
我们都经历过这种情况:你打开ChatGPT,输入一个指令,比如“从这张表格中提取所有电子邮件,并根据情感对其进行分类”。它会给 you 一个初步的结果。你进行修改后,它会道歉并给出新的结果。如果你要求不同的输出格式,它却会完全忘记之前的上下文,迫使你重新开始。
对于一些简单的任务来说,这样的错误可能还不算什么,但对于生产环境中的系统而言,这简直就是一场灾难。“在我的ChatGPT测试中这个方法可行”,而“在真实的生产环境中这个系统能稳定运行”之间,存在着巨大的差距。这种差距并不能通过编写更完善的指令来弥补,而是需要依靠工程技术来解决。
这篇文章正是围绕这些工程技术展开的。你将了解到那些能够将AI实验转化为实际产品的架构模式、故障类型以及实现策略。
你将学到什么
通过本教程,你将学会如何:
-
理解为什么AI系统的失败方式与传统软件不同
-
识别并预防生产环境中AI系统出现的三种关键故障类型
-
使用“验证器三明治模式”来确保输出结果的一致性
-
构建具备完善监控和警报功能的可观测数据处理流程
-
通过限流机制和控制策略来有效管理大规模应用中的成本开销
-
设计一套完整、适用于生产环境的人工智能架构
先决条件
为了最大限度地利用本教程的内容,你应当具备以下条件:
-
对任何一种编程语言都有一定的基础了解
-
熟悉REST API及异步编程技术
-
至少拥有一个大型语言模型API的使用经验(如OpenAI、Anthropic等)
-
在本地安装了Node.js环境(可选,用于运行代码示例)
你并不需要在这些领域成为专家,具备中级水平的知识就足够了。
目录
人工智能系统的本质区别是什么
传统软件是确定性程序。当你编写代码`if (urgency > 8) { return ‘high’ }`时,每次运行它都会给出完全相同的输出结果。同样的输入,永远得到同样的结果。你可以为这些代码编写单元测试来覆盖所有可能的执行路径,也可以预测出可能出现的各种故障情况。
另一方面,人工智能系统属于概率性系统。当你要求一个大型语言模型对某件事情的紧急程度进行分类时,它有时会给出“高”的判断,有时会写“紧急”,有时会给出1到10的分数,还有时候会写一段文字来解释它的判断依据。同样的输入,由于温度设置、模型版本、上下文范围等因素的不同,系统会给出不同的输出结果,而这些因素你并不能完全控制。
以下是这种情况在实践中的表现:
| 挑战 | 传统系统 | 人工智能系统 |
|---|---|---|
| 一致性 | 100%可复现 | 每次请求的结果都可能不同 |
| 调试 | 通过堆栈跟踪和日志进行调试 | “模型只是改变了它的行为而已” |
| 测试 | 单元测试能覆盖所有可能的执行路径 | 无法测试所有可能的结果 |
| 部署 | 部署一次后就可以永久使用 | 随着时间推移,系统性能会下降 |
| 故障模式 | 可预测且种类有限 | 具有创造性,故障模式无穷多样 |
工程上的挑战在于:如何在这种固有的不可预测性基础上建立起系统的可靠性?
答案并不是“使用更好的模型”。模型或许只解决了20%的问题,剩下的80%则取决于你围绕这个模型构建的整个系统。
故障模式#1:输出结果不一致
问题所在
当你要求人工智能从支持工单中提取客户的电子邮件地址时,有时会得到正确的邮件地址,有时只能得到名字,有时则会得到电话号码。每次的输出格式都不一样。同样的输入,却会导致不同的结果。
指令:“从这条支持工单中提取客户的电子邮件地址”
周一的输出结果: "john@example.com"
周二的输出结果: "客户电子邮件地址:john@example.com (已验证)"
周三的输出结果: "John Doe"
周四的输出结果: {
"customer_info": {
"email": "john@example.com"
}
}
这三种输出结果都包含了正确的信息,但因为你无法对它们进行程序化的处理,所以你就无法根据这些结果来路由工单、触发工作流程系统,或者将其与其他代码集成起来。
解决方案:验证器夹层模式
验证器夹层模式(也被称为防护栏模式)通过在人工智能系统与最终输出结果之间添加两层确定性代码,确保系统不会生成或处理错误的数据。
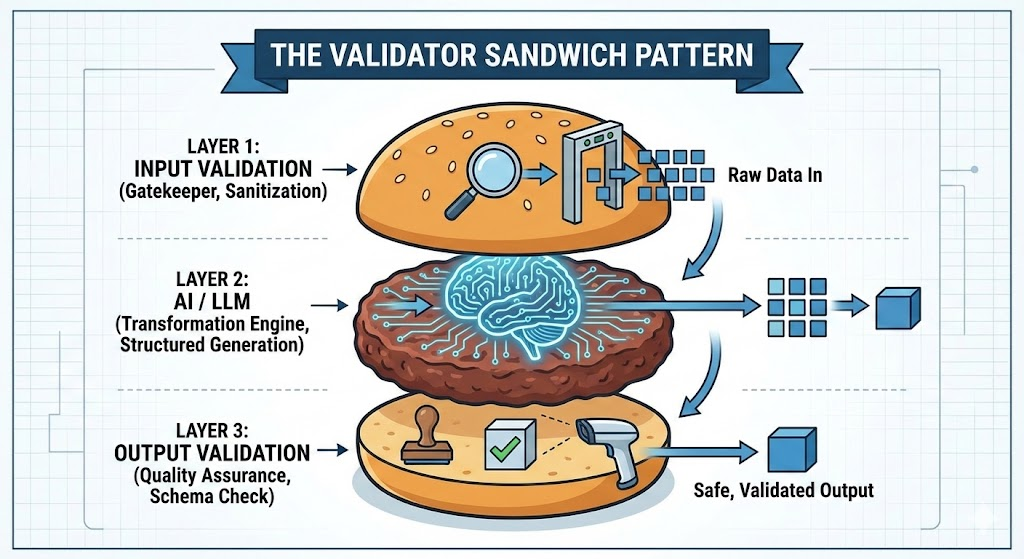
本质上,这个系统由三层结构组成:
-
最外层“外壳”:
输入数据校验机制(确定性的处理方式)
-
核心部分:
大语言模型生成的输出结果(概率性的处理方式)
-
最内层“外壳”:
输出数据的再次校验机制(确定性的处理方式)
让我们来详细分析每一层的作用。
最外层“外壳”:输入数据校验机制
在任何数据进入人工智能系统之前,都必须先进行校验。立即剔除无效数据,快速且低成本地处理错误。以下是一个使用确定性代码来检查接收到的数据的简单示例:
function validateTicketInput(raw): TicketInput {
// 类型检查
if (!raw.email || typeof raw.email !== "string") {
throw new ValidationError("电子邮件地址缺失或格式无效");
}
// 格式检查
if (!isValidEmail(raw.email)) {
throw new ValidationError(`电子邮件格式不正确:${raw.email}`);
}
// 内容长度检查
if (!raw.body || raw.body.length < 10) {
throw newValidationError("工单内容太短,无法进行分类");
}
if (raw.body.length > 10000) {
throw new ValidationError("工单内容超过最大长度限制");
}
// 返回经过验证的输入数据
return {
email: raw.email.toLowerCase().trim(),
subject: raw.subject?.trim() || "无主题",
body: raw.body.trim(),
timestamp: new Date(raw.timestamp),
};
}
这个校验过程会在调用大语言模型之前立即执行。它运行速度快、成本低,且能够及时发现常见的错误。
核心部分:大语言模型生成的结构化输出结果
不要再要求人工智能系统生成自由文本了,应该将其输出结果强制纳入特定的结构框架中。大多数现代API都直接支持这种处理方式。
那么,“自由文本”到底意味着什么呢?当不对人工智能系统提出任何限制时,它就会返回未经结构化处理的自然语言文本。格式由模型自行决定——有时是一句话,有时是一段文字,甚至还会添加一些用户并未请求的额外信息。这样一来,想要通过程序进行解析就几乎变得不可能了。
而如果将输出结果强制纳入特定的结构框架中,那就等于明确告诉模型:“请只返回符合这种结构的JSON格式数据”。现代的大语言模型API都具备这样的功能。这样,你就无法让人工智能系统生成其他格式的响应了。
以下是实际应用中的区别:
不采用结构化框架处理(自由文本方式):
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "user",
content: "将这条支持工单分类为故障问题、账单问题还是功能请求:" + ticketText
}
]
});
// 可能的返回结果:
// "这似乎是一个账单问题"
// "账单问题"
// "类别:账单问题(置信度:很高)"
// { "type": "billing" } // 如果运气好的话,可能会得到这样的结果
采用结构化框架处理:
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "user",
content: "请对这张支持工单进行分类:" + ticketText
}
],
response_format: {
type: "json_schema",
jsonSchema: {
name: "ticket_classification",
strict: true,
schema: {
type: "object",
properties: {
category: {
type: "string",
enum: ["bug", "billing", "feature", "other"]
},
confidence: {
type: "number",
minimum: 0,
maximum: 1
},
priority: {
type: "integer",
minimum: 1,
maximum: 5
}
},
required: ["category", "confidence", "priority"],
additionalProperties: false
}
}
}
});
// 返回的结果必定是如下格式:
// { "category": "billing", "confidence": 0.89, "priority": 2 }
response_format参数强制模型输出符合您所定义结构的有效JSON数据。如果模型无法满足这一要求,API会内部重试,直到成功生成符合格式的数据。这样一来,每次您都能获得可预测、可解析的数据。
关键在于:您是在迫使人工智能遵循您的格式要求,而不是寄希望于它能自动做出正确的处理。
输出数据的约束机制
这一层是最为关键的。大型语言模型有时会产生错误的结果,而这一层的作用就是在这些错误结果破坏数据库或误导用户之前将其拦截下来。
这些约束机制其实就是验证流程,在大型语言模型作出响应之后执行。可以把它们想象成高速公路上的安全护栏:它们不能阻止车辆前进,但可以防止车辆驶出道路。
-
输出数据是否符合预期的结构
-
数据类型是否正确
-
数值是否位于可接受的范围内
-
业务逻辑是否合理
现在,您已经得到了结构化的数据输出。但在使用这些数据之前,还需要进行严格的验证:
function validateClassification(raw): Classification {
const required = ["category", "confidence", "priority", "reasoning"];
for (const field of required) {
if (raw[field] === undefined || raw[field] === null) {
throw new ValidationError(`缺少必需字段:${field}`);
}
}
if (!["bug", "billing", "feature", "other"].includes(raw.category)) {
throw newValidationError(`类别无效:${raw.category}`);
}
if (typeof raw.confidence !== "number" ||
raw.confidence < 0 || raw.confidence > 1) {
throw new ValidationError(`置信度值无效:${raw.confidence}`);
}
if (!Number.isInteger(raw.priority) ||
rawpriority < 1 || raw_priority > 5) {
throw newValidationError(`优先级值无效:${raw.priority}`);
}
if (raw.category === "billing" && raw.priority > 3) {
logger.warn("可疑情况:账单被归类为低优先级", raw);
}
return raw as Classification;
}
进行严格验证意味着要检查所有方面,而不仅仅是数据是否符合结构要求。您需要验证的内容包括:
-
结构合规性:JSON数据中是否包含所需的字段?
-
类型正确性:“confidence”这个字段的值确实是数字吗,而不是字符串?
-
数值范围合法性:置信度值应该在0到1之间,而不是-5或999吗?
-
业务逻辑合理性:这些字段的组合在您的应用场景中是否合理?
-
置信度阈值:人工智能对这个答案的信心程度是否足够高?
如果任何验证环节失败,您不能默默接受错误的数据。此时您有三种选择:
-
重新请求并提供更明确的指示:要求模型根据更详细的指令再次尝试生成数据。
-
交由人工审核:记录失败情况,并将相关数据放入审核队列中等待人工处理。
-
使用默认值:返回一个需要人工处理的默认值作为替代结果。
确定性规则
这里有一条必须严格遵守的规则:
如果某个问题可以用“if语句”来解决,那就不要使用人工智能。
验证电子邮件格式?使用正则表达式。解析日期?使用专门的日期处理库。检查字符串中是否包含特定关键词?使用字符串处理方法。进行数学计算?直接用传统的数学方法即可。
人工智能成本高昂,且其决策过程属于概率性判断;而传统代码则是免费、即时且结果具有确定性的。因此,只有在那些真正存在模糊性的任务中,才应该使用人工智能——比如从非结构化文本中提取信息、生成内容,或者对复杂的输入数据进行推理分析。其余的所有工作,都应该由确定性强的代码来处理。
故障模式#2:隐性故障
问题所在
在人工智能应用中,模型出现“幻觉”现象的情况相当普遍,这些问题的表现形式包括准确性下降、训练数据过时,或是分类结果错误等等。这种故障模式最为可怕,因为人们根本意识不到它的存在。
以准确性漂移为例:你使用2024年的数据训练了模型,但现在已经是2026年中期了,你的供应商改变了发票格式,导致模型的分类准确率从95%降到了71%。直到你进行季度审计时才会发现这个问题,而到那时,已经有成千上万的记录被错误地处理掉了。
道理很简单:你看不见的问题,就无法解决。
解决方案:可观测的流程体系
任何正式投入生产的人工智能系统,从一开始就必须具备可观测性。在实际的生产环境中,这一机制的具体运作方式如下:
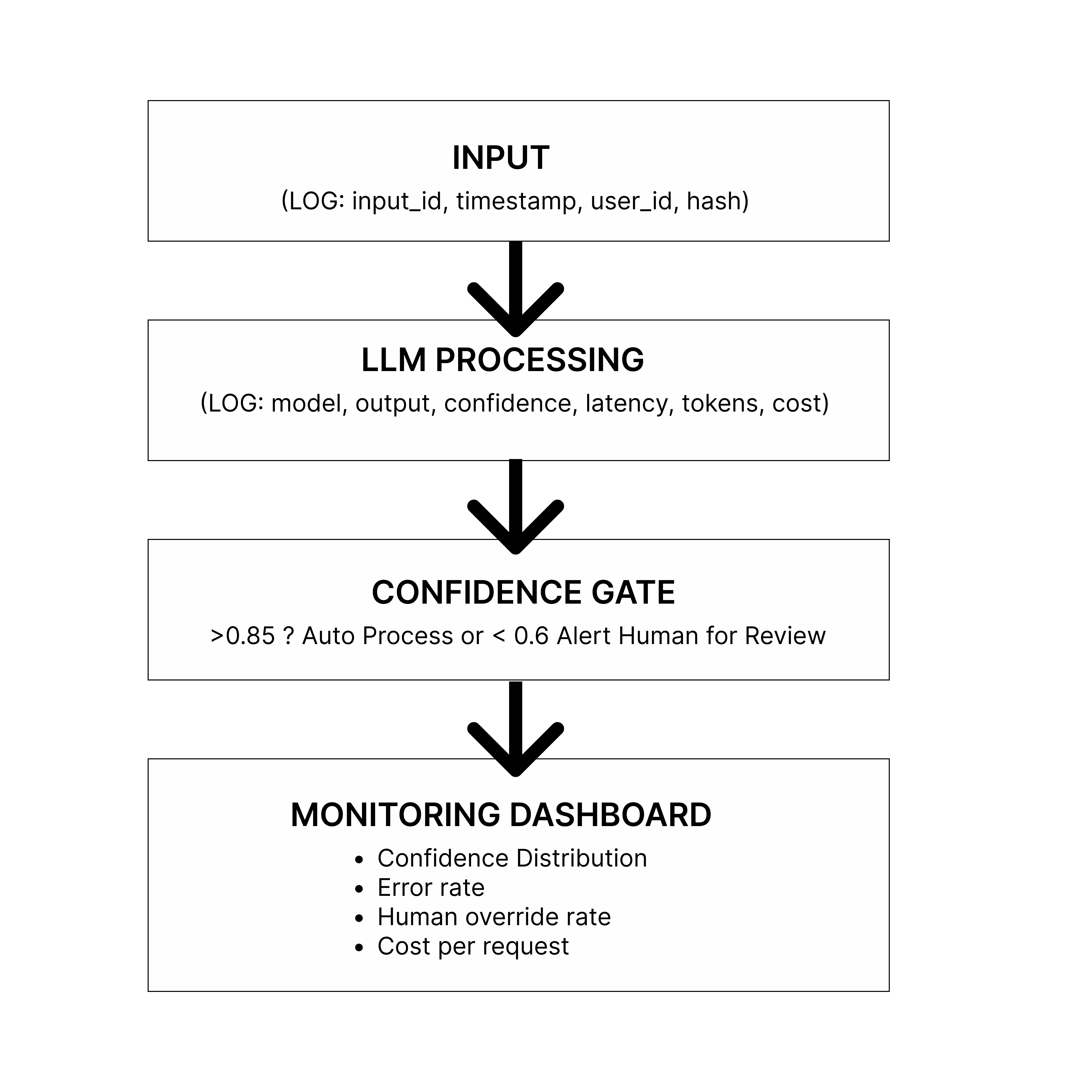
在上述流程图中:
-
输入数据到达:用户提出请求(无论是支持工单、文档还是查询信息),你会记录下请求ID、时间戳、用户ID以及输入数据的哈希值(用于去重处理)。
-
大语言模型处理:请求会被传递给相应的人工智能模型。你需要记录下使用了哪个模型、处理耗时多少、消耗了多少计算资源,以及最重要的——模型的置信度评分。
-
置信度判断环节:在这里你会决定如何处理该请求:
-
置信度很高(>0.8):自动执行相应操作。
-
置信度中等(0.6–0.8):将请求发送到人工审核队列中。
-
置信度很低(<0.6):立即上报问题并发出警报。
-
-
监控面板:所有这些数据都会被传输到监控系统中,你可以通过这些数据来追踪系统运行中的各种趋势变化。
通过实施有效的监控机制,你可以及时发现系统中的问题并加以解决。监控不仅能帮助你发现问题,还能为你提供诊断和修复问题的所需数据,从而让你在短短几小时内就能解决问题,而无需花费数月时间。
您正在测量什么以及为何要测量这些内容:
| 指标 | 其重要性 |
|---|---|
| 响应时间 | API运行状态、模型存在的问题 |
| 置信度 | 模型性能下降情况 |
| 人工干预率 | 输出结果的质量问题 |
| 错误率 | 系统故障情况 |
| 每次请求的成本 | 预算控制 |
| 令牌使用趋势 | 提示系统的效率 |
我们的目标并不是让人类完全脱离这个流程,而是只有在系统确实无法做出准确判断时,才让人类介入。
故障模式#3:成本失控
问题所在
您用10个请求来测试您的开发流程,结果一切正常,且仅花费了50美分。但当您将这个系统部署到生产环境中后,如果有1,000个请求同时访问您的API,那么当天的费用就会达到500美元。
或者,如果您错误地编写了重试逻辑,导致系统会无限次地调用API,那么当天的费用可能会高达5,000美元。
又或者,您在所有情况下都使用最昂贵的模型,甚至包括那些可以用更便宜的模型来处理的简单任务,这样也会造成不必要的成本浪费。
事实就是:“适用于10个请求”的系统,并不等于“适用于10,000个请求”的系统。”规模的变化会带来巨大的影响。
解决方案:带有断路器的门控流程
要想将一个脆弱的原型开发成稳定的生产系统,就必须摒弃那种直接将用户输入连接到大型语言模型API的简单做法。相反,应该采用门控流程这种设计。
可以把这种架构想象成一排道闸。只有当请求成功通过每一道关卡后,才能继续产生费用。如果有任何一道关卡关闭,请求就会立即被拒绝,从而保护您的预算以及上游系统不受影响。
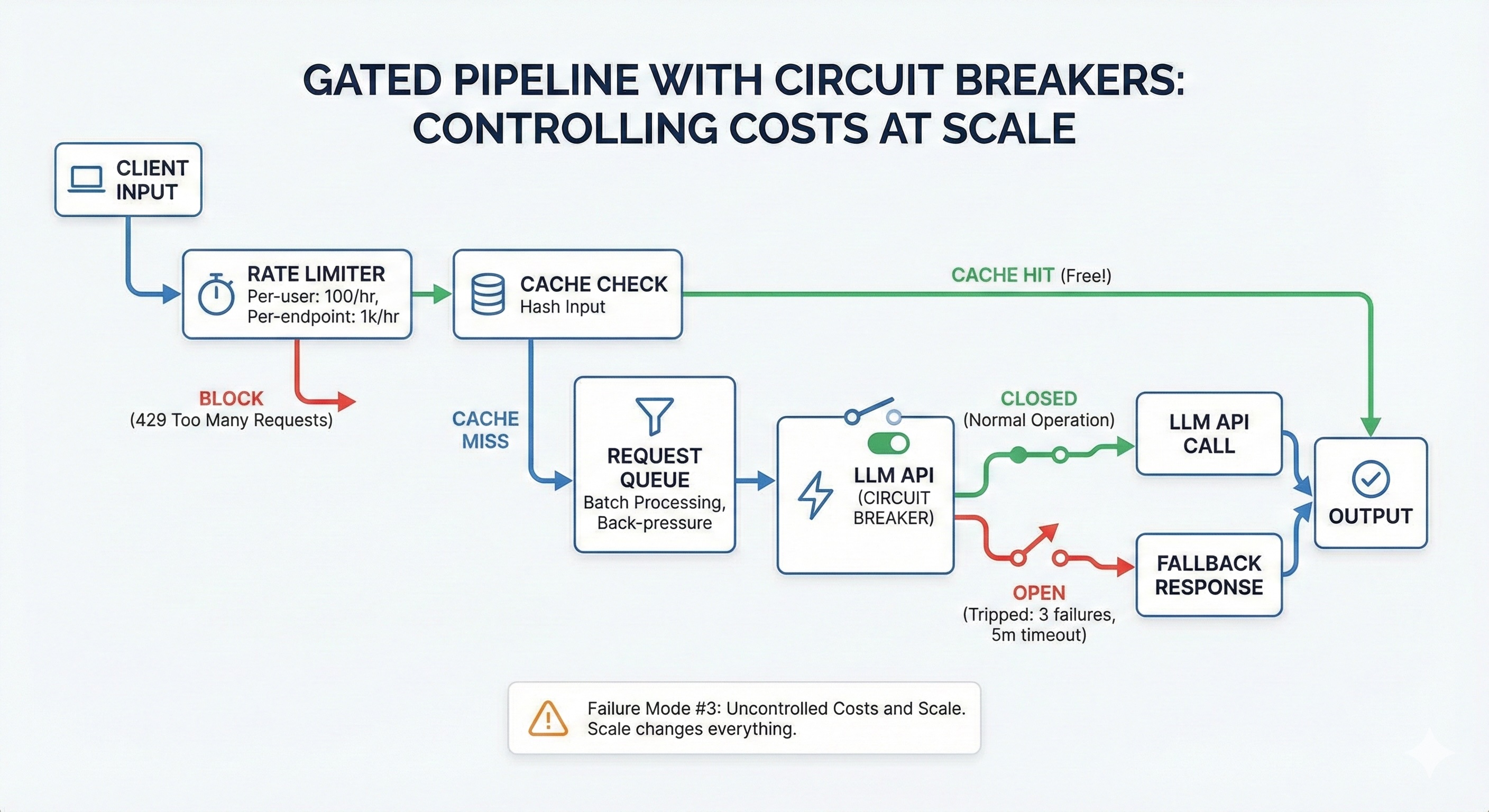
从上面的图示中可以看出,这些关卡包括:
-
速率限制机制
-
缓存检查功能
-
请求队列系统
-
断路器装置
让我们来逐一了解这些关卡的作用。
关卡1:速率限制
第一道防线的作用是在恶意请求进入系统之前就将其阻止。在标准的网络开发中,速率限制主要是为了保护服务器的CPU资源;而在人工智能开发中,它的作用则是保护您的预算不受损失。
关卡2:缓存检查
最节省成本的AI API调用,就是那些根本不需要被执行的请求。许多AI请求其实是重复性的,或者内容非常相似。因此,应该积极利用缓存机制来减少不必要的计算开销。
关卡3:请求队列
请求队列的作用是确保请求能够按照合理的顺序被处理。通过设置队列长度和优先级,可以避免系统因为过多的并发请求而陷入混乱。
大语言模型API与标准的REST API不同,请求的处理通常需要10到30秒才能完成。如果同时有500名用户点击“提交”按钮,服务器将无法同时建立500个连接,否则就会崩溃或超出服务提供商规定的并发限制。通过使用请求队列,可以批量处理这些请求,并以受控的速度逐一执行它们,从而解决这个问题。
第四道屏障:断路器
对于短暂的网络故障来说,重试机制是必要的;但在发生真正的服务中断时,这种机制反而会造成更大的破坏。如果某个大语言模型服务提供商出现了故障,并返回了500个错误信息,那么一个简单的重试循环就会不断反复地向他们的API发送请求,从而导致资源浪费。
如何实现带屏障的请求处理流程
下面是一个示例,展示了这四道屏障是如何协同工作的:
步骤1:速率限制器(使用Redis实现)
import { RateLimiterRedis } from "rate-limiter-flexible";
import Redis from "ioredis";
const redis = new Redis({
host: process.env.REDIS_HOST,
port: 6379
});
// 为每个用户设置速率限制
const userLimiter = new RateLimiterRedis({
storeClient: redis,
keyPrefix: "rl:user",
points: 100,
duration: 3600,
blockDuration: 60
});
// 全局范围设置速率限制
const globalLimiter = new RateLimiterRedis({
storeClient: redis,
keyPrefix: "rl:global",
points: 1000,
duration: 3600
});
步骤2:缓存层
import { createHash } from "crypto";
class AICache {
private redis: Redis;
private ttl: number = 3600;
hashInput(input: string): string {
return createHash("sha256").update(input).digest("hex");
}
async get(input: string): Promise {
const key = `ai:cache:${this.hashInput(input)}`;
const cached = await this.redis.get(key);
if (cached) {
// 缓存命中,直接返回结果!
await metrics.increment("ai.cachehits");
return JSON.parse(cached);
}
await metrics.increment("ai.cache.misses");
return null;
}
async set(input: string, result: T): Promise {
const key = `ai:cache:${this.hashInput(input)}`;
await this.redis.setex(key, this.ttl, JSON.stringify(result));
}
}
步骤3:请求队列
import Queue from "bull";
const aiQueue = new Queue("ai-requests", {
redis: {
host: process.env.REDIS_HOST,
port: 6379
}
});
aiQueue.process(5, async (job) => {
// 同时最多只能有5个请求在处理中
const { ticket } = job.data;
return await callLLM(ticket);
});
async function enqueueRequest.ticket: Ticket) {
const job = await aiQueue.add(
{ ticket },
{
attempts: 3,
backoff: {
type: "exponential",
delay: 2000
}
}
);
return job_finished();
}
步骤4:断路器
enum CircuitState {
CLOSED,
OPEN,
HALF_OPEN
}
class CircuitBreaker {
private state = CircuitState.CLOSED;
private failures = 0;
private lastFailureTime?: Date;
private successesInHalfOpen = 0;
private readonly failureThreshold = 3;
private readonly openDurationMs = 5 * 60 * 1000;
private readonly halfOpenSuccesses = 2;
async execute(
fn: () => Promise,
fallback?: () => T
): Promise {
if (this.state === CircuitState.OPEN) {
const elapsed = Date.now() - (this.lastFailureTime?.getTime() || 0);
if (elapsed < this.openDurationMs) {
// 仍处于开启状态——使用回退处理方式或抛出异常
if (fallback) {
logger.warn("电路处于开启状态——使用回退处理方式");
return fallback();
}
throw new Error("电路断路器处于开启状态——服务不可用");
}
// 将状态切换为半开状态
this.state = CircuitState.HALF_OPEN;
logger.info("电路正在切换到半开状态");
}
try {
const result = await fn();
this.onSuccess();
return result;
} catch (error) {
this.onFailure();
throw error;
}
}
private onSuccess() {
if (this.state === CircuitState.HALF_OPEN) {
this.successesInHalfOpen++;
if (this.successesInHalfOpen >= this.halfOpenSuccesses) {
// 服务已恢复——关闭电路
this.state = CircuitState.CLOSED;
this.failures = 0;
this.successesInHalfOpen = 0;
logger.info("电路已关闭——服务已恢复");
}
} else {
this FAILures = 0;
}
}
private onFailure() {
thisfails++;
this.lastFailureTime = new Date();
if (this.state === CircuitState.HALF_OPEN) {
// 在测试过程中出现故障——将电路状态切换回开启状态
this.state = CircuitState OPEN;
this.successesInHalfOpen = 0;
logger.error("在半开状态测试期间电路被重新打开");
} else if (thisfails >= this.failureThreshold) {
// 故障次数过多——将电路状态切换为开启状态
this.state = CircuitState.OPEN;
logger.error(`在发生${this.failures}次故障后,电路被重新打开`);
}
}
}
步骤5:将所有环节整合在一起
const cache = new AICache();
const circuitBreaker = new CircuitBreaker();
async function processWithGatedPipeline(ticket: Ticket) {
try {
await userLimiterconsume(ticket.userId);
await globalLimiterconsume("global");
} catch (error) {
throw new Error("达到了速率限制。请稍后再试。”);
}
const cacheKey = ticket.body;
const cached = await cache.get(cacheKey);
if (cached) {
logger.info("从缓存中找到了结果,直接返回缓存值.");
return cached;
}
const queuedResult = await enqueueRequest(ticket);
const result = await circuitBreaker.execute(
async () => {
const classification = await callLLMticket);
await cache.set(cacheKey, classification);
return classification;
},
() => ({
category: "other",
confidence: 0,
requiresHumanReview: true,
reason: "service_unavailable"
})
);
return result;
}
这种方式能够实现以下目标:
-
速率限制:防止滥用系统资源导致成本失控。
-
缓存机制
: 对重复请求进行缓存处理,从而将成本降低30%至40%。
-
队列管理
: 在流量激增时避免服务器过载。
-
断路器机制
: 在系统出现故障时能够迅速停止相关操作,从而避免不必要的重复尝试和资源浪费。
每一个“关卡”都是成本较低的解决方案,而当它们共同发挥作用时,就能有效保护你的系统免受最常见的生产环境故障的影响。
如何构建完整的生产环境架构
当你将这三种故障处理机制——结果一致性、可观测性以及成本控制——结合起来时,你就构建出了一个完整的生产环境架构。
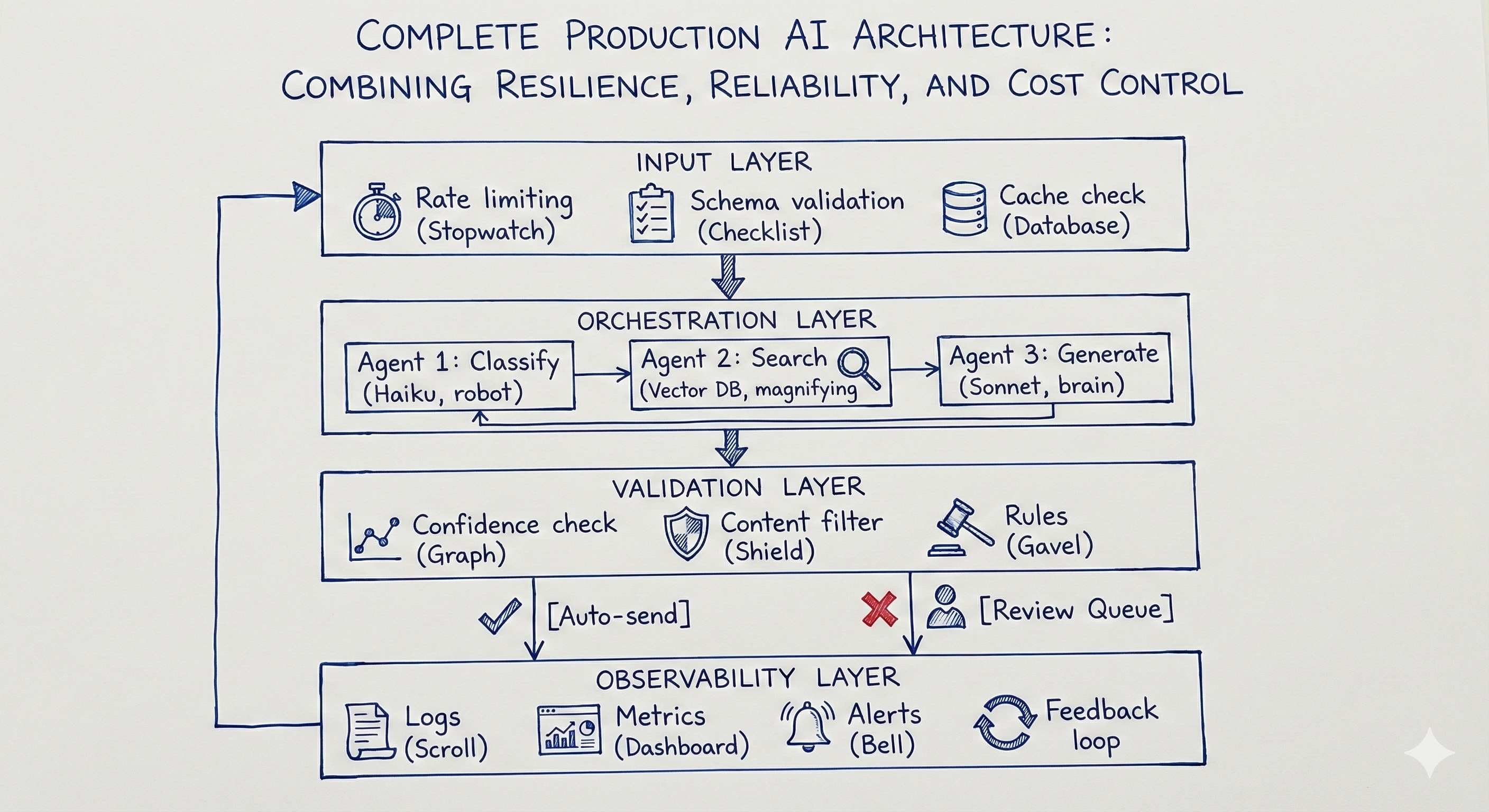
当你成功解决了三种主要的故障问题——结果不一致、故障发生时没有警报以及成本失控——你就从一个简单的脚本系统升级成了一个真正的企业级系统。这种架构不仅能生成文本,还能主动保护自身、管理资源,并从错误中吸取经验。
完整的工作流程实现
以下是我们所讨论的所有环节是如何在一个完整的工作流程中协同运作的。这个流程结合了第一种故障处理机制中的输入验证功能、第二种机制中的可观测性功能,以及第三种机制中的缓存和队列管理机制:
class TicketWorkflow {
async processTicket(rawInput: unknown): Promise {
const requestId = generateId();
const startTime = Date.now();
try {
// 第一层:输入验证 + 速率限制 + 缓存
const ticket = validateTicketInput(rawInput);
await rateLimiterconsume(ticket.userId);
const cached = await cache.get(ticket.body);
if (cached) return { ...cached, source: "cache" };
// 第二层:使用断路器进行AI处理
const classification = await circuitBreaker.execute(() =>
classifyTicket(ticket)
);
// 第三层:输出验证 + 根据置信度分配处理方式
const validated = validateClassification(classification);
let action: string;
if (validated.confidence >= 0.8) {
await sendToAgentticket, validated);
action = "auto_assigned";
} else {
await sendToReviewQueue(ticket, validated);
action = "needs_review";
}
// 第四层:记录所有操作以便进行可观测性分析
await logger.log({
requestId,
userId: ticket.userId,
confidence: validated.confidence,
action,
latencyMs: Date.now() - startTime,
cost: calculateCost(classification.tokensUsed)
});
await cache.set(ticket.body, validated);
return { classification: validated, action };
} catch (error) {
await logger.logError(requestId, error);
throw error;
}
}
}
每一层的作用如下:
第1层(输入层)用于保护系统免受不良数据及滥用行为的影响:
-
验证工单是否包含所需的字段(电子邮件地址、主题内容、正文等)。
-
检查访问频率限制,防止某个用户过度占用系统资源。
-
如果之前已经处理过相同的工单,就会直接返回缓存结果。
第2层(协调层)是人工智能发挥作用的地方:
-
以结构化的方式调用大型语言模型,并要求其生成相应的输出结果。
-
该流程配备了“断路器”机制,当API出现故障时能迅速停止相关操作。
-
会选用成本最低但依然有效的模型来进行处理(例如用于分类任务的Haiku模型)。
第3层(验证层)确保输出结果的安全性:
-
验证响应内容是否符合预定的数据结构规范。
-
根据结果的可靠性进行分类处理:高可靠性的结果会自动被分配处理,低可靠性的结果则需要人工审核。
-
绝不会盲目信任人工智能生成的输出结果。
第4层(监控层)负责全面跟踪系统运行情况:
-
记录每一条请求的延迟时间、处理成本以及可靠性评分等信息。
-
将相关数据发送到监控仪表板中。
-
一旦发现异常情况(如可靠性下降或成本激增),会立即发出警报。
这种架构使系统从“在ChatGPT演示中能够正常运行”转变为“每天能处理10,000份工单而依然稳定运行”。虽然相关代码的复杂度远高于简单的API调用,但这种复杂性正是系统能够投入实际生产使用的关键所在。
结论:架构设计的重要性超过提示机制本身
目前那些在人工智能领域取得成功的企业,并非因为它们拥有更先进的模型,而是因为它们围绕这些并不完美的模型构建了更加完善的系统。
任何公司都可以使用OpenAI的API,但真正能够脱颖而出的企业,是那些将API调用与数据验证、系统监控、成本控制以及合理的架构设计相结合的企业——它们把人工智能视为生产流程中的一个组成部分,而不是对话过程中的创意伙伴。
每一个实际应用中的人工智能系统都需要以下三个要素:
- 结构框架:包括验证机制、数据规范以及能够确保一致性并消除异常情况的处理流程。
- 可监控性:通过日志记录、实时监控和警报功能,让问题在几小时内就被发现,而不会拖上数月才被察觉。同时,系统的工作流程也应当清晰透明,以便人们能够清楚地了解系统的运行情况及其原因。
- 控制机制:包括访问频率限制、缓存策略、“断路器”机制以及成本管控措施,这些措施能确保系统规模的扩大不会导致运营危机。
可靠的人工智能工作流程,并不依赖于更优秀的提示机制,而是取决于如何利用那些存在缺陷的组件来构建更加完善的系统架构。
如果您觉得这篇文章有帮助,可以通过LinkedIn与我联系,或者订阅我的时事通讯。您也可以访问我的个人网站了解更多信息。