

大数据文摘出品
来源:medium
编译:LYLM、胡笳
自2010年创办以来,Kaggle作为著名的数据科学竞赛平台,一直都是机器学习领域发展趋势的风向标,许多重大突破都在该平台发生,数以千计的从业人员参与其中,每天在Kaggle论坛上都有着无数的讨论。
各种类型的挑战赛(计算机视觉、语音、表格处理等等)都会在这个在线平台发布,而自然语言处理(NLP)问题最近亦备受关注。诚然,过去几个月里,我们已经见证这一领域有好几项振奋人心的创新,而目前流行的的则是transformers和预训练语言模型。
Medium上一位从事NLP的博主就通过Kaggle竞赛梳理了一遍自然语言处理的发展历史,看看NLP这些年都是怎样一路走来的。
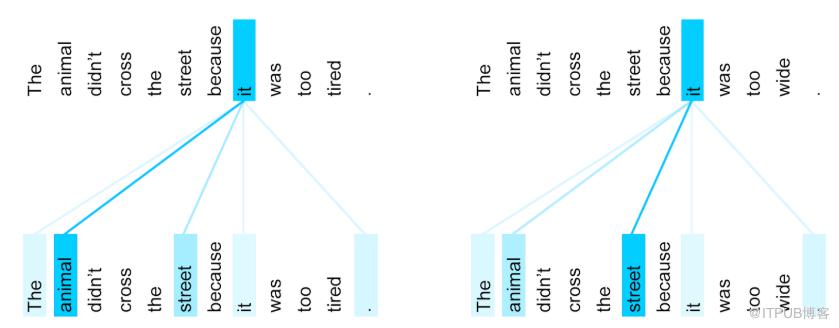
左边:动物没有过马路,因为它太累。右边:动物没有过马路,因为它太宽。基于语境,句子的最后一词“它”在这可指“动物”或是“马路”,摘自谷歌transformers词条。
2016以前:词袋(bag of words)模型和TF-IDF算法盛行
在2016年之前,解决(或者说赢得)Kaggle自然语言处理挑战的标准方法是采用词袋模型(即计算文章中各个单词出现的次数)来建立特征输入机器学习分类器,典型的有朴素贝叶斯算法。稍微完善些的则有TF-IDF算法。
这种方法被应用在如StumbleUpon Evergreen分类挑战。
StumbleUpon是一个推荐引擎,根据用户的兴趣向其推荐相关的网页。网页分为两种,一种是暂时的,在短期内有价值的网页,另一种是长期的,一直都有效果的网页,该挑战的目的就是对这两种页面进行二元分类。
数据集链接:
https://www.kaggle.com/c/stumbleupon
这里顺便提一句,在2013年解决该难题的冠军是François Chollet——就是两年后编写出Keras的那个人。

François Chollet
2016-2019:词嵌入模型+Keras以及TensorFlow 的兴起
在2015年,开始出现稠密词表征(dense word representations)库,如Gensim库(包括Word2Vec和GloVe)。其他预训练嵌入模型也陆续出现,像Facebook的FastTest或是Paragram。
同时,拥有大量用户、简单可用的神经网络框架的首发版本也开始流行,即上文提到的Keras和TensorFlow。它们不再仅使词袋模型,开始使用词序模型捕获句意。
然而要运行深度神经网络,还有最后一项难题亟待解决:需要高处理性能。成本越来越低的GPU解决了这个难题。Kaggle平台在2019年3月被谷歌收购后,平台(通过合作式的Notebooks内核)可以向用户免费提供GPU使用。
从那时起,词嵌入和神经网络(RNN,LSTM,GRU等等,以及基于此的改进,如attention)这些可行方案就成了解决Kaggle中自然语言处理难题的标准方法
这时候就不得不说一句:永别了,TF_IDF!
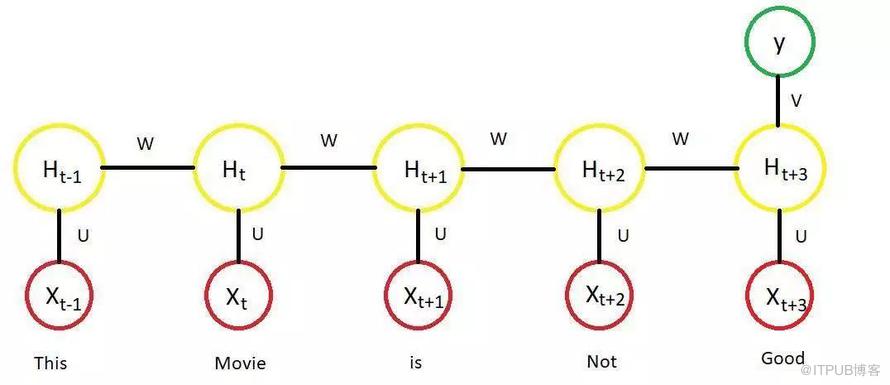
使用RNN编码单词序列
2018-2019:PyTorch杀出重围
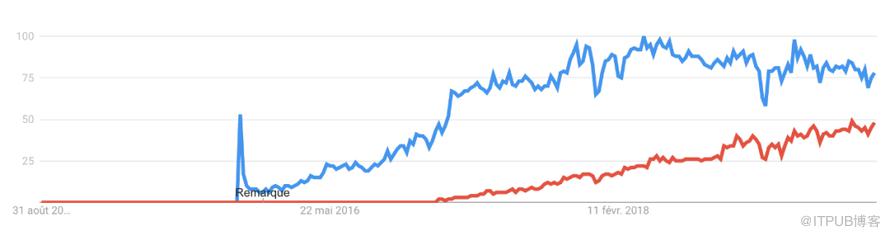
近几个月,一个新的神经网络框架PyTorch在数据科学界越来越受关注。
在此不讨论TensorFlow和PyTorch的优劣,但可以肯定的是,在Kaggle上越来越多的人开始使用PyTorch了。平台上经常有PyTorch的在线笔记和教程发布。
2019年:transformers和预训练语言模型诞生
如上所述,直至目前为止,词嵌入模型(在大量的无标注数据上进行预训练)仍是解决自然语言处理难题的标准方法,利用此模型初始化神经网络的第一层,然后在特定任务(可能是文本分类,问答或自然语言推断等等)的数据上训练其他层。
但如果仔细想想,这种方式其实并非最优。事实上,每当需解决一项新问题时,你基本需要从零开始学起。通过词嵌入进行初始化的模型需要从零开始学习如何从单词序列中提取含义——哪怕那是语言理解的最核心部分。
transformers出现后,这是2018年发生的关键范式转变:从仅初始化模型的第一层到使用阶梯式表达对整个模型进行预训练。这也产生了新的训练模式:将信息从预训练语言模型转移到下游任务(也称为迁移学习)。
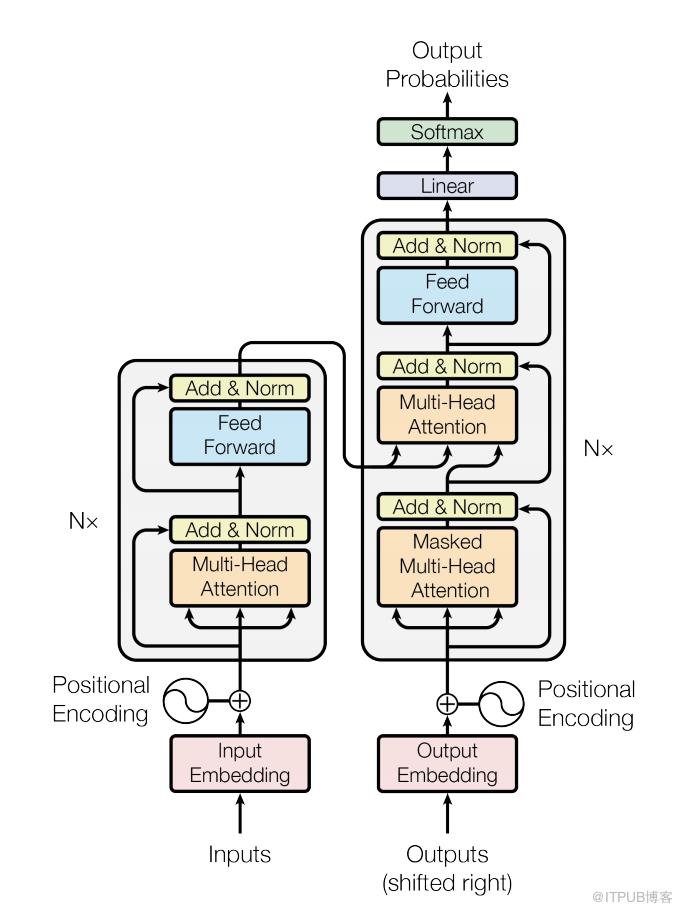
实际上,使用预训练语言模型的最好方式是利用Hugging Face(由法国企业家创立,目前总部在美国,和我们一样毕业于Station F微软AI工厂的校友)开发的transformers库。目前它与PyTorch和TensorFlow兼容。
如果你想用它更上层的封装来完成一些诸如文本分类的简单任务,可以看看 simple-transformer 库。
相关链接:
simple-transformer库的github:https://github.com/ThilinaRajapakse/simpletransformers
下一步会更有趣
上一代预训练语言模型已有现成的库可供大家使用,这使得大众都可以进行尖端自然语言处理技术的研究和实验。
可以预见的是,这些技术在后续Kaggle自然语言处理比赛中的应用会很有趣,比如最近的TensorFlow 2.0问答挑战,需要预测用户关于维基百科页面内容提出的问题的真实答案。让我们拭目以待!
链接:https://medium.com/@Zelros/from-bag-of-words-to-transformers-10-years-of-practical-natural-language-processing-8ccc238f679a