
米尔武斯项目:github.com/milvus-io/milvus
问题答题系统在自然语言处理领域是常用的。它用于以自然语言的形式回答问题,并具有广泛的应用。典型应用包括智能语音交互、在线客户服务、知识获取、个性化情感聊天等。
大多数问题回答系统可以分为生成和检索问题回答系统、单轮问答和多轮问答系统、开放式问题解答系统和特定的答题系统。
本文主要介绍为特定领域设计的QA系统,通常称为智能客户服务机器人。过去,构建客户服务机器人通常需要将域知识转换为一系列规则和知识图。建造过程严重依赖”人”的智慧。一旦场景被改变,需要大量的重复工作。
随着深度学习在自然语言处理(NLP)中的应用,机器阅读可以直接从文档中自动找到匹配问题的答案。深度学习语言模型将问题和文档转换为语义向量,以找到匹配的答案。
本文使用谷歌的开源BERT模型和Milvus,一个开源向量搜索引擎,快速构建基于语义理解的Q和A机器人。
整体架构
本文通过语义相似性匹配实现答题系统。一般施工过程如下:
- 获取大量带有特定字段(标准问题集)答案的问题。
- 使用 BERT 模型将这些问题转换为特征矢量并将其存储在 Milvus 中。Milvus 将同时为每个要素矢量分配矢量 ID
当用户提问时:
- BERT 模型将其转换为要素矢量。
- Milvus 执行相似性搜索并检索与问题最相似的 ID。
- PostgreSQL 返回相应的答案。
系统体系结构图如下所示(蓝线表示导入过程,黄线表示查询过程):

接下来,我们将向您展示如何逐步构建在线 Q 和 A 系统。
构建 Q 和 A 系统的步骤
开始之前,您需要安装米尔武斯和 PostgreSQL。有关具体的安装步骤,请参阅米尔武斯官方网站。
1. 数据准备
本文的实验数据来自https://github.com/chatopera/insuranceqa-corpus-zh
数据集包含一个问题,并回答与保险业相关的数据对。在本文中,我们从中提取20,000个问答对。通过这组问答数据集,您可以快速为保险业构建客户服务机器人。
2. 生成要素矢量
此系统使用 BERT 预先训练的模型。在开始服务之前,请从以下链接下载:https://storage.googleapis.com/bert_models/2018_10_18/cased_L-24_H-1024_A-16.zip
使用此模型可将问题数据库转换为用于将来相似性搜索的要素矢量。有关 BERT 服务的详细信息,请参阅https://github.com/hanxiao/bert-as-service。
3. 进口到米尔武斯和波斯特格雷SQL
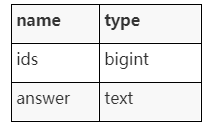
规范化并导入生成的要素向量导入到米尔武斯,然后导入米尔武斯返回的 IT 和 PostgreSQL 的相应答案。下面显示了 PostgreSQL 中的表结构:

4. 检索答案
用户输入一个问题,并且通过 BERT 生成要素矢量后,他们可以在 Milvus 库中找到最类似的问题。本文使用可加入距离来表示两个句子之间的相似性。由于所有矢量都规范化,因此两个要素矢量的偶数离线距离越近,相似性就越高。
实际上,您的系统库中可能没有完全匹配的问题。然后,您可以设置 0.9 的阈值。如果检索到的最大相似距离小于此阈值,系统将提示它不包含相关问题。

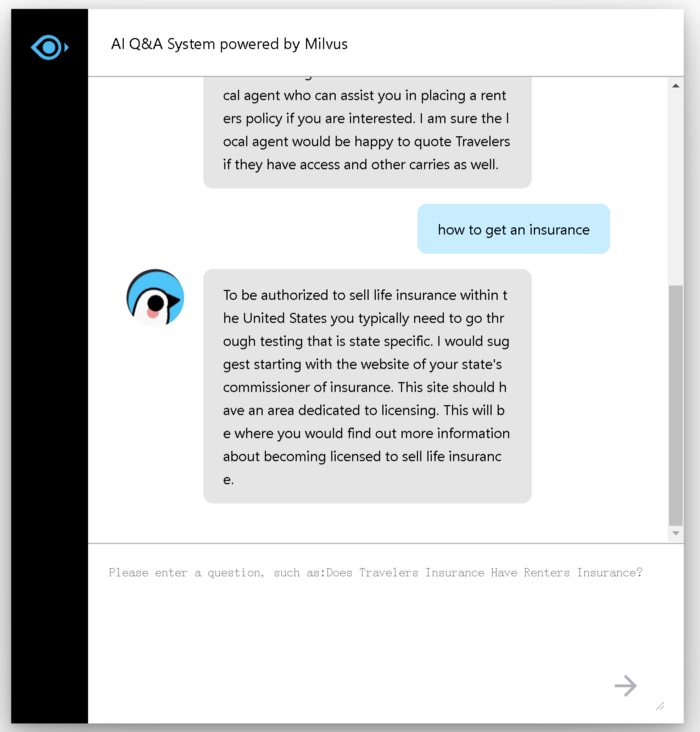
系统演示
下面显示了系统的示例接口:
在对话框中输入您的问题,您将收到相应的答案:
总结
阅读本文后,我们希望您发现构建 Q 和 A 系统很容易。
使用 BERT 模型,您不再需要事先对文本语库进行排序和组织。同时,由于开源矢量搜索引擎 Milvus 的高性能和高可扩展性,您的 QA 系统可以支持多达数亿个文本的群数。
