
摘要
随着HDFS数据量越来越大,NameNode内存已不足以装下全部元数据,这限制了HDFS的扩展。社区提出的RBF(Router Based Federation)比较高效地解决了这个问题。它将用户视角的目录拆分到多组互相独立的子集群(名字空间或者NameSpace)中,这一过程被称为挂载。Router层记录挂载表信息,并转发用户请求,使得RBF看起来和普通HDFS一样。 但RBF也有自己的问题:
- 不支持跨NameSpace的rename。
- NameSpace随着使用会逐渐不均衡,社区目前还没有用于均衡NameSpace的工具。
为了解决这两个问题,我们设计了HFR(HDFS Federation Rename)。它支持跨NameSpace rename目录和文件,也可以用来做NameSpace负载均衡。介绍 HFR的思想是:先把源目录树从源NameNode移动到目标NameNode,再将所有数据块从源pool迁移到目标pool,最后更新Router上的挂载表,之后client就能从新的NameNode访问到目录了。
在元数据和文件数据都不断变化的情况下来实现迁移非常困难,所以HFR中引入了一个额外的限制来简化这个问题:HFR作业执行期间,所有会修改元数据和文件数据的操作都被禁止掉(禁止写操作)。后面我们会看到,这个限制大大简化了HFR的实现。 HFR作业被划分为5个阶段:Prepare、 SaveTree、 GraftTree、 HardLink和Finish:
- Prepare: 完成权限和quota检查,并锁定src-path,禁止写操作。
- SaveTree: 向src-NameNode发送saveTree() RPC,令其将目录树序列化到外部存储中。
- GraftTree: 向dst-NameNode发送graftTree() RPC,dst-NameNode会读取并反序列化上一步的目录树,并接到自己的目录树上。
- HardLink: RBF集群的DataNode是共享的,我们可以使用硬连接来完成数据块传输。本阶段会先收集所有块的位置信息,生成HardLink计划,最后向DataNode发送RPC实现块的hard link。
- Finish: 完成校验和清理工作,并更新Router的挂载表。
为了将这5个阶段整合起来,我们设计了一个状态机模型。HFR作业是一个状态自动机,每一个阶段对应一个状态。如果一个阶段失败了,则跳转到错误处理状态,否则跳转到下一阶段状态。
我们引入新角色Scheduler来负责HFR作业的启动、执行、重试和恢复。 接下来我们会分别介绍SaveTree阶段(第二部分)、GraftTree阶段(第三部分)、HardLink(第四部分)、Scheduler模型(第五部分)、性能(第六部分)、总结(第七部分)。我们不讨论Prepare阶段和Finish阶段,因为这两个阶段比较简单,也比较多变,不同的用户可以根据自己需要实现不同的Prepare和Finish阶段。SaveTree
在SaveTree阶段,我们引入了saveTree() RPC,它会保存src-path目录树到外部存储中,包括树的结构、INodes、以及Blocks。saveTree() RPC还有一个特点是,它假定src-path已经被锁住且处于不可变的状态,因此不会做额外措施来保护目录树不被改变,即不会做禁写。下面分别讨论保存src-path到外部存储的过程和saveTree()不做禁写的原因。
saveTree()调用会产生两个文件:TREE-FILE和TREE-META,这两个文件被保存在外部存储中。TREE-FILE中保存了整个目录树,TREE-META则保存目录树的各种统计信息。saveTree() RPC首先深度优先遍历src-path,并将所有INodeDirectory和INodeFile序列化到TREE-FILE中。序列化的方式和NameNode生成Image的方式相同,这样目录的全部属性(ACL、Xattr等)都会被保留。INode的写入顺序与遍历顺序相同,因此目录树的结构也可以被保留。遍历的同时,saveTree() RPC会计算src-path的name消耗、space消耗和块总数,并将它们写入到TREE-META中(后面的GraftTree阶段会解释为什么需要生成TREE-META)。
SaveTree阶段不做禁写操作有两个原因,一是要保持简单。saveTree() RPC只是简单地遍历目录树并写两个文件,整个过程都是无锁的,也没有edit log,是非常轻量级的操作。二是保持灵活,我们可以让SaveTree之前的阶段来负责禁写,它可以根据自身需要用任何它想使用的手段,比如简单的取消src-path的x权限,或是复杂些的逐个子目录取消w权限等等。这些自定义的阶段都可以与SaveTree阶段组合,来满足不同需求。saveTree()的结果文件也不被限制只能用于HFR,也可以被用来其他用途,譬如DEBUG。如果用户愿意,他们可以在没有禁写的目录上调用saveTree(),这样做虽然不会损坏NameNode,但也无法保证写到外部存储的目录树的完整性。
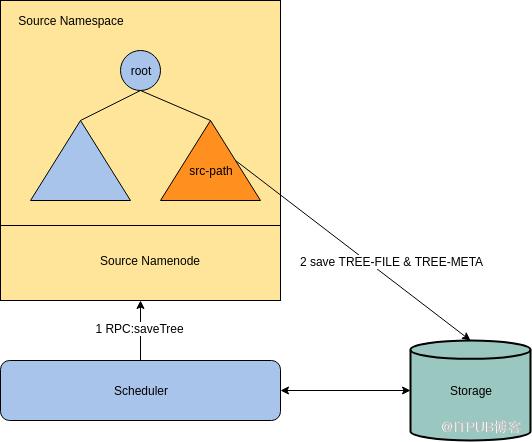
Figure 1: The process of saveTree.GraftTree GraftTree阶段是HFR的核心,graftTree() RPC读取TREE-FILE和TREE-META并构造dst-path。过程如下:
- 读取TREE-META文件。
- 合法性检查,包括路径名合法性、权限、quota等。
- 预分配INode Id和Block Id。
- 读取TREE-FILE,反序列化并构造目录树。
- 将构造好的目录树接到NameNode根目录树上,将所有Id添加到对应Map。
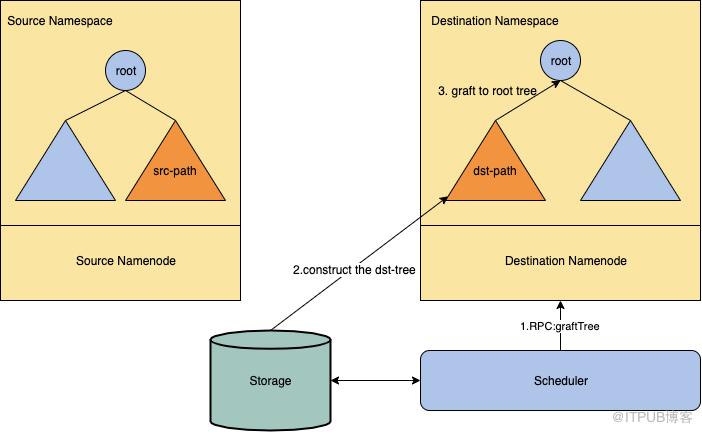
Figure 2: The process of GraftTree. 在graftTree()中涉及到很多NameNode元数据操作,因此必须获取写锁。但整个RPC过程又有很多IO操作,所以不能像其他RPC那样简单地在RPC开始时获取写锁并在RPC结束的时候释放掉。这里我们使用了一个比较巧妙的办法避免拿着写锁做IO,实际上只需要在第2步获取读锁,在第3和5步获取写锁就够了,其余步骤都是无锁的。因为在第3和5步要获取写锁,而在第4步不需要任何锁,所以中间会有一个放弃锁再恢复锁的过程。为此我们引入了一个计数器,在第4步开始的时候,开始一边释放锁一边计数,直到所有锁都被释放掉,然后执行第4步,执行完成后再根据计数器恢复被释放掉的锁。下面解释一下锁设计的正确性:
- 第1步只是读取TREE-META文件,包含IO操作且不需要读写NameNode自身元数据,自然应该是无锁的。
- 第2步需要做合法性检查,涉及到读取NameNode元数据,和所有其他读操作一样,这一步是要拿读锁的。
- 第3步预分配Id,这一步会修改NameNode元数据,因此必须拿写锁。
- 第4步构造目录树,构造过程需要读取TREE-FILE文件,并给新建INode和Block分Id,因为所有Id都在第三步分配好了,所以这一步虽然有IO但不需要拿任何锁。
- 第5步将目录树接到NameNode上,还要添加Id到Map,这都会改变NameNode元数据,必须拿写锁。
现在我们可以解释为什么SaveTree阶段还会保存一个TREE-META文件了。在第二步quota检查时我们需要知道目录树的name和space大小,在第三步Id预分配时我们需要知道INode总数和Block总数,有了TREE-META我们就不必读取整个TREE-FILE来自己计算了,只要在第一步读取TREE-META即可。 现在我们讨论至关重要的错误处理部分。在这里我们的思路是”不要undo”,即GraftTree阶段的5个步骤不论哪一个出错了,都不要做回滚。这是因为回滚操作非常复杂,每一步都可能失败,回滚本身也可能失败。这里我们同样使用了一个比较巧妙的办法,通过引入两阶段edit log解决了这个问题,完全避免了回滚操作,这两个edit log是:
- Pre-allocation edit log,在第3步预分配Id成功时,记录分配了哪些Id。
- Graft-done edit log,在第5步整个RPC成功时,记录graftTree()参数列表和id映射表。
我们将NameNode重放edit log后的状态叫做重放状态,将NameNode记录完edit log那一刻的状态叫做标准状态,只要重放状态与标准状态一致,那么无论发生failover、重启、或是standby节点追日志,NameNode状态都是正确的。下面简单证明一下为什么两阶段edit log可以保证重放状态与标准状态一致。我们用e表示NameNode原有的edit log,用S表示标准状态,用R表示重放状态。NameNode当前每条edit log(不包含Pre-allocation和Graft-done)都满足重放状态等于标准状态:对于任意一个ei和初始状态S,我们都有Si=Ri,其中Si表示S状态保存ei之后的标准状态,Ri表示S状态重放ei之后的重放状态。将上一步稍微推广一下,对于一个序列{e1,…,ei,…,en}和初始状态S,数学归纳法易证对于任意i属于[1,n],Si=Ri。 从两阶段edit log过程我们知道,其实edit log序列只有三种情况(ep表示Pre-allocation edit log,eg表示Graft-done edit log):无ep无eg、有ep无eg和有ep有eg。接下来我们逐个讨论3种情况下标准状态与重放状态一致性:
- 无ep无eg(步骤1,2,3其中一个失败),edit log序列={e1,…,en},属于原始的NameNode edit log序列,显然成立。
- 有ep无eg(步骤4或5失败),edit log序列={e1,…,ei,ep,…,en}。考虑对于任意起始状态S,当从Si->Sp时,NameNode会从可用Id集合中去除预分配Id并将去掉的Id记录到ep,当重放ep时NameNode会将ep记录的Id从可用Id集合中去除掉。对于Si->Sp和Si->Rp两个过程来说,起始可用Id集合相同又去除了相同的Id,因此Sp=Rp,进而对任意x,都有Sx=Rx。
- 有ep有eg(全部步骤成功),edit log序列={e1,…,ei,ep,…,ej,eg,…,en}。在Sj->Sp时,NameNode完成了步骤4和5,并记录graftTree()参数和预分配Id到eg。步骤4和5可以看作有两个输入的函数:f(状态Sj、预分配Id)。当重放ep时NameNode也重做步骤4、5,其中步骤4使用的Id记录在eg中,与Sj->Sp时使用的Id完全相同。可见Sj->Sp和Sj-Rp时两者输入均相同,因此Sg=Rg。结合上一步证明可知对e1~eg均有Si=Ri,进而对任意x有Sx=Rx。
在graftTree() RPC过程中,NameNode的状态改变涉及到Id生成器、根目录树和Id映射表三部分。其中”Id被添加到Id映射表”和”dst-path目录树被添加到根目录树”同时发生,所以可以用根目录树的添加来表示Id映射表添加。下图展示了三种情况下NameNode状态与对应的edit log状态:
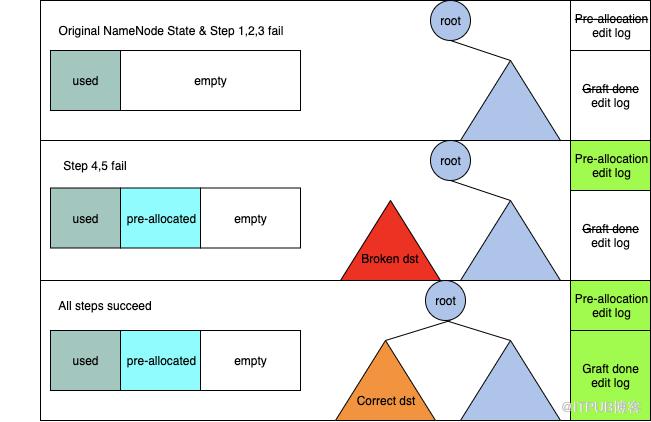
Figure 3: The NameNode states and the edit log. 下面讨论一些实践中的细节。首先讨论步骤4,我们知道步骤4是无锁的,这意味着它不可以改变NameNode的元数据。步骤4构造的dst-path目录树不能被接到根目录树上,而是作为整个RPC过程的一个局部变量保存在内存中。一旦RPC失败,这棵树就会被自动回收掉,不需要额外的清理工作。
下面来看一下graftTree() RPC的最后一步,我们先将所有Id添加到block-map和inode-map,然后将dst-path目录树接到根目录树上,最后写下edit log。
这三个操作必须同时完成或同时不做,只有部分完成则NameNode要杀死自己。最后看一下BLOCK-MAP文件,在GraftTree阶段,我们会写一个新文件BLOCK-MAP。它映射了源NameNode的Id到目标NameNode的Id,包括INodeId、BlockId和GenerationStamp。这个文件是在第4步构造目录树时,一边深度遍历一边写成的,我们在下一步做HardLink的时候会用上它。
另外在我们的实践中,Graft-done edit log并没有记录所有预分配的Id,重放这条edit log时我们是通过读BLOCK-MAP来获取预分配信息的。HardLink
HardLink阶段负责将所有副本hard link到新block pool。
一个块可以被pool id、block id和gs(generation stamp)唯一确定,进而一个块的hard link可以看作是一个6元组(src-pool, src-id, src-gs, dst-pool, dst-id, dst-gs)。我们给DataNode添加了一个新RPC接口,批量接收hard link 6元组,完成hard link并IBR(增量块上报,与之相对的是全量块上报)给NameNode。所有成功hard link的块都会返回给Client。 HardLink过程分为两个步骤:
- 收集块位置信息,并生成hard link计划。
- 执行hard link并处理hard link失败的情况。
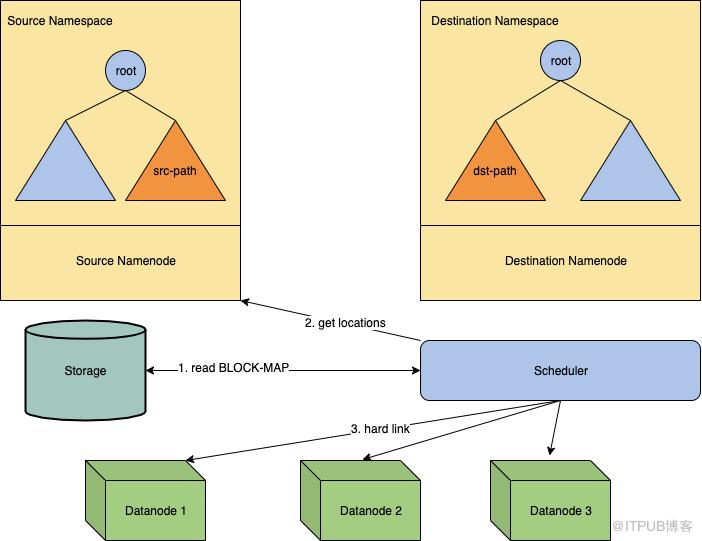
Figure 4: The process of HardLink. 在第1步我们用多线程的方式收集块位置信息。首先我们定义一个pendingQueue用来保存未被处理的路径,之后我们启动多线程来消费这个队列。
当一个线程拿到一个路径的时候,它首先判断路径类别,如果是目录就将它的所有子路径加入到队列中,如果是文件就收集它的块位置信息,并添加到hard link map。这个map的key是DataNode,value是这个DataNode上一系列要做hard link的块。
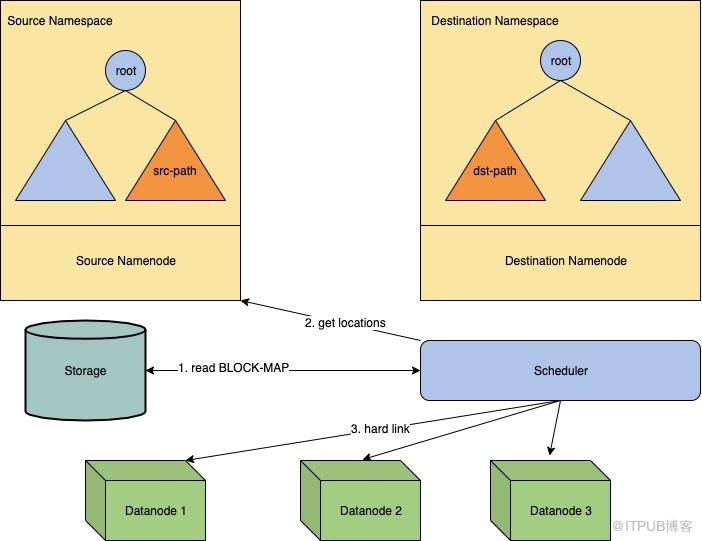
Figure 5: The thread model of collecting locations. 第2步我们使用一个线程池来做hard link,每一个线程负责一个DataNode,分批地将block发给对应DataNode,并收集hard link结果。如果一个块成功hard link的次数满足了最小复制因子,就认为这个块hard link完成。
否则我们需要去目标NameNode检查它的副本数,这是因为NameNode也会做复制,如果块的副本数已经满足了最小复制因子,就不需要再hard link了。如果检查完NameNode块副本数仍旧没有达到最小复制因子,就对这些未达标块重试整个流程。
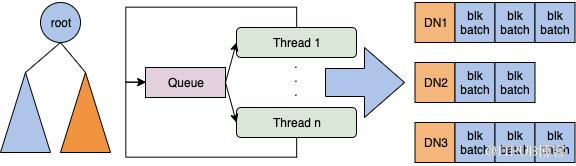
Figure 6: The thread model of hardlink.Scheduler模型 Scheduler模型包括一个作业模型和一个调度器。一个作业是一个状态自动机,可以用如下图来表示。一个作业(Job)包括有限个任务(Task),任务间的有向边表示任务执行流程。
标记为Start的任务是作业的初始任务,标记为None的灰色任务是一个特殊任务,表示作业的结束。Job Context保存了作业的上下文信息,当作业被执行时Job Context会被逐个传递给每个任务,每个任务都可以根据需要来修改它。每一次任务结束时Job Context都会被序列化并保存到外部存储中,用于恢复失败的作业。
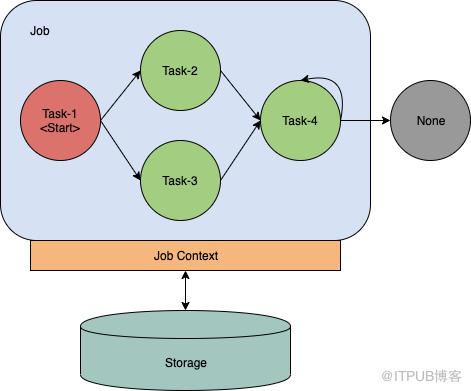
Figure 7: The job model. Scheduler管理了所有作业的生命周期,下图表示了Scheduler的线程模型。每一个作业都有四种状态:Running、Pending、Delay、Recovering。当一个作业被提交给Scheduler后,它就被加入到pendingQueue中,处于pending状态。Worker线程不断地从pendingQueue中获取作业并执行,这时作业就进入running状态。
当作业执行时,它可以通过设置delay time并抛出TaskRetryException的方式来触发重试。Worker捕捉到这个重试异常,就会给它加入到delayQueue中。当delay time时间到,作业会被Rooster线程取出并加回到pendingQueue,作业再次进入pending状态。
如果作业执行过程中有未知异常发生,作业就会被加入到recoverQueue中。Recover线程负责从recoverQueue中获取作业,并根据job context来恢复它。当Scheduler启动的时候,它会自动扫描外部存储来查找所有未完成作业,并将它们加入到recoverQueue中。
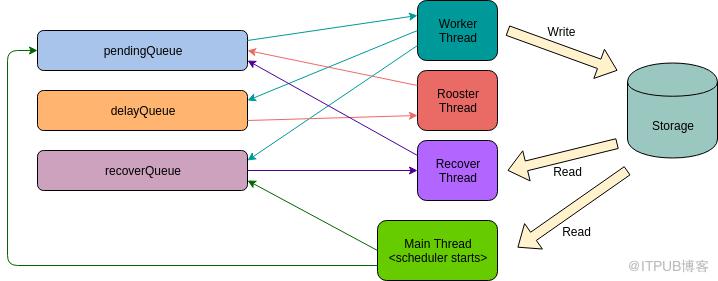
Figure 8: The job scheduler model性能测试环境 测试集群包含2个NameSpace和14个DataNode。服务器配置如下:
- Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz, 12 cores.
- 128GB RAM, 4T x 12 HDD
- Linux 2.6.32, JDK 8
测试方法
- 数据集”set x-y”表示一个深度为x的目录树,树的每个非叶子节点都有y个孩子节点,树的每个叶子节点都是一个文件。
- 文件副本数是3,每个文件只包含一个块。Linux中对256MB文件和1KB文件做HardLink速度是一样的,因此这里做了个优化,使用1KB块文件代表 256MB块。下表中File Size是按照每个文件256MB计算的总文件大小。
测试结果Table 1: The performance results.
| Data sets | Directories | Files | Blocks | Time costs/ms | File Size |
| set 7-7 | 19608 | 117649 | 117649 | 18,001 | 28.72TB |
| set 7-8 | 37449 | 262144 | 262144 | 30,890 | 64TB |
| set 8-9 | 597871 | 4782969 | 4782969 | 577,360 | 1.14PB |
线上环境 线上环境与测试环境有很大不同,主要是为了保证安全,线上环境我们做了更烦琐的校验,这对HFR速度影响很大,会使其耗时更久。线上的校验需要给NameNode发送大量rpc,每个rpc的耗时也随NameNode当时的ops有波动,所以会有大小差不多的目录耗时却不同的情况。
下表展示了部分线上环境迁移案例:Table 2: The online cluster performance.
| Path | Files+Directories | Blocks | Time costs |
|---|---|---|---|
| /user/h_data_platform/platform/isource | 1900000+ | 2523910 | 1166s |
| /user/h_data_platform/platform/b2cdc | 1600000+ | 2461348 | 875s |
| /user/h_data_platform/platform/fintech | 1400000+ | 1830326 | 697s |
总结 HFR实现了跨NameSpace的rename。它的速度很快,可以在秒级完成TB数据的rename。HDFS RPC的默认超时是60秒,所以小目录上的HFR不会引起用户端RPC超时。HFR在处理跨NameSpace均衡的时候也非常灵活高效,我们经常遇到这样的问题:有的用户希望迁移整体尽量快,为此可以接受一段时间的服务不可用;有的则不能接受,他们希望大路径被拆成很多小路径一点一点迁移过去,整体时间可以较长,但每一部分的迁移时间要非常短。
Scheduler模型是灵活可插拔的,允许我们组合出不同的HFR作业类型来满足不同需求。HFR的缺点是作业执行期间会禁写,无法在所有情况下都对用户透明。 截止到文章撰写时(2020年1月中旬),HFR在小米最大离线生产集群已经工作了2个多月。我们用它来拯救不堪重负的NameNode,超过3100万文件被移动到了空闲的NameSpace,为压力最大的NameNode释放了10GB内存。 后续我们对HFR的计划是:
- 将HFR整合到Router服务中,允许小目录跨NameSpace rename。
- HFR支持Hadoop3.1 EC(Erasure Code)编码文件。
- 通过自动分析用量和接入历史,结合管理员设定的阈值,实现更智能的负载均衡。
小米HDFS团队有很棒的开源氛围,一直非常积极地参与开源社区,贡献了大量Patch。我们也在努力将HFR贡献给社区,
相关Jira:https://issues.apache.org/jira/browse/HDFS-15087。