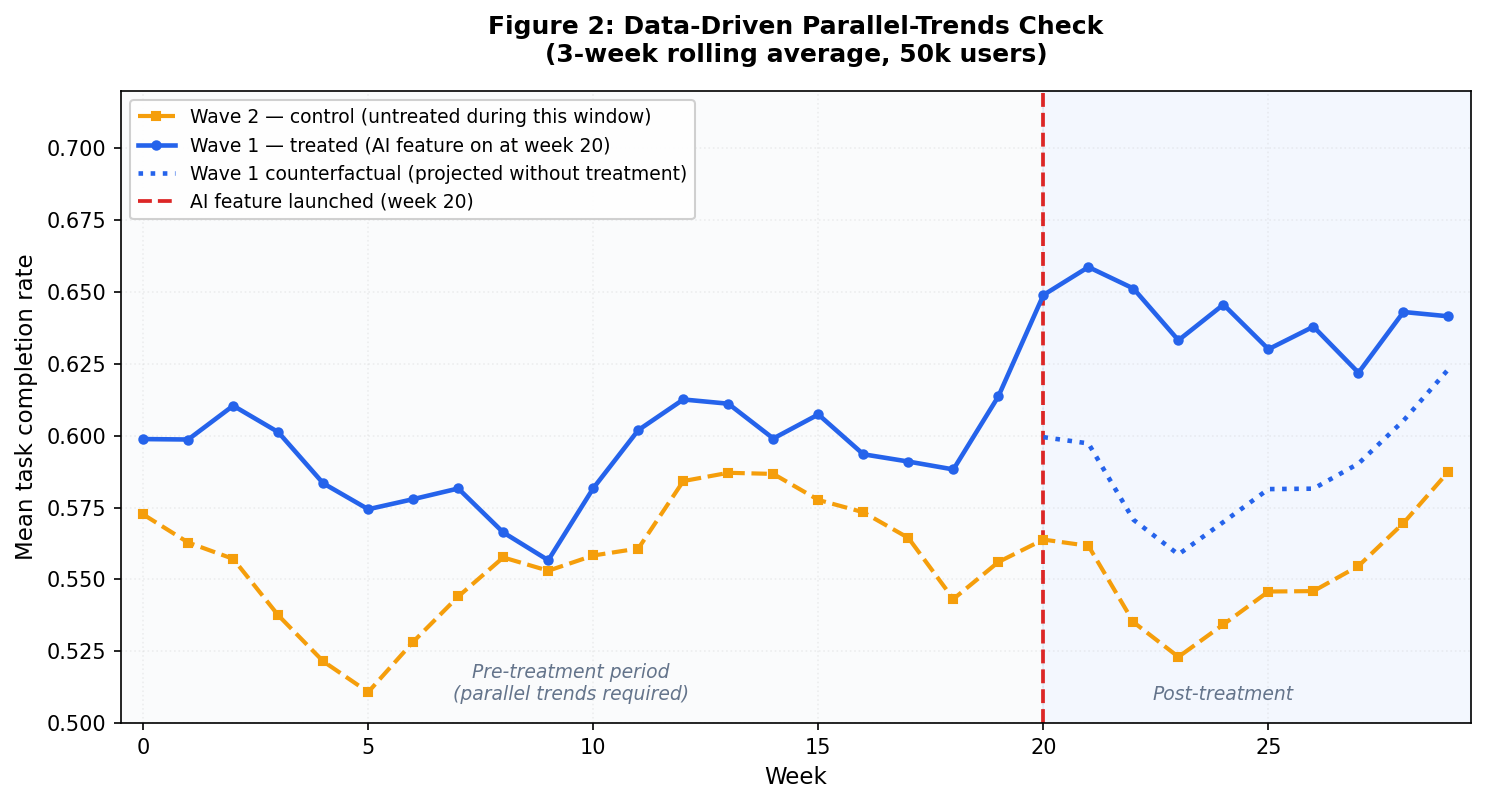
图2显示了根据您实际数据集进行的数据驱动平行趋势分析结果。该图表采用3周滚动平均值的形式进行绘制,以此消除每周样本数据中存在的波动影响。在第20周之前,这两组数据的变化趋势十分接近;而在治疗开始前的那段时间内,任何微小的变化都会同时影响到两组数据,这正是平行趋势应有的表现。第20周之后,第一组数据明显开始偏离趋势线,并持续保持在虚线以上。在治疗后的观察期内,实线蓝色曲线与虚线之间的差距,实际上反映了您的实际数据中存在的处理效应。
具体分析过程如下:首先按照用户注册周数和实验组别对数据进行分组,计算每个组内的平均任务完成率;然后将数据重新整理,使得每组成为一列,最终将这两组时间序列合并在一起进行绘制。
其中,一条垂直虚线标记了第20周这一关键节点——在这一周,第一组数据开始接受治疗。在治疗前的那19周里,两组数据的变化趋势应该非常接近;而第20周之后,第一组数据的增长幅度应该会明显大于第二组数据,这种差异正好反映了治疗效应。
为了量化这一效应,我们可以仅对治疗前的数据段进行回归分析。具体来说,我们需要将任务完成率作为因变量,同时考虑线性时间趋势与是否接受治疗这一因素的交互作用。如果这种交互作用的系数接近于零且不具有统计显著性,那就说明在治疗之前,这两组数据的变化趋势确实是平行的。
pre_only = analysis[analysis.post == 0].copy()
pre_only["weeks_since_start"] = pre_onlysignup_week - 10 # 将时间轴中心调整到第0周
placebo_model = smf.ols(
"task_completed ~ treated * weeks_since_start + C(engagement_tier)",
data=pre_only
).fit(
cov_type="cluster",
cov_kwds={"groups": pre_only.workspace_id}
)
print("治疗前的趋势斜率差异:", placebo_model.params["treated:weeks_since_start"])
print("p值:", placebo_model.pvalues["treated:weeks_since_start"])
预期结果:
治疗前的趋势斜率差异: -0.00095…
p值: 0.4435…”
通过这种分析方法,我们可以确定在治疗之前,这两组数据的变化趋势是否平行。如果交互作用系数的绝对值接近于零且p值大于0.05,那就说明治疗前两组数据的确是同步变化的;而如果该系数较大且具有统计显著性,那就意味着平行趋势假设不成立——此时我们得到的处理效应估计结果实际上包含了第20周之前导致两组数据出现差异的那些因素。
如果安慰剂检验的结果不理想,那么就需要重新考虑分析方法。可行的补救措施包括:缩小观察时间范围,只选取治疗前趋势平行的数据段;寻找更合适的对照组;或者采用合成控制法,即利用多个未接受治疗的样本构建出一个加权虚拟对照组。
在这个合成数据集上,安慰剂检验通过了:处理前趋势的斜率差异为-0.00095,对应的p值为0.44,因此“趋势平行”的假设成立,第二步中得出的+0.054这一估计值是可信的。
当“差异中的差异”方法失效时
“差异中的差异”是一种精确的分析方法,但任何精确的方法都存在某些特定的失效模式,在相信其分析结果之前了解这些模式是必要的。以下是四种常见的失效情况:
1. 处理前趋势不平行
当处理组和对照组在处理开始之前就已经出现了发展趋势上的差异时,“差异中的差异”方法会将这种预先存在的变化误认为是处理效果。
第三步中的安慰剂检验可以作为一道防线,每次分析都应进行这项检验。如果检验结果不理想,你有三个选择:
-
将分析范围限制在处理前趋势平行的较短时间段内,然后重新进行安慰剂检验
-
寻找一个处理前趋势与处理组相匹配的对照组
-
改用合成控制法,该方法会利用多个未接受处理的样本构建加权反事实数据,并调整权重以使这些数据的处理前发展趋势与处理组一致
2. 推广时间不同步
如果推广分为三波或更多波次进行,那么就需要采用不同于标准2x2设计的分析方法。例如,第一波在第20周开始接受处理,第二波在第30周开始,第三波在第40周开始。一旦第二波开始处理,它就不再适合用于第30周及之后的比较分析了——因为较早接受处理的样本会开始充当后来样本的对照组,从而导致估计结果出现偏差。
这就是Goodman-Bacon分解问题,而第二步中使用的标准双向固定效应估计方法会默默地掩盖这一问题。Callaway-Sant’Anna估计方法(详见他们2021年发表的论文)通过仅使用那些没有受到这种干扰的2x2比较数据来纠正这一问题。differences这个Python包实现了这一方法。
3. 仅影响处理组的时变混杂因素
如果你的营销团队在第22周对第一波样本进行了有针对性的宣传活动,那么就会产生一种特定于该处理措施的影响,而“差异中的差异”方法无法消除这种影响。
虽然“趋势平行”可以确保处理前的数据具有可比性,但处理后的数据仍需要你自己进行仔细审核。
请检查分析窗口内的所有产品或营销活动。如果发现了这类因素,你只有三个选择:重新设计研究方案、将分析范围限制在受到干扰之前的时间段内,或者将这种干扰因素明确作为第二个处理变量纳入模型中进行分析。
4. 预期效应
如果第一波样本中的客户在第18周就得知该功能将在第20周推出,那么其中一些人就会在处理措施实际开始之前就开始改变自己的行为:比如提前注册、预先配置设置或联系客服。这种行为会影响到“处理前”的数据分布。在事件研究图中,这种现象表现为第20周之前的几周内,第一波样本的数据出现异常波动。
解决办法是将预期阶段的截止时间向后推迟。在分析中,将第18周视为“干预措施”开始的时刻,这样就可以消除预期阶段基线数据中所包含的预期因素。
每种这种失效模式都有相应的诊断方法及具体的补救措施。在分析中明确指出这些内容,有助于增强那些持怀疑态度的评审者的信任度。差分法是一种严谨的分析工具——只要其输入数据准确无误,就能产生可靠的估计结果。
下一步该怎么做
上述提到的差分分析法正是针对分阶段实施干预措施的情况而设计的理想工具。如果你的干预措施分为三个或更多阶段,请改用Callaway-Sant’Anna估算方法。如果你的干预措施所涉及的阈值是你事先设定的(比如置信度指标或查询复杂度等),那么就需要考虑是否存在回归不连续性现象。如果你想将某个被干预的对象与一个人为构建的对照组进行比较,那么合成控制法就是正确的选择。
本教程配套的笔记本文件可以在这里找到:点击查看。你可以克隆这个代码仓库,使用generate_data.py生成合成数据集,然后打开did_demo.ipynb文件,这样就可以看到所有代码块以及它们预先保存的输出结果了。
如果你是分阶段推出人工智能功能,那么你的推广计划本身就已经构成了一项差分分析法研究。唯一需要考虑的问题就是是否真的要进行这项分析而已。