
什么是阿帕奇流卢姆?
Apache Flume 是一种高效、分布式、可靠且容错的数据引入工具。它便于将大量日志文件从各种源(如 Web 服务器)流式传输到 Hadoop 分布式文件系统 (HDFS)、分布式数据库(如 HDFS 上的 HBase),甚至以近乎实时的速度将 Elasticsearch 等目标流式传输到此。除了流式传输日志数据外,Flume 还可以流式传输从 Twitter、Facebook 和 Kafka 经纪人等网络来源生成的事件数据。
阿帕奇·弗卢姆的历史
Apache Flume 由 Cloudera 开发,旨在提供一种快速可靠地将 Web 服务器生成的大量日志文件流式传输到 Hadoop 的方法。在那里,应用程序可以对分布式环境中的数据执行进一步分析。最初,Apache Flume 被开发为仅处理日志数据。后来,它还具备处理事件数据的能力。
HDFS 概述
HDFS 代表 Hadoop 分布式文件系统。HDFS 是 Apache 开发的一种工具,用于在分布式平台上存储和处理大量非结构化数据。许多数据库使用 Hadoop,利用网络中多个系统的计算能力,以可扩展的方式快速处理大量数据。Facebook、雅虎和LinkedIn是少数依赖Hadoop进行数据管理的公司。
为什么是阿帕奇·弗卢姆?
跨多个服务器和主机运行多个 Web 服务的组织将每天生成大量日志文件。这些日志文件将包含有关用于审核和分析目的所需的事件和活动的信息
Flume 是为日志文件构建数据管道时的热门选择,因为它简单、灵活且功能-如下所述。
Flume 的特性和功能
Flume 通过从多个源提取原始日志文件并将其流式传输到 Hadoop 文件系统来传输原始日志文件。在那里,日志文件可以由分析工具,如Spark或Kafka使用。Flume 可以连接到各种插件,以确保将日志数据推送到正确的目标。
使用 Apache Flume 流式传输数据:体系结构和示例
需要规划和构建通过 Apache Flume 流式传输数据的过程,以确保以高效的方式传输数据。
要将数据从 Web 服务器流式传输到 HDFS,Flume 配置文件必须包含有关从何处拾取数据以及数据推送到何处的信息。提供此信息非常简单;Flume 的源组件从源或数据生成器中拾取日志文件,并将其发送到数据传输的代理
建筑
Apache Flume 的数据流体系结构有三个重要部分:数据生成源、Flume 代理和目标。Flume 代理由 Flume 源、通道和接收器组成。Flume 源从生成数据源(如 Web 服务器和 Twitter)的生成源中选取日志文件,并将其发送到频道。Flume 的接收器组件可确保其接收的数据同步到目标,可以是 HDFS、HDFS 上的 HBase 等数据库或 Spark 等分析工具。
以下是 HDFS 接收器的 Flume 基本体系结构:

源、通道和接收器组件是 Flume 代理的一部分。流式传输大量数据时,可以将多个 Flume 代理配置为从多个源接收数据,并且数据可以并行流式传输到多个目标。
Flume 体系结构可能因数据流要求而异这种灵活性非常有用。以下是如何在 Flume 体系结构中构建这种灵活性的两个示例:
- 从多个源流式传输到单个目标

在此体系结构中,数据可以从多个客户端流式传输到多个代理。数据收集器从所有三个代理中拾取数据,并将其发送到目标(集中式数据存储)。
- 从单个客户端流式传输到多个目标的数据
 客户
客户
在此示例中,两个 Apache 代理(可根据要求配置更多代理)拾取数据并将其同步到多个目标。
当需要将不同的数据集从一个客户端流式传输到两个不同的目标(例如,HDFS 和 HBase 用于分析目的)时,此体系结构非常有用。流流器可以识别特定的来源和目的地。
将 Flume 与分布式数据库和工具集成
除了能够将数据从多个源流式传输到多个目的地之外,Flume 还可以与各种工具和产品集成。它可以从几乎任何类型的源中提取数据,包括 Web 服务器日志文件、从 RDBMS 数据库生成的 CSV 文件和事件。同样,Flume 可以将数据推送到 HDFS、HBase 和 Hive 等目的地。
Flume 甚至可以与其他数据流工具(如 Kafka 和 Spark)集成。
以下示例演示了 Flume 的集成能力5雷姆;边距顶部: 1.5rem;字体系列:《ITC 章程》;无衬线;字体样式:正常;字体变异连字:正常;字体-变量-大写:正常;字体重: 400;字母间距:正常;孤儿: 2;文本对齐:开始;文本缩进: 0px;文本转换:无;空白:正常;寡妇: 2;字间距: 0px;-webkit-文本-描边宽度:0px;背景色: rgb (255, 255, 255);文字装饰风格:首字母;文本装饰颜色:首字母;”•如前所述,Flume 可以将数据从 Twitter 等网络源流式传输到驻留在 HDFS 上的目录。这是实时方案的典型要求。要做到这一点,Flume 必须配置为从源(源类型)拾取数据并将数据下沉到目标(目标类型)。此处的源类型是 Twitter,接收器类型为 HDFS-SINK。接收器完成后,Spark 等应用程序可以在 HDFS 上执行分析。

使用 Flume 将日志数据从 Kafka 流式传输到 HDFS
Kafka 是一个消息代理,它可以将网页上生成的实时数据和消息流式传输到像数据库这样的目标。如果需要将这些消息流式传输到 HDFS 上的位置,Flume 可以使用 Kafka 源提取数据,然后使用 HDFS 接收器将其同步到 HDFS。
Flume 可用于将日志数据流式传输到 Elasticsearch,这是一种流行的开源工具,可用于以可扩展的方式在分布式环境中快速执行对大量 JSON 数据的复杂文本搜索操作。它建立在 Lucene 之上,并利用 Lucene 的功能跨 JSON 执行基于索引的搜索。 Flume 可以将 JSON 文档从 Web 服务器流式传输到弹性搜索,以便应用程序可以从弹性搜索访问数据。JSON 文档可以在分布式环境中快速可靠地直接流式传输到 Elasticsearch。Flume 通过其弹性搜索接收器功能识别 ELK 目标。弹性搜索应安装 FlumeSink 插件,以便它将 Flume 识别为接受数据流的源。Flume 以索引文件的形式将数据流式传输到弹性搜索目标。默认情况下,每天流式传输一个索引文件,默认命名格式为”flume-yyyyy-MM-dd”,可在 Flume 配置文件中更改。 Apache Flume 确实有一些限制 此外,Flume 的数据流不是 100% 实时的。如果需要更多实时数据流,可以使用 Kafka 等替代方案。 虽然 Flume 可以将重复数据流式传输到目标,但可能很难识别重复数据。此挑战将因数据流式传输到的目标类型而异。 Apache Flume 是一个强大、可靠且分布式的工具,可帮助从多个来源流式传输数据,它是流式传输大量原始日志数据的最佳选择。它与现代实时数据流工具集成的能力使其成为一个受欢迎的高效选项。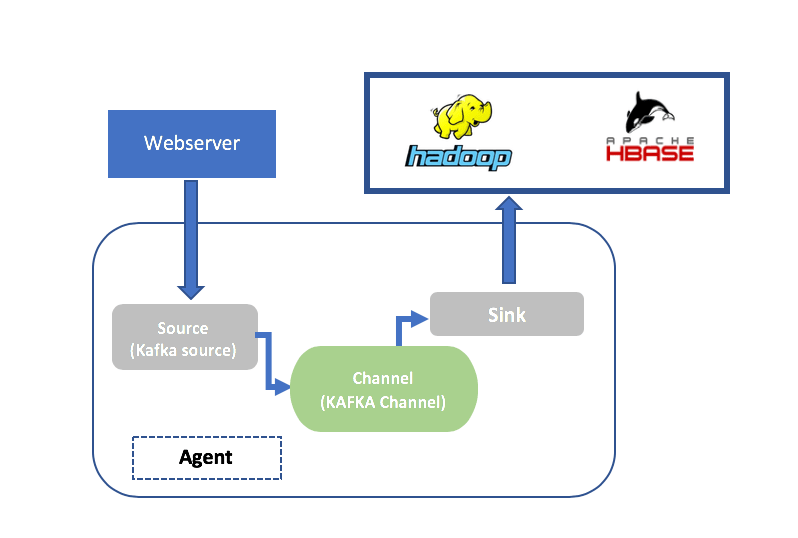 来自 HDFS 的来自 Kafka 的日志数据
来自 HDFS 的来自 Kafka 的日志数据
将日志数据流式传输到弹性搜索
阿帕奇Flume的局限性
总结