
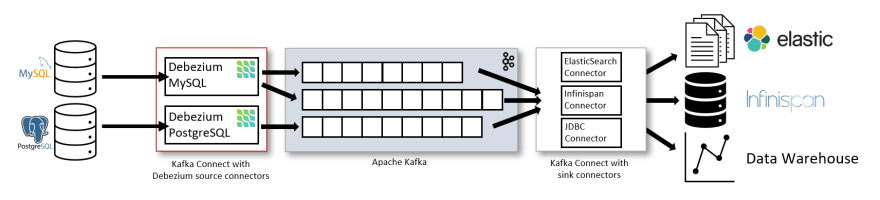
更改数据捕获 (CDC)是一种用于跟踪数据库表中的行级更改以响应创建、更新和删除操作的技术。不同的数据库使用不同的技术来公开这些更改数据事件 – 例如,PostgreSQL 中的逻辑解码、MySQL 二进制日志(binlog)等。这是一项强大的功能,但只有当有办法利用这些事件日志并使其可用于依赖于该信息的其他服务时,此功能才有用。
德贝齐姆就这样做了!它是一个分布式平台,基于不同数据库中可用的更改数据捕获功能。它提供了一组Kafka Connect 连接器,这些连接器利用数据库表中的行级更改(使用 CDC),并将其转换为事件流。这些事件流被发送到阿帕奇卡夫卡,这是一个可扩展的事件流平台 – 一个完美的适合!更改日志事件在 Kafka 中后,它们将可用于所有下游应用程序。
这与 Kafka Connect JDBC 连接器采用的”轮询”技术不同
图表 (从debezium.io) 很好地总结了它!
此博客是开始使用 Debezium 在 Azure 上设置基于 Azure 的更改数据捕获指南,Azure DB 用于 PostgreSQL 和 Azure 事件中心(对于 Kafka)。它将使用Debezium PostgreSQL 连接器将数据库修改从 PostgreSQL 流式传输到 Azure 事件中心中的 Kafka 主题
相关的配置文件在 GitHub 存储库中可用在 Azure 上设置 PostgreSQL 和 Kafka
本节将提供有关如何为 PostgreSQL 配置 Azure 事件中心和 Azure DB 的指针。所有你需要的是一个微软 Azure帐户 –继续前进, 并注册一个免费的!
邮政的 Azure DB
PostgreSQL 的 Azure DB 是基于开源 PostgreSQL 数据库引擎的社区版本的托管关系数据库服务,提供两种部署模式。
在编写本文时,它支持 PostgreSQL 版本
11.6您可以使用各种选项在 Azure 上设置 PostgreSQL,包括 Azure门户、Azure CLI、Azure PowerShell 、ARM 模板。 Azure CLI完成操作后,您可以使用您最喜爱的编程语言(如Java、.NET、Node.js、Python、Go 等Node.js)轻松连接到数据库Python.NETGomicrosoft.com/azure/postgresql/overview?WT.mc_id=dzone-blog-abhishgu#azure-database-for-postgresql—hyperscale-citus”rel=”无跟随”=超量量(Citus)是另一种部署模式,可用于”接近或已超过 100 GB 数据的工作负载”。
请确保您将以下 PostgreSQL 相关信息放在方便的位置,因为您将需要它们来配置后续部分中的 Debezium 连接器 – 数据库主机名(和端口)、用户名、密码
Azure 事件中心
Azure 事件中心是一个完全托管的数据流平台和事件引入服务。它还提供了一个支持阿帕奇 Kafka 协议 1.0 及更晚的 Kafka 终结点,并可与 Kafka 生态系统中的现有 Kafka 客户端应用程序和其他工具合作
Kafka Connect,包括(在此博客中演示)。您可以使用 Azure 门户、Azure CLI、PowerShell或 ARM 模板创建 Azure 事件中心命名空间和其他资源。 PowerShell为了确保启用 Kafka 功能,您只需要选择 或
StandardDedicated层(因为基本层不支持事件中心上的 Kafka)。设置后,请确保您保持连接字符串方便,因为您将需要它来配置 Kafka 连接。可以使用 Azure门户或 Azure CLI进行此功能
安装卡夫卡
要运行 Kafka 连接, 我将使用本地 Kafka 安装只是为了方便apache.org/downloads”rel=”不跟随”-只需下载阿帕奇卡夫卡,解压缩其内容,你很好去!
下载 Debezium 连接器并启动 Kafka 连接
首先,克隆此 Git 存储库:
Java
Ⅹ1git克隆https://github.com/abhirockzz/debezium-azure-postgres-cdc2cd debezium–azure–后灰色–cdc下载 Debezium PostgreSQL 源连接器 JARs
1.2.0是撰写本文时的最新版本Java
x1DEBEZIUM_CONNECTOR_VERSION=1.2。023卷曲https://repo1.maven.org/maven2/io/debezium/debezium-连接器-postgres/$DEBEZIUM_CONNECTOR_VERSION]。最终/二十年代连接器-postgres-$DEBEZIUM_CONNECTOR_VERSION] 。Final - plugin. tar. gz - 输出 debezium - 连接器 - postgres. tar. gz45焦油 -xvzfdebezium-连接器-postgres.焦油.gz现在,您应该会看到名为 的新文件夹
debezium-connector-postgres。将连接器 JAR 文件复制到 Kafka 安装:Java








{kind=link}
{kind=link}
{kind=link}