

本文描述了构建大型 React 应用程序的步骤。在使用 React 创建单页应用程序时,代码库很容易变得杂乱无章。这使得应用程序很难调试,更难更新或扩展代码库。
React 生态系统中有很多很好的库可以用来管理应用程序的某些方面,本文将深入介绍其中的一部分。除此之外,考虑到项目的可伸缩性,本文还列出了一些从项目开始就应该遵循的良好实践。说到这里,我们开始第一步——如何提前计划。
从画板开始
大多数情况下,开发人员都会跳过这一步,因为它与实际代码无关,但是不要低估它的重要性,稍后你将看到这一点。
为什么要做应用程序计划
在开发软件时,开发人员必须管理许多变化的部分。事情很容易出错。有这么多的不确定性和障碍,每一件事你都不希望它超时。
这是计划阶段可以避免的。在这一阶段,你要写下应用程序的每一个细节。与在脑海中想象整个过程相比,提前预测构建这些单独的小模块所需的时间要容易得多。
如果你有多个开发人员在这个大型项目中工作(你会的),有这样一个文档将使彼此之间的沟通更加容易。事实上,这个文档中的内容可以分配给开发人员,这将使每个人都更容易知道其他人在做什么。
最后,因为有了这个文档,你将对自己在项目上的进展有一个非常好的了解。对于开发人员来说,从他们正在开发的应用程序的一个部分切换到另一个部分,然后再回到这个部分要比他们希望的延后许多,这非常常见。
步骤 1:视图和组件
我们需要确定应用中每个视图的外观和功能。最好的方法是绘制应用程序的每个视图,使用一个模型工具或在纸上,这样你就可以很好地了解和计划每个页面上的信息和数据。
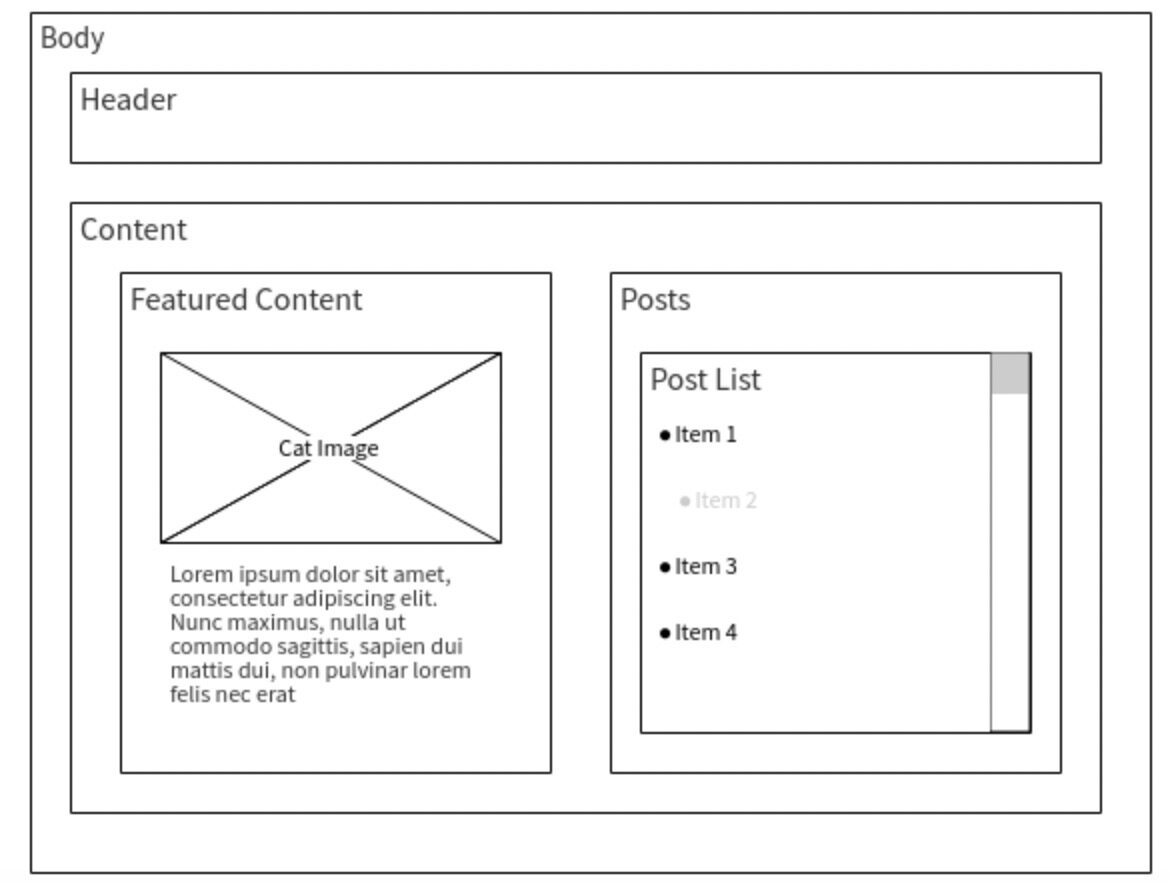
在上面的模型中,你可以很容易地看到应用程序的子容器和父容器。稍后,这些模型的父容器将是我们的应用程序的页面,较小的项将放在应用程序的组件文件夹中。绘制好模型后,在其中每个模型中写上页面和组件的名称。
步骤 2:APP 内部的 actions 和 events
在确定了组件之后,计划将在每个组件中执行的操作。这些操作稍后将从这些组件发出。
考虑一个电子商务网站,它的主屏幕上有一个特色产品列表。列表中的每一项都是项目中的一个单独组件。组件名称为 ListItem。
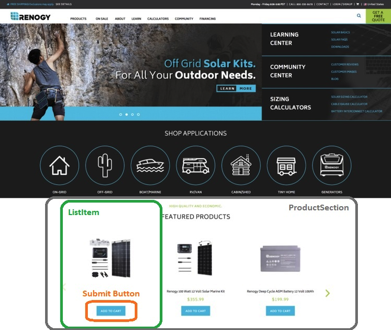
因此,在这个应用程序中,产品部分的组件执行的操作是 getItems。此页面上的其他一些操作可能包括 getUserDetails、getSearchResults 等。
重点是观察每个组件上的动作或用户与应用程序数据的交互。在修改、读取或删除数据的地方,请注意每个页面的操作。
步骤 3:数据和模型
应用程序的每个组件都有一些相关的数据。应用程序的多个组件都使用的相同的数据,将成为集中化状态树的一部分。该状态树将由redux 管理。
该数据由多个组件使用,因此,当它在一个位置被更改时,其他组件也会反映出更改后的值。
在应用程序中列出这些数据,因为这些数据将构成应用程序的模型,你将根据这些值创建应用程序的 reducer。
复制代码
products: { productId: {productId, productName, category, image, price}, productId: {productId, productName, category, image, price}, productId: {productId, productName, category, image, price},}
考虑上面的电子商务商店的例子。“特色产品”部分和“新产品”部分所使用的数据类型是相同的,即 products。这将是这个电子商务应用的一个 reducer。
在记录了你的操作计划之后,接下来的部分将介绍设置应用程序的数据层的一些细节。
操作、数据源和 API
随着应用程序的增长,redux store 经常会有冗余的方法和不合理的目录结构,变得很难维护或更新。
让我们看看如何做些调整,以确保 redux store 的代码保持干净。从一开始就使模块更具可重用性,可以省去大量的麻烦,尽管这在一开始这可能看起来很麻烦。
API 设计和客户端应用
在设置数据存储时,从 API 接收数据的格式对 store 的布局有很大的影响。通常,在将数据提供给 reducer 之前,需要对数据进行格式化。
关于在设计 API 时应该做什么和不应该做什么,有很多争论。后端框架、应用程序大小等因素会进一步影响 API 的设计。
就像在后端应用程序中一样,将格式化和映射等实用程序函数保存在单独的文件夹中。确保这些函数没有副作用——参见JavaScript Pure Functions。
复制代码
export function formatTweet (tweet, author, authedUser, parentTweet) { const { id, likes, replies, text, timestamp } = tweet const { name, avatarURL } = author return { name, id, timestamp, text, avatar: avatarURL, likes: likes.length, replies: replies.length, hasLiked: likes.includes(authedUser), parent: !parentTweet ? null : { author: parentTweet.author, id: parentTweet.id, } }}
在上面的代码片段中,formatTweet 函数向前端应用程序的 tweet 对象插入一个新键 parent,并根据参数返回数据,而不会影响到外部数据。
你可以更进一步,将数据映射到预定义的对象,而该对象的结构是特定于前端应用程序的,并且对某些键进行了验证。让我们讨论一下负责进行API 调用的部分。
数据源设计模式
我在本节中描述的这部分内容将被 redux action 直接用于修改状态。根据应用的大小(以及你有多少时间),你可以通过以下两种方式中的其中一种设置数据存储:
-
不使用 Courier
-
使用 Courier
不使用 Courier
以这种方式设置数据存储需要你为每个模型分别定义 GET、POST 和 PUT 请求。
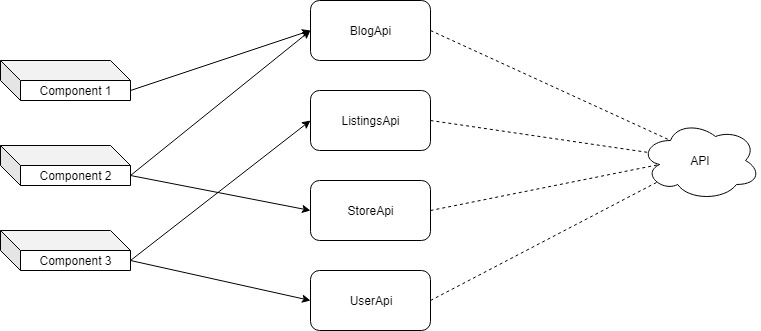
在上图中,每个组件分派调用不同数据存储方法的 action。这就是 BlogApi 文件中的 updateBlog 方法。
复制代码
function updateBlog(blog){ let blog_object = new BlogModel(blog) axios.put('/blog', { ...blog_object }) .then(function (response) { console.log(response); }) .catch(function (error) { console.log(error); });}
这种方法节省时间。首先,它还允许你进行修改,而不必过多担心副作用。但是会有很多冗余代码,执行批量更新非常耗时。
使用 Courier
从长远来看,这种方法使维护或更新变得更容易。代码库可以很干净,这样就省去了通过 axios 进行重复调用的麻烦。
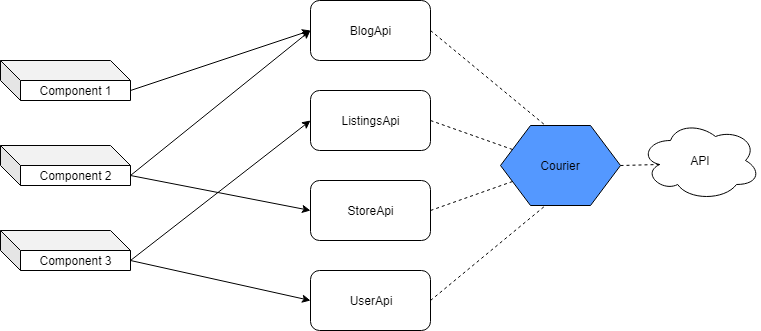
然而,这种方法需要时间来进行初始设置,缺乏灵活性。这是一把双刃剑,因为它阻止你做一些不寻常的事情。
复制代码
export default function courier(query, payload) { let path = `${SITE_URL}`; path += `/${query.model}`; if (query.id) path += `/${query.id}`; if (query.url) path += `/${query.url}`; if (query.var) path += `?${QueryString.stringify(query.var)}`; return axios({ url: path, ...payload }) .then(response => response) .catch(error => ({ error }));}
下面是一个基本的 courier 方法的样子,所有的 API 处理程序都可以简单地调用它,通过传递以下变量:
-
一个查询对象,其中包含 URL 相关的具体信息,如模型名称、查询字符串等;
-
Payload,其中包含请求头和请求体。
API 调用和 App 内部 Action
在使用 redux 时,一个突出的问题是预定义 action 的使用。它使得整个应用程序中的数据变化更加可预测。
尽管在一个大型应用程序中定义一堆常量看起来要做很多工作,但是计划阶段的步骤 2 使它变得更加容易。
复制代码
export const BOOK_ACTIONS = { GET:'GET_BOOK', LIST:'GET_BOOKS', POST:'POST_BOOK', UPDATE:'UPDATE_BOOK', DELETE:'DELETE_BOOK',} export function createBook(book) { return { type: BOOK_ACTIONS.POST, book }} export function handleCreateBook (book) { return (dispatch) => { return createBookAPI(book) .then(() => { dispatch(createBook(book)) }) .catch((e) => { console.warn('error in creating book', e); alert('Error Creating book') }) }} export default { handleCreateBook,}
上面的代码片段展示了一种简单的方法,可以将数据源的 createBookAPI 方法与 redux action 混合在一起。handleCreateBook 方法可以安全地传递给 redux 的 dispatch 方法。
另外请注意,上面的代码位于项目的 actions 目录中,我们同样可以为应用程序的其他各种模型创建包含 action 名称和处理程序的 JavaScript 文件。
Redux 集成
在本节中,我将系统地讨论如何扩展 redux 的功能来处理更复杂的应用程序操作。如果实现得不好,这些东西可能会破坏 store 的模式。
JavaScript 生成器函数能够解决与异步编程相关的许多问题,因为它们可以随意启动和停止。Redux Sagas 中间件使用这个概念来管理 app 中不纯净的地方。
管理 App 中不纯净的地方
考虑这样一个场景。你被要求开发一个房产发现应用程序。客户想要迁移到一个新的更好的网站。REST API 已经就绪,你已经获得了 Zapier 上每个页面的设计,并且已经起草了一个计划,可是问题来了。
他们公司使用 CMS 客户端已经很长时间了,他们非常熟悉它,因此不希望仅仅为了写博客而更换一个新的客户端。此外,复制所有的旧博客将是一个麻烦。
幸运的是,CMS 有一个可读的 API,可以提供博客内容。不幸的是,假若你已经编写了一个 courier 方法,而 CMS API 位于另一个具有不同语法的服务器上。
这是应用中一个不纯净的地方,因为你正在适应一个新的 API,用于简单地获取博客。这可以通过使用 React Sagas 来处理。
考虑下面这幅图。我们使用 Sagas 在后台获取博客。这就是整个交互的过程。
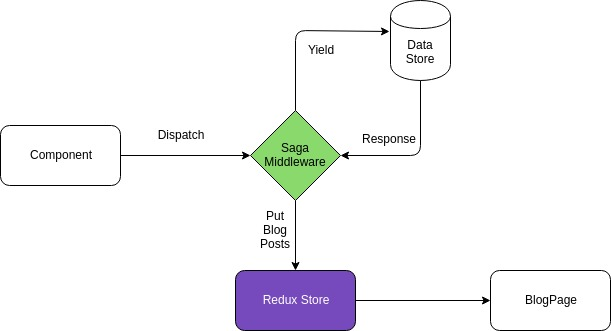
这里,组件执行 Dispatch action,即 GET.BLOGS,在应用中,使用 redux 中间件拦截请求,在后台,生成器函数将从数据存储中获取数据并更新 redux。
下面是一个示例,展示了博客 sagas 的生成器函数是什么样子。你还可以使用 sagas 存储用户数据(例如身份验证令牌),因为这是另一个不纯净的 action。
复制代码
... function* fetchPosts(action) { if (action.type === WP_POSTS.LIST.REQUESTED) { try { const response = yield call(wpGet, { model: WP_POSTS.MODEL, contentType: APPLICATION_JSON, query: action.payload.query, }); if (response.error) { yield put({ type: WP_POSTS.LIST.FAILED, payload: response.error.response.data.msg, }); return; } yield put({ type: WP_POSTS.LIST.SUCCESS, payload: { posts: response.data, total: response.headers['x-wp-total'], query: action.payload.query, }, view: action.view, }); } catch (e) { yield put({ type: WP_POSTS.LIST.FAILED, payload: e.message }); } }...
它监听类型为 WP_POSTS.LIST 的操作,然后从 API 获取数据。它分派另一个 action WP_POSTS.LIST.SUCCESS,然后更新博客 reducer。
Reducer 注入
对于大型应用程序而言,预先规划每一个模型是不可能的,而且,随着应用程序的增长,这种技术节省了大量的工时,它还允许开发人员添加新的 reducer,而无需重新布局整个 store。
有一些库可以让你立即完成这项工作,但是我更喜欢这种方法,因为你可以灵活地将它与旧代码集成在一起,而不需要太多的重新布局。
这是一种代码分割的形式,正在被社区积极采用。我将使用这个代码片段作为一个例子来展示 reducer 注入器的样子及其工作原理。让我们先看看它是如何与 redux 集成的。
复制代码
... const withConnect = connect( mapStateToProps, mapDispatchToProps,); const withReducer = injectReducer({ key: BLOG_VIEW, reducer: blogReducer,}); class BlogPage extends React.Component { ...} export default compose( withReducer, withConnect,)(BlogPage);
上面的代码是 BlogPage.js 的一部分,它是我们应用程序的组件。
这里我们导出的不是 connect 而是 compose,这是 redux 库中的另一个函数,它所做的是,允许你传递多个函数,这些函数可以从左到右读取,也可以从下到上读取。
Compose 所做的就是让你编写深度嵌套的函数转换,而不需要右移代码。不要太相信它!—— 来自Redux 文档
最左边的函数可以接收多个参数,但之后只有一个参数传递给该函数。最终,将使用最右边函数的签名。这就是我们将 withConnect 作为最后一个参数传递的原因,这样 compose 就可以像 connect 一样使用了。
路由和 Redux
人们喜欢在他们的应用程序中使用一系列工具来处理路由,但在本节中,为了使用 redux,我将坚持使用react router dom并扩展它的功能。
使用 react router 最常见的方法是用 BrowserRouter 标记封装根组件,用 withRouter() 方法封装子容器并输出它们示例。
通过这种方式,子组件接收到一个 history prop,其中包括一些特定于用户会话的属性和一些可用于控制导航的方法。
在大型应用程序中,以这种方式实现可能会引起问题,因为没有 history 对象的中心视图。此外,没有像这样通过 route 组件渲染的组件不能访问它:
复制代码
[code language="plain"][/code]
封装在 React.Suspense 中的组件会在加载主要内容时加载后备 prop 中指定的组件。务必确保后备 prop 中的组件是轻量级的。
使用 Suspense
自适应组件
在一个大型前端应用程序中,重复的模式开始出现,即使它们起初可能不那么明显。你不禁觉得,自己以前竟然干过这种事。
例如,在你正在构建的应用程序中有两种模型:赛道和汽车。汽车列表页面有正方形的平铺块,每个平铺块上都有一幅图像和一些描述。
而赛道列表页面有一幅图像和一些描述,以及一个小框,表明赛道是否提供食物。
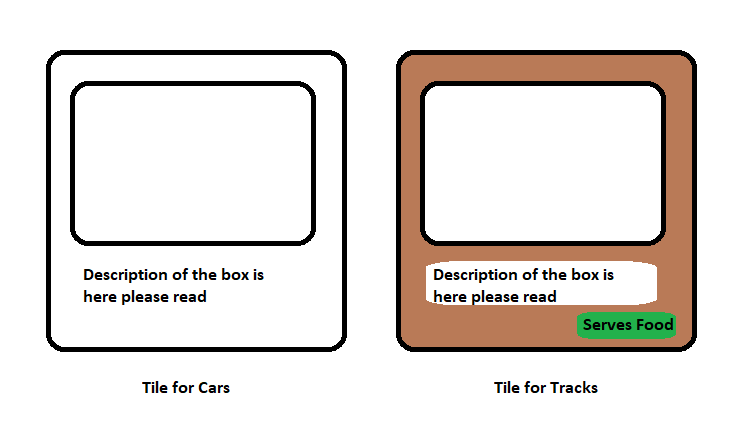
上面的两个组件在样式(背景颜色)上有一点不同,而赛道平铺块上有额外的信息。这个例子中只有两个模型。大型应用程序中会有很多模型,为每个模型创建单独的组件是有悖常理的。
你可以通过创建可以感知其加载上下文的自适应组件来避免重写类似的代码。考虑下应用搜索栏。
![]()
它将在应用程序的多个页面上使用,功能和外观略有不同。例如,它在主页上会稍大一些。要处理这个问题,你可以创建一个单独的组件,它将根据传递给它的 prop 进行渲染。
复制代码
static propTypes = { open: PropTypes.bool.isRequired, setOpen: PropTypes.func.isRequired, goTo: PropTypes.func.isRequired,};
使用此方法,还可以在这些组件中切换 HTML 类,以控制它们的外观。
另外一个可以使用自适应组件的例子是分页助手。应用程序的几乎每个页面都有它,它们或多或少是相同的。

如果你的 API 遵循不变的设计模式,那么你唯一需要传递给自适应分页组件的 prop 就是 URL 和每个页面上要显示的项。
结论
多年来,React 生态系统已经成熟,以至于几乎没有必要在开发的任何阶段重新造轮子。虽然这非常有用,但也导致你在选择适合项目的组件时更加复杂。
每个项目在规模和功能方面都是不同的。没有一种方法或泛化每次都有效,因此,在实际编码开始之前有一个计划是必要的。
在这样做的时候,很容易就能识别出哪些工具适合你,哪些工具是多余的。一个只有 2-3 个页面和最少 API 调用的应用不需要像上面讨论的那样复杂的数据存储。我想说的是,小项目不需要 REDUX 。
当我们提前计划并绘制出应用中将要出现的组件时,我们可以看到页面之间有很多重复。只需重用代码或编写智能组件就可以节省大量的工作。
最后,我想说的是,数据是每个软件项目的支柱,对于 React 应用程序也是如此。随着应用的增长,数据量和与之相关的操作很容易让程序员应接不暇。事实证明,预先确定关注点(如数据存储、reducer action、sagas 等)可以带来巨大的优势,并使得编写它们变得更加有趣。



