
在今年早些时候在我们的博客上发表的一篇文章中,我们描述了 Snuba(Snuba)设计和体系结构中的一些决策,Snuba 是 Sentry 事件数据的主要存储和查询服务。这个项目是出于必要而开始的;几个月前,我们发现,持续扩展我们现有的基于 PostgreSQL 的基于 PostgreSQL 的解决方案以索引事件数据所需的时间和精力正在成为不可持续的负担。
Sentry 的增长导致我们数据库的写入和读取负载增加,即使在无数次查询和索引优化之后,我们还是觉得我们的数据库从下一个性能临界点或查询计划器崩溃来看,总是一触即发的广度。写入负载的增加还导致存储要求增加(如果您执行更多写入操作,则需要更多放置它们的位置),并且我们运行的服务器数量过多,服务器具有大量磁盘,用于存储数据。我们知道有些事情必须改变。
下面我们来看看我们是如何试图了解哪个数据库系统适合我们,以及当我们遇到一些意想不到的挑战时,我们如何调整我们的方法。
外长后格雷SQL
我们知道 PostgreSQL 不是此作业的正确工具,它提供的许多功能(如 ACID 事务、MVCC 语义,甚至基于行的突变)最终对于我们存储的数据类型以及正在运行的查询类型而言,最终是不必要的。事实上,它们不仅不必要,而且充其量会导致性能问题,而且在我们迄今为止最严重的停电中发挥了重要作用。
我们不能说 PostgreSQL 是问题所在 – 它为我们服务多年,今天我们仍很高兴地使用它在我们的应用程序和基础结构的许多不同的部分,没有任何删除它的意图 – 它只是不是正确的解决方案,我们面对的问题。
我们意识到,我们需要围绕大量行的快速聚合进行系统定位,并针对大量数据的批量插入进行了优化,而不是零敲插入和单个行的突变。
点击”House:更快的查询”和可预测的性能
最终,在评估了几个选项后,我们确定了ClickHouse,这是目前支持 Snuba 的数据库,我们的服务用于存储和搜索事件数据更令人惊奇的是,我们可以用更少的机器和更小的磁盘来实现,因为柱形数据布局可以实现惊人的良好压缩。
不可改变的数据
ClickHouse 可以进行许多性能改进,因为已写入的数据在很大程度上被视为不可变,或者不会更改(甚至被删除)。不变性在数据库设计中起着很大的作用,尤其是对于大量数据,如果您能够假设数据是不可变的,则 DML 语句喜欢 UPDATE 并且 DELETE 不再需要。
如果您只是插入永远不会更改的数据,则事务的必要性就会降低(或完全删除),数据库体系结构中的一系列问题就会消失。这一策略对我们很有效——总的来说,我们考虑一旦处理到哨兵的事件是不可改变的。
此决策主要是实际决策:例如,当用户遇到错误时使用的浏览器版本在事件发生时实际上”冻结在时间”。如果该用户稍后升级其浏览器版本,则我们之前录制的事件不需要重写以说明他们现在使用的任何版本。
不太可变的数据
但是,等待 – 当我们将发送到 Sentry 的事件数据视为不可更改时,这些事件所属的问题可以在 Sentry 中删除,并且这些删除将导致与这些问题关联的事件也会被删除。同样,虽然无法更新事件的属性,但可以通过合并和取消合并来修改事件与问题的关联。虽然这些操作并不常见,但它们是可能的,我们需要找到一种方法,在数据库中执行它们,而数据库不是用来支持它们。
不幸的是,对于普通案例的所有大规模改进,对于 Sentry 中存在的一些常见案例来说也是缺点,但这种情况并不常见,也不意味着不受支持。在本字段指南的其余部分中,我们将探讨可变性如何影响数据库设计和性能,以及我们如何处理数据库体系结构中的突变数据,该体系结构主要用于存储不可变数据:在这种情况下,特别是 ClickHouse。
突变数据 v1:点击房屋ALTER TABLE
我们第一次尝试之一
我们最喜欢的是一个错误,其中整个数据库被重写以更改一行。一旦回归被修复,我们寻求 如果没有直接删除数据的能力 -ClickHouse 没有 首先,了解 ClickHouse 如何将数据存储在磁盘上非常重要,以便我们可以确定我们可处置的选项类型。ClickHouse 提供各种表存储引擎,可根据它们支持的表的特定需求使用这些引擎。 在 ClickHouse 提供的不同表引擎中(而且有很多),我们最喜欢的是 与 LSM 树一样,数据按主键按排序顺序存储,从而通过主键进行高效查找,并针对共享主键组件的范围进行高效的范围扫描。当使用表引擎系列的不同变体时 对于存储哨兵事件的表,我们选择使用 我们的表包括 在 Snuba 中,我们将这些行称为”替换”,因为它们会导致旧行被新行替换。为了确保这些替换标记不包含在将来查询的结果集中,我们会自动将 嗯…这不是我们要找的现在,我们使用同一主键(一个未删除的)和一个未删除的事件,而不是替换原始事件。”这是怎么回事? 要知道这里发生了什么,我们必须深入挖掘 例如,包含时序数据的表可能按小时、天或周进行分区,具体取决于表包含的数据量。每个分区都包含磁盘上的一个或多个数据文件,这些文件称为”数据部件”。每个 不同的类型 了解存储模型的工作原理会突出天真的替换方法的问题:在一段时间内,原始行和(可能有多个)替换行可能可见,因为两个(或更多)具有相同主键的行存在于不同的数据部分中。仅在优化期间,将合并具有重复主键的行,仅留下替换。 减少这种不一致可能性的一个选项是,通过显式发布 作为运行表优化的替代方法,ClickHouse 提供了 使用的缺点是 我们还限制此排除集的总体大小,以便需要筛选大量最近删除的问题的项目改为使用 在 Sentry 中,删除单个事件并不常见 – 事实上,没有一个 API 终结点会独立删除单个事件。但是,有一个终结点提供一次删除整个问题的能力。此操作对于 PostgreSQL 来说非常简单:您只需发出 幸运的是,ClickHouse 允许我们插入带有 相同的策略除了删除外也适用于其他类型的更新,例如将两个问题合并在一起。将两个问题合并在一起时,我们可以构造一个查询,将事件从问题(或一组问题)重写到新的目标问题中: 在这种情况下,我们还可以在后续查询上使用排除集策略 回顾一下,没有就地突变并不是我们在将事件存储移动到完全不同的体系结构时经过深思熟虑的。 但是,通常,提高系统性能的最有效方法是去除任何对系统功能不重要的东西,有时从一开始就没有包含所有电池,这迫使您更有创造力来弥补这些缺点。事实证明,你对某物(如数据库)工作原理了解的越多,就越能欺骗它做你想做的事。 可能感觉我们有些日子要把车开到越野路上…但是,嘿,如果你想写一个现场指南,你首先必须通过现场。您可以在Sentry.io博客上查看此帖子的原始版本。詹姆斯·坎宁安也为这个职位做出了贡献。ALTER UPDATE 再次使用,但令我们沮丧的是,我们一次只能应用一个突变。哨兵用户喜欢合并问题,并且一次应用一个突变意味着不断重写数百万行以改变数千行。即使突变运行得尽可能快,它们也跟不上请求率,我们最终将达到排队突变的高水位线。DELETE 语句 – 我们不得不从不同的角度来思考问题。如果无法删除数据,我们至少可以覆盖其内容并阻止在将来的结果集中返回数据吗?而且,如果没有 ClickHouse 声明,我们怎么能做到这一切 UPDATE 呢?快速旁: 点击房子数据存储
MergeTree 家庭成员 MergeTree 。 实现表面上类似于各种数据存储(如 Cassandra 使用的 SSTable)使用的日志结构合并树数据结构(或 LSM 树)。MergeTree ,每个表都有一个定义的 ORDER BY 子句,该子句也大致等同于主键定义。族的一个成员 MergeTree 是 ReplacingMergeTree ,它支持由未签名整数、日期或日期时间列支持的”行版本”,用于确定在主键冲突时应保留哪个版本的行。突变数据 v2:通过替换删除
ReplacingMergeTree 引擎png”数据-新=”假”数据大小=”50086″数据大小格式化=”50.1 kB”数据类型=”临时”数据-url=”/存储/临时/13204194-屏幕拍摄-2020-04-08-at-82057- am.png”src_”http://www.cheeli.com.cn/wp-内容/上传/2020/04/13204194屏幕拍摄-2020-04-08-在82057-am.png”样式=”宽度:700px;”/>
UInt8 DEFAULT 0 column 用作行版本的已删除的表。删除事件时,我们将插入一个新记录,其主键与现有行相同, deleted 列的值设置为 1 – 实质上用逻辑删除覆盖原始记录。
deleted = 0 表达式追加到 WHERE 针对此表执行的所有查询的子句。此时,我们应该期望表中只有一行(我们的删除逻辑删除):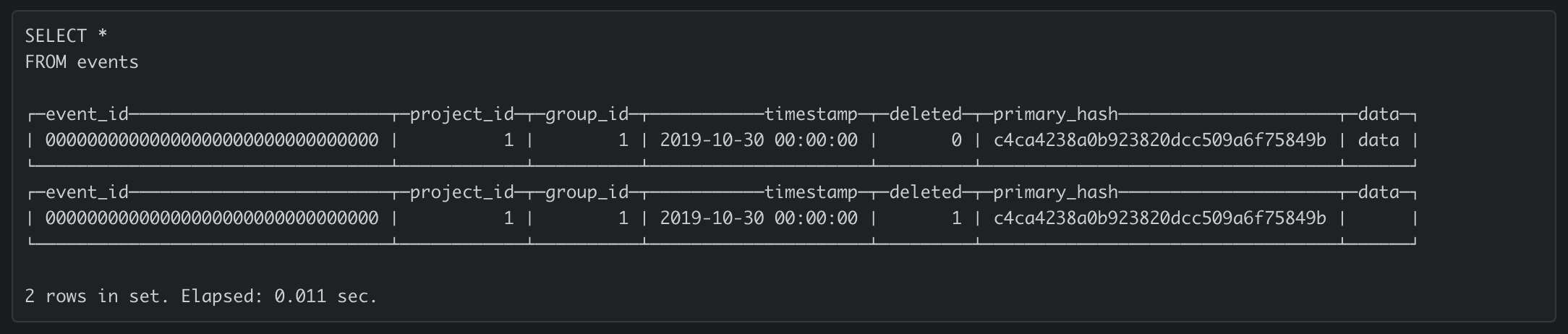
MergeTree工作原理MergeTree 工作原理INSERT 表都为受影响的分区创建一个新的数据部件,其内容 – ClickHouse 因此支持大型写入 – 并且这些数据部分后来在称为优化的进程中与该分区中的其他部分合并在一起。优化通过将内容组合在一起、按主键对组合内容进行排序以及用新的较大部分替换这些较小的部分,将分区中的几个较小部分合并在一起。MergeTree 主要围绕在优化期间遇到主要关键冲突时如何处理它们的不同。等。。。主要的关键冲突?在许多数据库体系结构中,由于无法对主键保持唯一约束,我们的删除查询将失败,因为我们插入的新行的主键与已经存在的行相同。在 ClickHouse 中,没有唯一的约束, MergeTree 并且 – 支持的表可以具有重复的主键。 ReplacingMergeTree不会在插入时替换行,它会在优化期间替换行,并且默认情况下不会尝试协调所有返回的行的状态,以确保它们处于最新状态。FINAL减少潜在不一致OPTIMIZE FINAL 语句来强制优化表。优化是一个资源密集型过程,它合并逻辑分区中的所有物理部分到单个部分,读取和重写分区中的每个行 – 基本上是核选项。FINAL 关键字,该关键字可以添加到 FROM 子句中,以在查询处理期间折叠所有重复项,从而为您提供在紧接运行查询时会收到的结果。OPTIMIZEpng”数据-新=”假”数据大小=”64826″数据大小格式化=”64.8 kB”数据类型=”临时”数据-url=”/存储/临时/13204191-图像- 7.png”src=”http://www.cheeli.com.cn/wp-内容/上传/2020/04/13204191-image-7.png”样式=”宽度:700px;”/>FINAL 查询的执行速度比其他查询慢,有时以显著幅度执行查询。引用ClickHouse 文档,”使用 FINAL 时,查询的处理速度较慢。在大多数情况下,您应该避免使用 Final。为了避免使用 FINAL ,我们会跟踪每个项目最近删除的问题集(在 Redis 中)。每当我们为该项目执行查询时,最近删除的问题集都会添加到 WHERE 子句中,自动排除考虑中的数据,而无需 FINAL 使用 。FINAL 而不是维护非常大的排除集的查询路径。此外,我们运行计划优化以跟上行的周转率,这使我们能够设置在删除启动后排除集中保持问题的时间上限。从
1 到 NULL : 批量操作DELETE FROM events WHERE group_id = %s 查询即可。在 ClickHouse 中, DELETE 定义的 SQL 语句在哪里?如果用户请求我们删除问题中的所有事件,我们如何在不单独删除每个事件的情况下执行此操作?INSERT INTO … SELECT 语句的 SELECT 查询的结果。通过制作一个查询,选择要删除的所有行,并返回包含每行主键、 deleted 列设置为 的列设置为 的的结果集 1 以及设置为 或其默认值的所有其他列 NULL 值,我们可以删除单个语句中的大量行。
SELECT ,以避免需要 FINAL 将受影响的项目添加到每个查询中,因为在合并期间,将事件移动到另一个问题基本上已被删除。吸取的教训:不要认为数据库功能是理所当然的
UPDATE查询 DELETE 在许多数据库系统中非常普遍,因此很容易将它们(以及功能更齐全的数据库的所有其他功能和漂亮特性)视为理所当然。