

在选择机器学习算法之前,了解其特性以生成所需的输出并构建智能系统非常重要。
数据科学正在以超快的速度增长。随着对支持 AI 的解决方案的需求不断增加,为行业提供更智能的系统变得至关重要。并且必须通过机器学习操作实现正确性和效率,以确保开发的解决方案满足所有要求。因此,在给定的数据集上应用机器学习算法来产生正确的结果并训练智能系统是整个过程中最重要的步骤之一。
机器学习:培养更好的结果和伟大的成就
机器学习只是AI的应用,它使机器能够根据用户要求自动学习并不断发展,以满足他们带来的各种需求。机器学习的概念易于理解,而实现是复杂的,需要专家的支持。它由开发的程序组成,用于访问系统上存储的数据,并通过研究模式和通过持续学习提供更好的支持来使其更加智能。
您可能还喜欢:
10 机器学习算法,你应该知道成为一个数据科学家
收集的数据通过不同的机器学习方法和算法进行处理,以预测其结果。但是,算法会根据指定的要求而变化。单一算法不能达到所有目的,因此,需要根据学习方法选择正确的算法。
机器学习算法和流程提供哪些输出?
机器学习过程的输出是从现有数据中获得的信息。它只需从原始数据中提取可以收集的知识,并通过学习模式和实体或事件发生的可能机会来预测下一个结果的能力。机器学习的实际应用可以列出如下:
1. 预测
处理现有数据后,可以启用机器或系统,从提供的详细信息预测下一个结果。例如,天气预报。
2. 图像和语音识别
通过研究所提供的图像的每个像素的数据以及语音或图像的特征,通过现有数据所开发的知识来识别和分类所提供的输入。
3. 金融交易
通过观察现有数据中的模式,机器学习算法可以预测和判断投资是否有利可图,并引导您走上正确的路径,以防止损失。例如,采用 AI 驱动的对冲基金,利用机器学习和 AI 获得最佳效果。
4. 医疗诊断
当提供完整的数据和每个条目的可能结果时,系统使用机器学习算法预测特定人员发生疾病的可能性
机器学习算法的类型
机器学习可以分为三种类型:
1. 监督学习
在监督学习中,对提供给系统的数据进行标记。在这里,标记的数据被定义为已划分为正义组的数据,机器可以理解每个条目不同于属于其他类的任何其他条目。因此,使用监督学习,计算机将提供已分类的数据并创建数据集。
使用监督学习,目的是开发一个映射函数,当应用于输入数据时,可以预测某些结果。很多时候,数据中的单个实例会重复使用,以检查实现的模型是否正常工作。监督学习涵盖的算法有 2 种类型:
1. 1 分类
分类模型将通过根据参数值进行分类来预测现有数据中给定输入数据的类别。分类不提供值作为输出,而是使用提供的类中的现有数据对数据进行分类。
逻辑回归
分类的最简单示例是逻辑回归。基于输入数据,分类可以是二进制类或多类,逻辑回归是二进制分类的示例,输入数据可以划分(在 0/1、真/假或多个类别中),即根据输入数据,它将数据分类为最多两个不同的类。 它根据概率(介于 0 和 1 之间)预测输出值。也称为对数回归,此分类算法根据概率对输入数据进行分类。它可以简单地表示为:
odds= pr/ (1-pr) = probability of occurrence / probability of not event occurrence
loge(odds) = loge(pr/(1-pr))
在这里,”pr”表示输入中存在特征的概率。它只是通过选择增加事件发生可能性的输入的正确参数来工作。

逻辑回归 (来源)
下面是一个实现逻辑回归的示例的 R 代码,如果已安装 R,则可以在操作系统上运行该逻辑回归。如果没有,请在此处了解如何为您的操作系统安装 R。
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
logistic <- glm(y_train ~ ., data = x,family='binomial')
summary(logistic)
#Predict Output
predicted= predict(logistic,x_test)或者,您可以使用 Python 运行和观察提供的输出linear_model导入线性回归
从 sklearn.指标导入mean_squared_error
• 读取火车和测试数据集
train_data = pd.read_csv(”火车.csv”)
test_data = pd.read_csv(”test.csv”)
打印(train_data.头())
• 数据集的形状
打印(’\n训练数据的形状:’,train_data.形状)
打印(’\n测试数据的形状:’,test_data.形状)
• 现在,我们需要预测测试数据中缺少的目标变量
• 目标变量 – Item_Outlet_Sales
• 在训练数据上分离独立变量和目标变量
train_x = train_data.drop(列=Item_Outlet_Sales”,轴=1)
train_y = train_data[Item_Outlet_Sales]]
• 在训练数据上分离独立变量和目标变量
test_x = test_data.drop(列=”Item_Outlet_Sales”,轴=1)
test_y = test_data[Item_Outlet_Sales]]
”’
创建线性回归模型的对象
您还可以添加其他参数并在此处测试代码
一些参数是 :fit_intercept和规范化
斯克学习线性回归的文档:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
”’
模型 = 线性回归()
• 将模型与训练数据配合
模型.拟合(train_x、train_y)
• 训练模型的共性
打印(’\n模型系数:’,模型.coef_)
• 模型的截取
打印(’\n模型的截取’,模型.intercept_)
• 预测测试数据集上的目标
predict_train = 模型.预测(train_x)
打印(关于培训数据”predict_train”nItem_Outlet_Sales)
• 训练数据集上的根均方错误
rmse_train = mean_squared_error(train_y,predict_train)*(0.5)
打印(在列车数据集上打印:’,rmse_train)
• 预测测试数据集上的目标
predict_test = 模型.预测(test_x)
打印(测试数据nItem_Outlet_Sales,predict_test)
• 测试数据集上的根均方误差
rmse_test = mean_squared_error(test_y,predict_test)*(0.5)
打印(在测试数据集上打印:’,rmse_test)
决策树
决策树算法通过对现有数据和重要参数的均质类进行分类,从而对类别数据进行分类,这些参数导致输入正确的类别。决策树算法可用于分类变量或独立变量,以提高预测效率。
下面是在数据集平衡比例权重和距离上使用 Python 实现决策树算法的示例。该算法有效地对实体进行分类,并使用基尼索引、熵等不同度量可以发现实体的准确性。
# Importing the required packages
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
# Function importing Dataset
def importdata():
balance_data = pd.read_csv(
'https://archive.ics.uci.edu/ml/machine-learning-'+
'databases/balance-scale/balance-scale.data',
sep= ',', header = None)
# Printing the dataset shape
print ("Dataset Length: ", len(balance_data))
print ("Dataset Shape: ", balance_data.shape)
# Printing the dataset observations
print ("Dataset: ",balance_data.head())
return balance_data
# Function to split the dataset
def splitdataset(balance_data):
# Separating the target variable
X = balance_data.values[:, 1:5]
Y = balance_data.values[:, 0]
# Splitting the dataset into train and test
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size = 0.3, random_state = 100)
return X, Y, X_train, X_test, y_train, y_test
# Function to perform training with giniIndex.
def train_using_gini(X_train, X_test, y_train):
# Creating the classifier object
clf_gini = DecisionTreeClassifier(criterion = "gini",
random_state = 100,max_depth=3, min_samples_leaf=5)
# Performing training
clf_ginitarin_using_entropy(X_train、X_test、y_train):
• 具有熵的决策树
clf_entropy = 决策树分类器(
标准 = “熵”,random_state = 100,
max_depth = 3,min_samples_leaf = 5)
• 执行培训
clf_entropy(X_train,y_train)
返回clf_entropy
• 进行预测的功能
def 预测(X_test、clf_object):
• 使用基尼指数对测试进行预测
y_pred = clf_object.预测(X_test)
打印(”预测值:”)
印刷(y_pred)
返回y_pred
• 计算精度的函数
德cal_accuracy(y_predy_test):
打印(”混淆矩阵:”,
confusion_matrix(y_test、y_pred))
打印(”准确性:”,
accuracy_score(y_test,y_pred)=100)
打印(”报告:”,
classification_report(y_predy_test))
• 驱动程序代码
de main():
• 建造阶段
数据 = 导入数据()
X、Y、X_train、X_test、y_train、y_test = 拆分数据集(数据)
clf_gini = train_using_gini(X_train、X_test、y_train)
clf_entropy = tarin_using_entropy(X_train、X_test、y_train)
• 操作阶段
打印(”使用基尼索引的结果:”)
• 使用基尼进行预测
y_pred_gini = 预测(X_test、clf_gini)
cal_accuracy(y_pred_giniy_test)
打印(”使用熵的结果:”)
• 使用熵进行预测
y_pred_entropy = 预测(X_test,clf_entropy)
cal_accuracy(y_pred_entropyy_test)
• 调用主函数
如果__name__=”__main__”:
主()
纳维·贝叶斯
NaiveBayes算法考虑独立参数,使用贝叶定理有效地预测结果。它认为所有特征都是独立的,无论它们是否真的独立。输出效率和预测精度显著提高,尤其是在应用 Naive Bayes 算法时的大型数据集。例如,运行 uber克隆的系统决定应用一个程序来标识来宾用户是乘客或驾驶员,考虑到驾驶员查找的车手的参数,提供了文档详细信息,并且拥有系统注册的车辆,该算法可以预测特定用户是驾驶员。
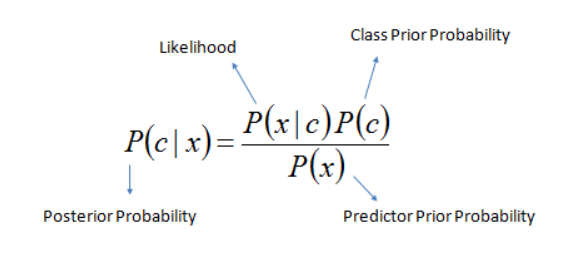
Naive_Bayes公式 (来源)
在这里,使用 Naive Bayes 时,将会考虑不同参数的注册车辆的可用性、文档验证过程状态和用户兴趣。将 Naive Bayes 用于系统的主要好处是其简单性和准确性,有时甚至优于某些流行的分类方法。
下面是使用 Python 在训练数据集上实现 Naive Bayes 的小示例,该函数提供结果中得出的精度分数:
# importing required libraries
import pandas as pd
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# read the train and test dataset
train_data = pd.read_csv('train-data.csv')
test_data = pdcsv’)
• 数据集的形状
打印(”训练数据的形状:”,train_data。”
打印(”测试数据的形状:”‘,test_data.形状)
• 现在,我们需要预测测试数据中缺少的目标变量
• 目标变量 – 幸存
• 在训练数据上分离独立变量和目标变量
train_x = train_data.drop(列=”幸存”*,轴=1)
train_y = train_data[‘生存’]
• 在测试数据上分离独立变量和目标变量
test_x = test_data.drop(列=”幸存”*,轴=1)
test_y = test_data[‘生存’]
”’
创建天真贝叶斯模型的对象
您还可以添加其他参数并在此处测试代码
某些参数是 :var_smoothing
斯克学高斯尼布语文档:
https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
”’
模型 = 高斯NB()
• 将模型与训练数据配合
模型.拟合(train_x、train_y)
• 预测列车数据集上的目标
predict_train = 模型.预测(train_x)
打印(”列车数据的目标”,predict_train)
• 列车数据集上的 Accuray 分数
accuracy_train = accuracy_score(train_y,predict_train)
打印(”accuracy_score在列车数据集上:’,accuracy_train)
• 预测测试数据集上的目标
predict_test = 模型.预测(test_x)
打印(”测试数据的目标”,predict_test)
• 测试数据集的准确性评分
accuracy_test = accuracy_score(test_y、predict_test)
打印(测试数据集上的”accuracy_score:”,accuracy_test)
除了这些算法之外,还有其他流行的分类算法(如SVM(支持矢量机),它们还提供准确的结果来预测给定数据的结果。
1.2 回归
回归算法有助于以值的形式预测输出。例如,如果给出一个住房定价数据集,从输入数据,这些算法将能够提供根据输入的详细信息的房子的固定价格。
线性回归
线性回归有助于派生两个变量之间的依赖关系。基于给定的数据,它观察模式,然后预测独立变量值的变化如何影响另一个变量。线性回归有助于找出值,而不是对类别进行分类或预测。它使用在图形上绘制线的简单公式,其中 X 组件可以帮助确定 Y 组件的值。
线的方程是 Y= X.m +b 米是线的斜率,b是截距。在这里,m 和 b 使用数据点和实际回归线之间的平方差总和的方法派生。线性回归可以在两种类型中进一步扩展:简单线性回归,其中结果依赖于单个变量,而多线性回归的结果依赖于多个(两个或多个)变量。
在简单线性回归中,回归线在两个维度图中绘制,而对于多个线性回归,该图在多维场中绘制。
线性回归 (来源)
下面是在训练数据集上线性回归的简单实现:
# importing required libraries
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# read the train and test dataset
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
print(train_data.head())
# shape of the dataset
print('\nShape of training data :',train_data.shape)
print('\nShape of testing data :',test_data.shape)
# Now, we need to predict the missing target variable in the test data
# target variable - Item_Outlet_Sales
# seperate the independent and target variable on training data
train_x = train_data.drop(columns=['Item_Outlet_Sales'],axis=1)
train_y = train_data['Item_Outlet_Sales']
# seperate the independent and target variable on training data
test_x = test_data.drop(columns=['Item_Outlet_Sales'],axis=1)
test_y = test_data['Item_Outlet_Sales']
'''
Create the object of the Linear Regression model
You can also add other parameters and test your code here
Some parameters are : fit_intercept and normalize
Documentation of sklearn LinearRegression:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
'''
model = LinearRegression()
# fit the model with the training data
model.fit(train_x,train_y)
# coefficeints of the trained model
print('\nCoefficient of model :', model.coef_)
# intercept of the model
print('\nIntercept of model',model.intercept_)
# predict the target on the test dataset
predict_train = model.predict(train_x)
print('\nItem_Outlet_Sales on training data',predict_train)
# Root Mean Squared Error on training dataset
rmse_train = mean_squared_error(train_y,predict_train)**(0.5)
print('\nRMSE on train dataset : ', rmse_train)
# predict the target on the testing dataset
predict_test = model.predict(test_x)
print('\nItem_Outlet_Sales on test data',predict_test)
# Root Mean Squared Error on testing dataset
rmse_test = mean_squared_error(test_y,predict_test)**(0.5)
print('\nRMSE on test dataset : ', rmse_test)
在监督学习中,数据已经标记,算法可以轻松理解训练集包含的内容。然而,真正的挑战在无监督学习中暴露出来,因为数据没有标记,也没有固定类来对数据进行分类,因此在无监督学习中,集群和关联被赋予最高优先级。
2. 无监督学习
在无监督学习中,提供给系统的数据没有分类或标记,真正的原始数据被馈送到程序,并根据指定的要求接收输出。从某种意义上说,无监督学习可以看作是对程序声称要实现的AI概念的测试
1. 聚类
群集用于标识条目并将其放入所有条目具有一些共同特征的群集中。K 均值聚类算法是一种流行的算法,在数据上执行时,会将其划分为基于质心(即所选数据点)形成的聚类。所有其他值都落在质心点附近,并分为聚类并形成单独的聚类。创建质心和聚类的过程不会停止,直到质心的值变为恒定。
可以找到聚类的最佳值,因为在一个点之后,聚类和质心点的数量会慢慢开始减少,并且找到一个特定的数字,即最佳聚类编号。

K-手段聚类 (源)
请尝试以下代码,以了解如何从训练数据集中形成不同的群集,因为示例提供了创建的群集总数:
# importing required libraries
import pandas as pd
from sklearn.cluster import KMeans
# read the train and test dataset
train_data = pd.read_csv('train-data.csv')
test_data = pd.read_csv('test-data.csv')
# shape of the dataset
print('Shape of training data :',train_data.shape)
print('Shape of testing data :',test_data.shape)
# Now, we need to divide the training data into differernt clusters
# and predict in which cluster a particular data point belongs.
'''
Create the object of the K-Means model
You can also add other parameters and test your code here
Some parameters are : n_clusters and max_iter
Documentation of sklearn KMeans:
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
'''
model = KMeans()
# fit the model with the training data
model.fit(train_data)
# Number of Clusters
print('\nDefault number of Clusters : ',model.n_clusters)
# predict the clusters on the train dataset
predict_train = model.predict(train_data)
print('\nCLusters on train data',predict_train)
# predict the target on the test dataset
predict_test = model.predict(test_data)
print('Clusters on test data',predict_test)
# Now, we will train a model with n_cluster = 3
model_n3 = KMeans(n_clusters=3)
# fit the model with the training data
model_n3.fit(train_data)
# Number of Clusters
print('\nNumber of Clusters : ',model_n3.n_clusters)
# predict the clusters on the train dataset
predict_train_3 = model_n3.predict(train_data)
print('\nCLusters on train data',predict_train_3)
# predict the target on the test dataset
predict_test_3 = model_n3.predict(test_data)
print('Clusters on test data',predict_test_3)
2. 协会
关联只是通过建立实体之间的关系来工作,并相应地预测或建议。协会最流行的实际应用之一是市场篮分析,它被广泛用于在建立项目之间的关系时,先验算法可以产生奇迹。特别是对于零售业,该算法通过增加利润取得了巨大的成功。前先算法旨在建立不同项目之间的结构关系。这支持了市场篮分析背后的根本原因,并推广了最佳实践,帮助零售所有者了解其用户在货架安排发生变化时可能购买的内容。
下面是在杂货店数据集上实现 Apriori 算法的简单示例,该算法预测客户可能一起购买哪些商品。
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Changing the working location to the location of the file
cd C:\Users\Dev\Desktop\Kaggle\Apriori Algorithm
# Loading the Data
data = pd.read_excel('Online_Retail.xlsx')
data.head()
# Exploring the columns of the data
data.columns
# Exploring the different regions of transactions
data.Country.unique()
# Stripping extra spaces in the description
data['Description'] = data['Description'].str.strip()
# Dropping the rows without any invoice number
data.dropna(axis = 0, subset =['InvoiceNo'], inplace = True)
data['InvoiceNo'] = data['InvoiceNo'].astype('str')
# Dropping all transactions which were done on credit
data = data[~data['InvoiceNo'].str.contains('C')]
# Transactions done in France
basket_France = (data[data['Country'] =="France"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
# Defining the hot encoding function to make the data suitable
# for the concerned libraries
def hot_encode(x):
if(x<= 0):
return 0
if(x>= 1):
return 1
# Encoding the datasets
basket_encoded = basket_France.applymap(hot_encode)
basket_France = basket_encoded
# Building the model
frq_items = apriori(basket_France, min_support = 0.05, use_colnames = True)
# Collecting the inferred rules in a dataframe
rules = association_rules(frq_items, metric ="lift", min_threshold = 1)
rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False])
print(rules.head())
生成的输出是通过计算置信度和支持值而派生的规则,该值表示大多数客户共同购买产品的可能性。

3. 强化学习
强化学习算法根据代理对环境的反应原理工作。代理与给定环境交互,并根据它显示的行为,代理获得奖励或添加到观察值中。此处,观察是代理未获得奖励的事件列表,因此,在下次代理与环境交互时,将避免特定实例。强化学习最常见的例子是狗训练。

强化学习 (来源)
通过强化学习,代理学习了与环境交互的正确方法,并交付了所需的结果。
选择正确算法的重要性
如上所述,这些算法中的每一个在许多方面都不同。要在可用的数据集上实现机器学习算法,了解数据的性质并根据设定的目标选择正确的算法非常重要。虽然正确的算法可以支持制定更智能的解决方案,但缺乏功能的算法会严重影响整个智能系统,并可能提供错误的输出。
为了选择正确的机器学习算法,最好向专家数据科学家寻求支持,了解哪些算法可以满足要求并提供准确的结果。随着这些发明进一步将机器学习和人工智能的概念进一步采用,数据科学将为未来的机器学习爱好者带来光明的职业生涯。