
对数据科学项目的需求正在实现业务突破。许多从业者认为数据科学正在有效地服务于他们的业务。但是,许多数据科学项目在向客户提供服务时由于工作流不当而失败。事实是,在业务环境中在数据科学方面取得成功是一个复杂的挑战。
曾经对数据科学项目或业务有这个好主意吗?最后,你没有,因为你不知道如何使它成功?
在本文中,我们将简要说明如何管理数据科学项目以成功交付。
什么是数据科学项目?
在继续之前,有必要了解什么是数据科学项目。很少有公司了解数据科学和分析项目之间的区别。分析项目要求利益相关者在释放价值之前做出决策。数据科学项目创建数字产品,通过全自动的微观决策提供价值。
数据科学项目使用由数据支持的逻辑驱动或统计分析过程。任何数据科学项目的最终结果都是利益相关者可以根据该建议或结论做出有效的业务决策。
什么是数据科学问题?
数据科学家在进行数据科学项目时面临一些问题,其中一些如下所述:
- 分类或分组数据
- 识别模式
- 识别异常
- 显示相关性
- 预测结果
如何解决数据科学问题
数据科学中的问题陈述可以通过以下步骤解决:
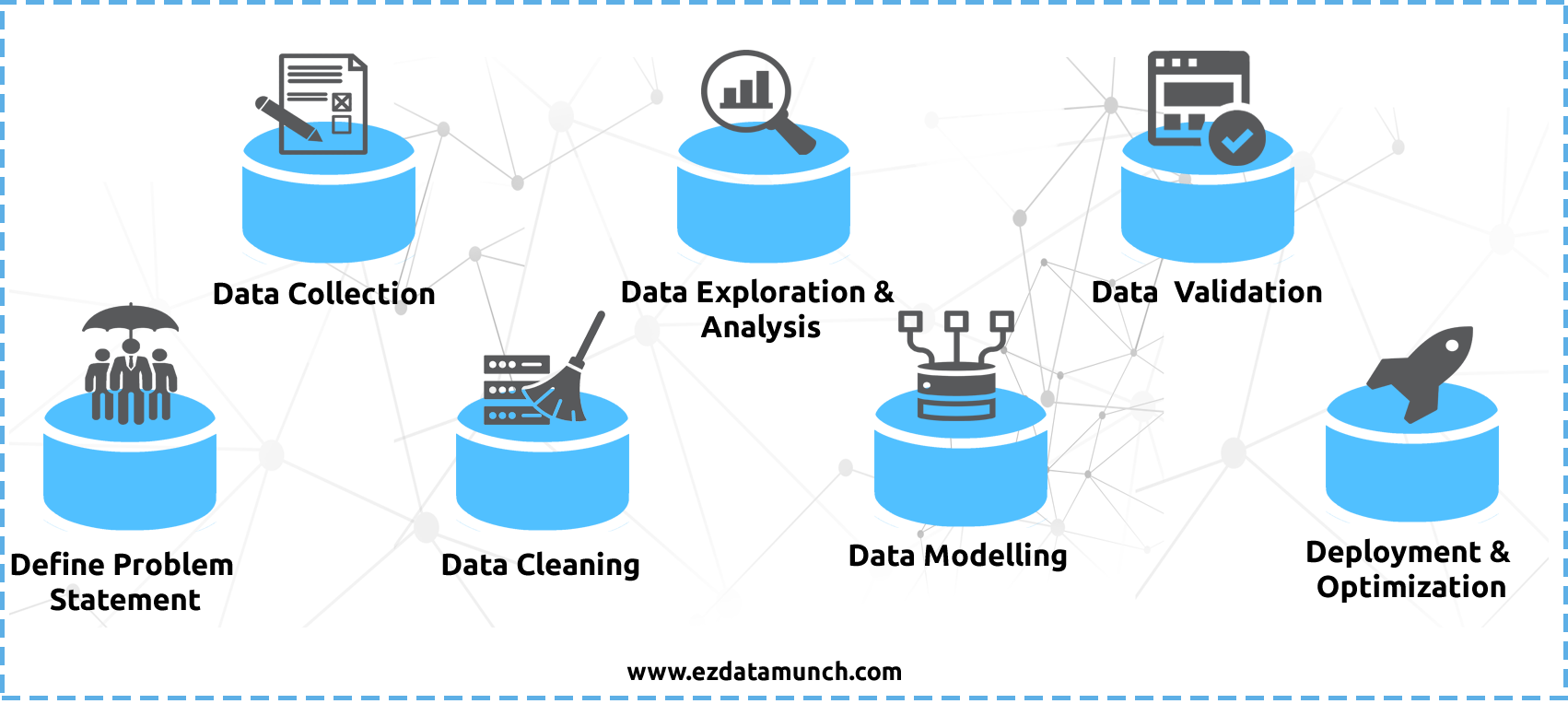
第 1 步:定义问题语句
在开始数据科学项目之前,首先必须定义您的问题,在项目生命周期中将面对这个问题。在此阶段,您应该清楚您的业务的所有目标。
第 2 步:数据收集
在此阶段,您需要收集解决问题所需的所有数据。如果您事先研究数据应该是什么以及应该收集在哪里,这个过程将更容易。此过程不像我们想象的那么容易,因为数据不存在在任何数据库中,因此我们可以轻松获取它,我们必须投入大量精力来查找数据。
第 3 步:清理数据
数据清理是任何数据科学家最不喜欢的任务。清理数据的任务包括删除冗余、缺少的单词、重复和冗余数据。据数据科学家称,观察到这是一个耗时的过程。但是,如果我们需要显式输出,那么此步骤就变得必要了。
第4步:数据分析和探索
完成数据清理过程后,下一步是数据分析和数据探索在此步骤结束时,您应该开始对您的数据和正在处理的问题进行假设。
第 5 步:数据建模
数据建模是在数据库中存储的数据上创建数据模型的过程。数据建模有助于在一定程度上解决问题。模型可以是机器学习算法,该算法使用数据进行训练和测试。
第 6 步:优化和部署
这是过程的结束。在这里,您必须尝试提高创建的数据模型的效率,以便做出更准确的预测。此阶段还用于检查问题和错误(如果在部署之前捕获,则在此阶段内解决)。
使数据科学项目取得成功需要考虑什么
任何数据科学项目都不可能独立成功。它附带了一些关键点,我们必须考虑。
沟通因素:
通信已被证明是成功数据科学项目的有效方法。在处理项目之前,必须清楚地了解业务的目的。
业务理解:
业务理解,只有通过与最接近流程或问题的业务利益相关者的互动才能进行。
适当的规划:
这个计划应该是坚定的。这适用于所有团队成员,他们必须了解个人的作用,以使项目取得成功。
清单:
团队应始终遵循检查表规则。项目经理有责任检查工作中的工作。
为数据科学项目创建创始人层
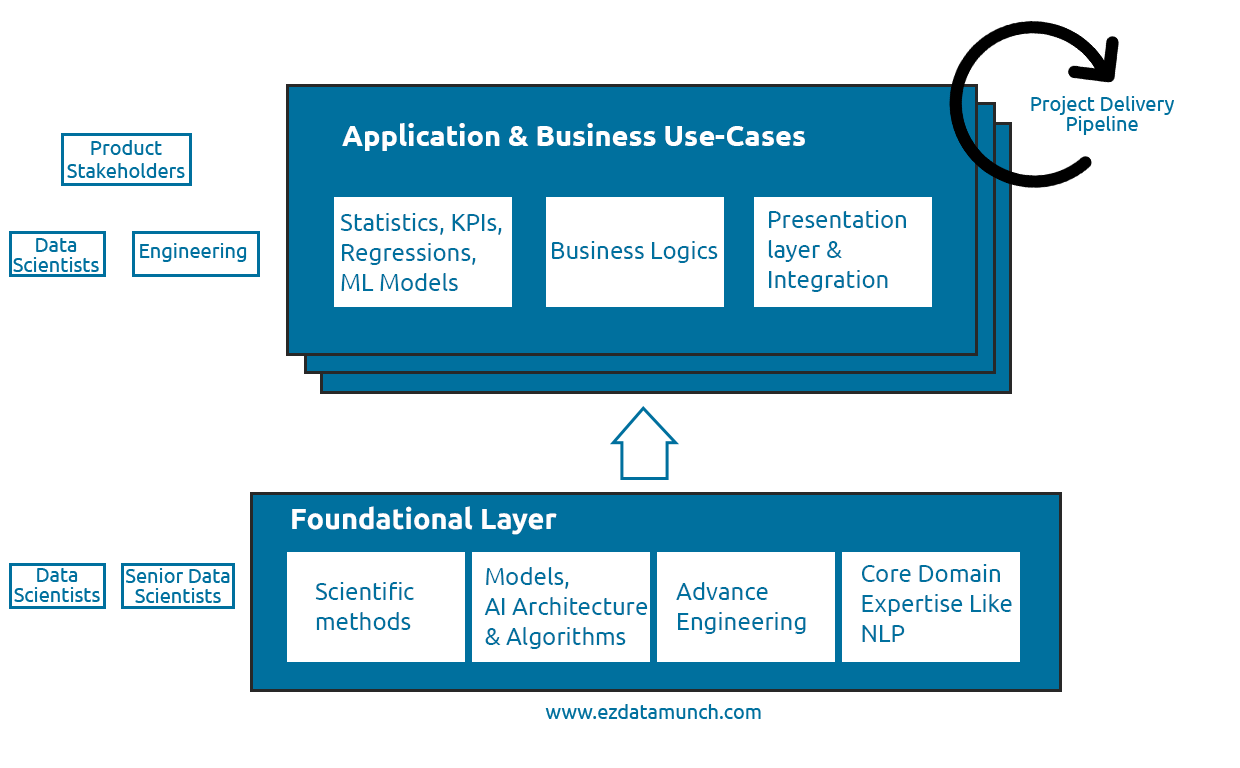
区分数据科学功能和软件开发的因素是数据科学家角色的开放式研究的数量。研究是数据科学的重要组成部分,但不太适合标准敏捷程序。
数据科学家必须调整研究时间,以创建一个可调整的层,数据科学在业务的特定环境中采用不断发展的领域。
基础层可以分为 3 层:
长期:由成熟的数据驱动高科技公司的专业研究团队运营。
中期:通过将数据科学中有时发展的关键领域转变为特定于业务的上下文,从而创建可衡量的基础。
短期:特定于应用程序的挑战,如解决方案设计、表示层、算法选择以及模型和指标的验证方法。
许多有信誉的公司都在为相关领域招聘专业知识和有才华的员工这对团队激励和保留非常重要。构建基础层和管理工作流应该是数据科学家的内部责任。
数据科学项目管理要求
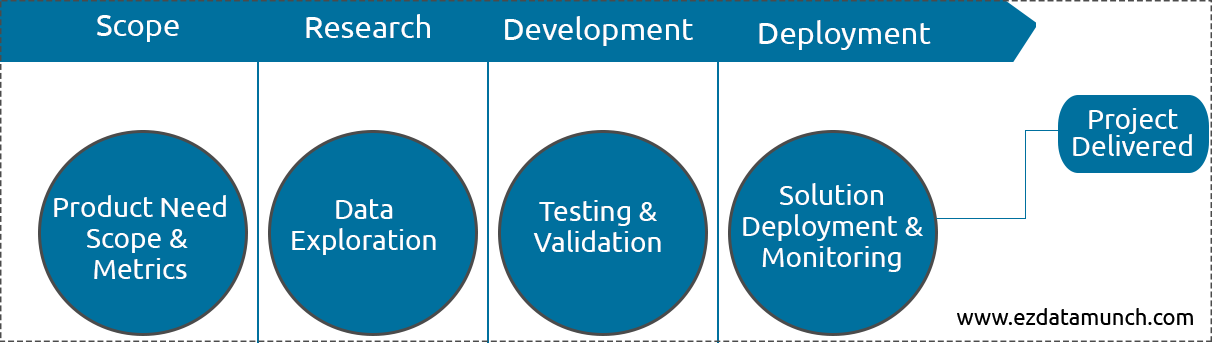
范围界定阶段从产品的需求和要求开始。主要目标将涉及一个成功的项目,以在产品和数据科学之间达成一个范围。思维过程必须大量数据信息,并在很大程度上与数据科学团队合作,以定义现实的项目范围。
研究阶段将能够从数据科学团队建立的基础中汲取基础。此最终解决方案将出色的研究限制在设计(包括表示层和 API)、算法选择和验证方法(如模型和商定的指标)的短期应用程序特定挑战。
在开发阶段,数据科学家编写代码并实现其工作原理。但它与软件工程师的工作方式大不相同。这就是为什么数据科学家使用笔记本而不是传统的 IDEs 的原因。
模型的部署本身就是一个具有挑战性的主题。通常,在上一步中开发的模型数据科学家需要大量的工作才能转换为可以部署在现有堆栈上的企业解决方案。这包括日志记录、监视、审核、身份验证、SL 等要求。