
经过训练的神经网络得出的解决方案可以在越来越多的任务中实现超人的性能。了解这些解决方案至少会有趣并且可能重要。
有趣,本着好奇心并获得诸如“是否存在人类可理解的算法来捕获对象检测网络如何工作?”之类的问题的答案?[a]这将添加一种新的模式从仅仅查询答案(Oracle 模型)或发送任务(代理模型),到通过研究这些网络解决方案的可解释内部结构(显微镜模型)来丰富我们对世界的理解。 [1]
并且重要在于它的使用是为了追求我们(应该?)要求日益强大的系统所要求的各种标准,例如操作透明度和行为界限保证。我们期望的理想化能力的一个常见例子是通过监控模型的内部状态来“测谎”。 [2]
机械可解释性(mech interp)是可解释性研究的一个子领域,旨在深入了解这些网络。
可以描述两类机械插补查询:
- 表示的可解释性:理解模型所看到的内容以及它是如何做的;即,模型认为在其输入中寻找哪些重要信息以及这些信息在内部如何表示?
- 算法可解释性:了解如何使用此信息在整个模型中进行计算以产生一些观察到的结果

图 1:“A Conscious Blackbox”,James C. Scott 的 Seeing Like a State (1998) 的封面图片
这篇文章涉及表示的可解释性。作为对神经网络表示研究的阐述[b],它讨论了模型表示的各种品质,这些品质的认知置信度范围从显而易见的到推测的和仅仅是期望的。
注释:
- 我将交替使用“模型/神经网络”和“模型组件”。模型组件可以被视为网络中的一个层或其他一些概念上有意义的层集合。
- 在正确引入技术定义之前,我会使用“输入属性”和“输入质量”等表达方式来代替更通俗使用的“功能”。
现在,关于神经网络表示的一些基本假设。
可分解性
模型输入的表示是离散信息编码的组合。也就是说,当模型在输入中寻找不同的质量时,模型的某些组件中的输入表示可以被描述为这些质量的表示的组合。这使得(去)可组合性成为“编码离散信息”的必然结果——模型能够表示输入中看到的一组固定的不同质量。

图 2:针对需要关注背景颜色(仅针对蓝色和红色进行训练)和中心形状(仅针对圆形和三角形)的任务进行训练的模型层)
该组件专用于输入质量的不同神经元:“背景颜色由红色组成”,“背景颜色由蓝色组成”,“中心对象是一个圆圈, ”和“中心物体是一个三角形。”
考虑替代方案:如果模型在训练过程中没有识别出输入的任何预测离散质量。为了很好地完成任务,网络必须像查找表一样工作,其键作为裸输入像素(因为它无法收集任何比“输入像素的有序集”更有趣的离散属性)指向唯一的身份标识。我们在实践中对此有一个名字:记忆。因此,说“模型组件学习识别输入的有用离散质量并将其组合以获得用于下游计算的内部表示”,与说“有时,神经网络不能完全记忆”相距不远。

图 3:学习离散输入质量如何提供泛化性或鲁棒性的示例
此示例测试输入(在训练中未见)具有以学习的质量表示的表示形式。虽然模型可能无法完全理解“紫色”是什么,但它比仅仅尝试对输入像素进行表查找会更好。
重新审视假设:
<块引用>
“模型输入的表示是离散信息编码的组合。”
正如我们所见,这已经是显而易见的事情了;它提供了一个引入更严格规范的模板,值得研究。
这些规范的第一个回顾着眼于“……是编码的组合……”关于这些编码组合的性质,观察到、推测和希望得到什么?
线性度
回顾一下分解,我们期望(非记忆)神经网络能够识别和编码来自输入质量/属性的各种信息。这意味着任何激活状态都是这些编码的组合。

图 4:可分解性假设的建议
这个组合物的本质是什么?在这种情况下,说表示是线性的意味着离散输入质量的信息被编码为激活空间中的方向,并且它们通过向量和组成表示:

我们将调查这两项指控。
主张#1:编码质量是激活空间中的方向
可组合性已经表明,某些模型组件(激活空间中的向量)中的输入表示是由输入质量(激活空间中的其他向量)的离散编码组成的。这里要说的额外一点是,在给定的输入质量编码中,我们可以认为存在质量的一些核心本质,即向量的方向。这使得任何特定的编码向量只是该方向的缩放版本(单位向量)。
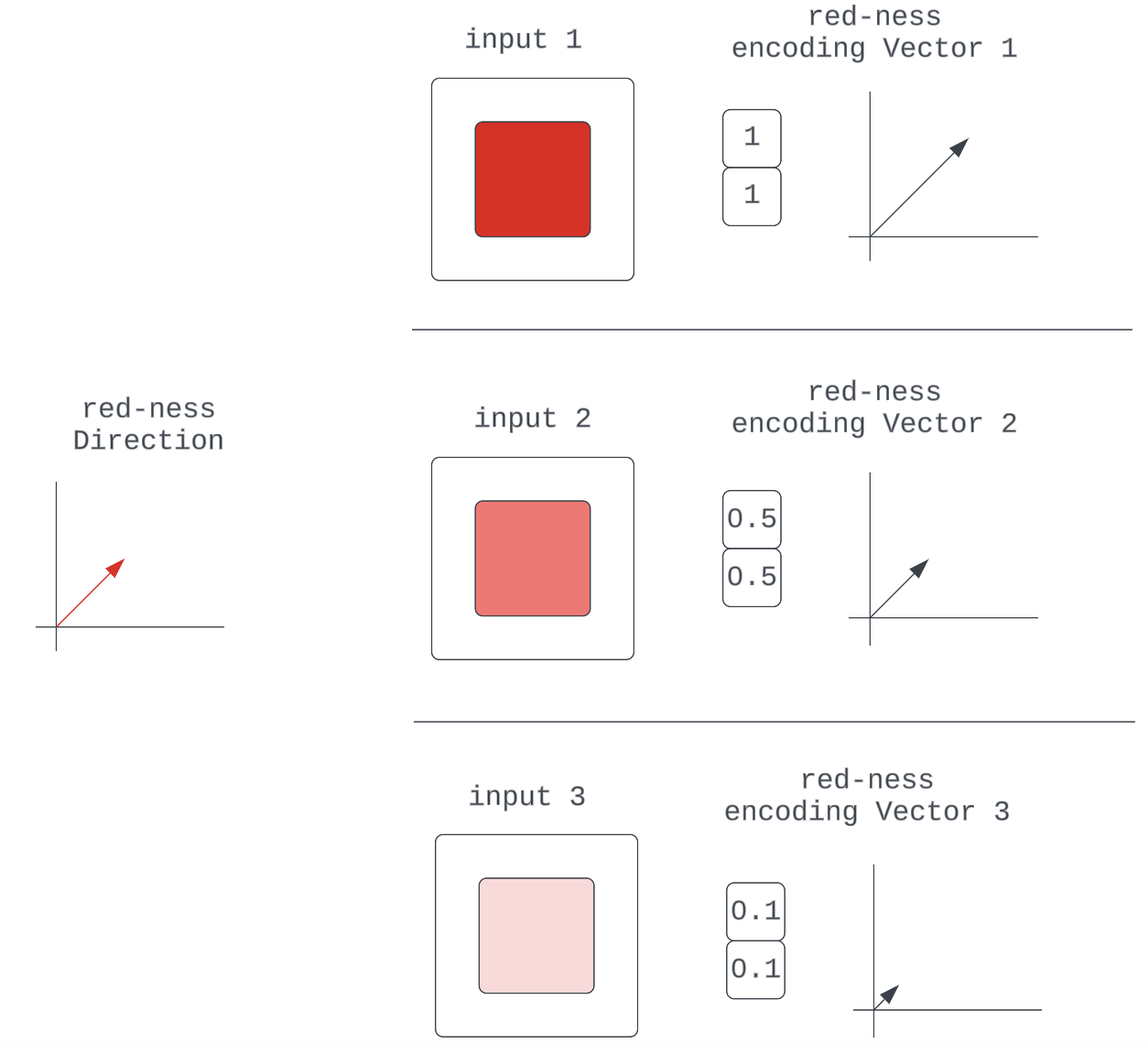 图 5:输入中红色质量的各种编码向量
图 5:输入中红色质量的各种编码向量
它们都只是一些基本红色单位向量的缩放表示,它指定方向。
这只是可组合性论证的概括,即神经网络可以通过缩放某些特征单位向量来学习使输入质量的编码对“强度”敏感。
替代的不切实际的编码机制

图 6a
另一种编码方案可能是我们从模型中获得的只是属性的二进制编码;例如,“此 RGB 输入中的红色值非零。”这显然不是很稳健。
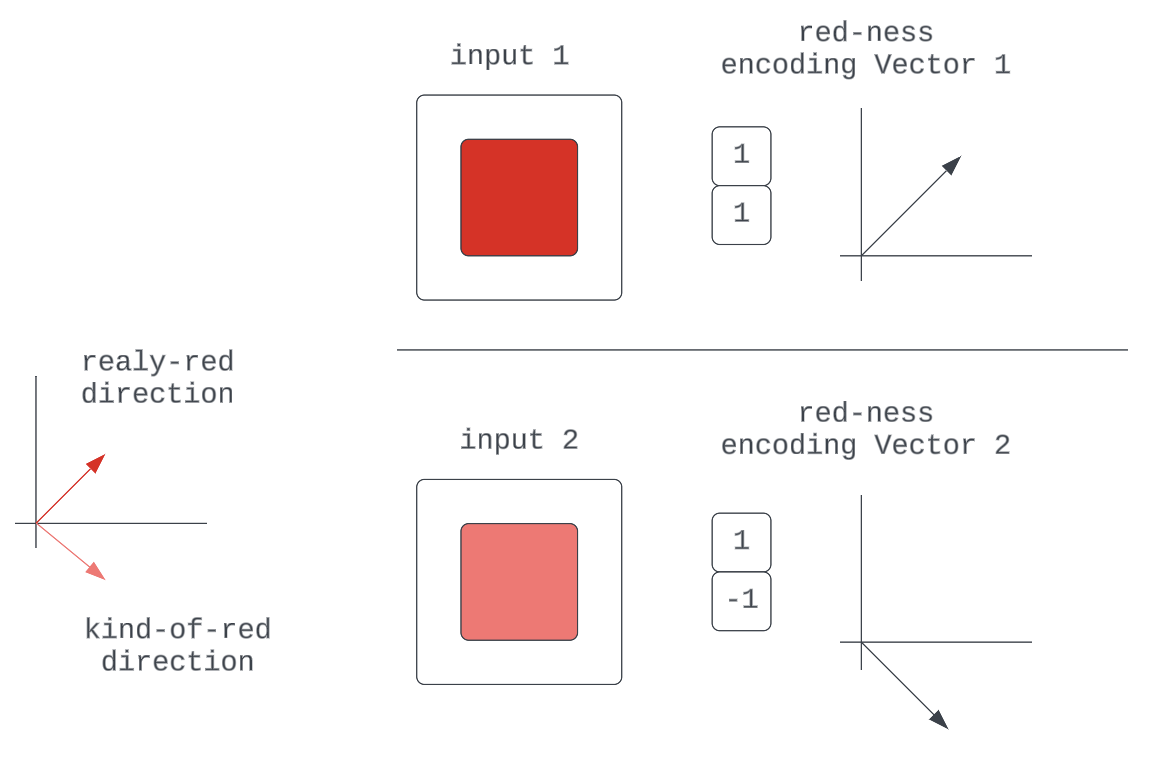
另一个是,我们对质量有多个独特的方向,这些方向可以通过一些更基本质量的尺度差异来描述:“一个神经元用于 RGB 输入中的 0-127 的“红色”,另一个神经元用于RGB 输入中 128-255 为“真红”。”我们很快就会失去方向。
声明 #2:这些编码由向量和组成
现在,这是两个主张中更强有力的一个,因为它不一定是迄今为止引入的任何内容的结果。
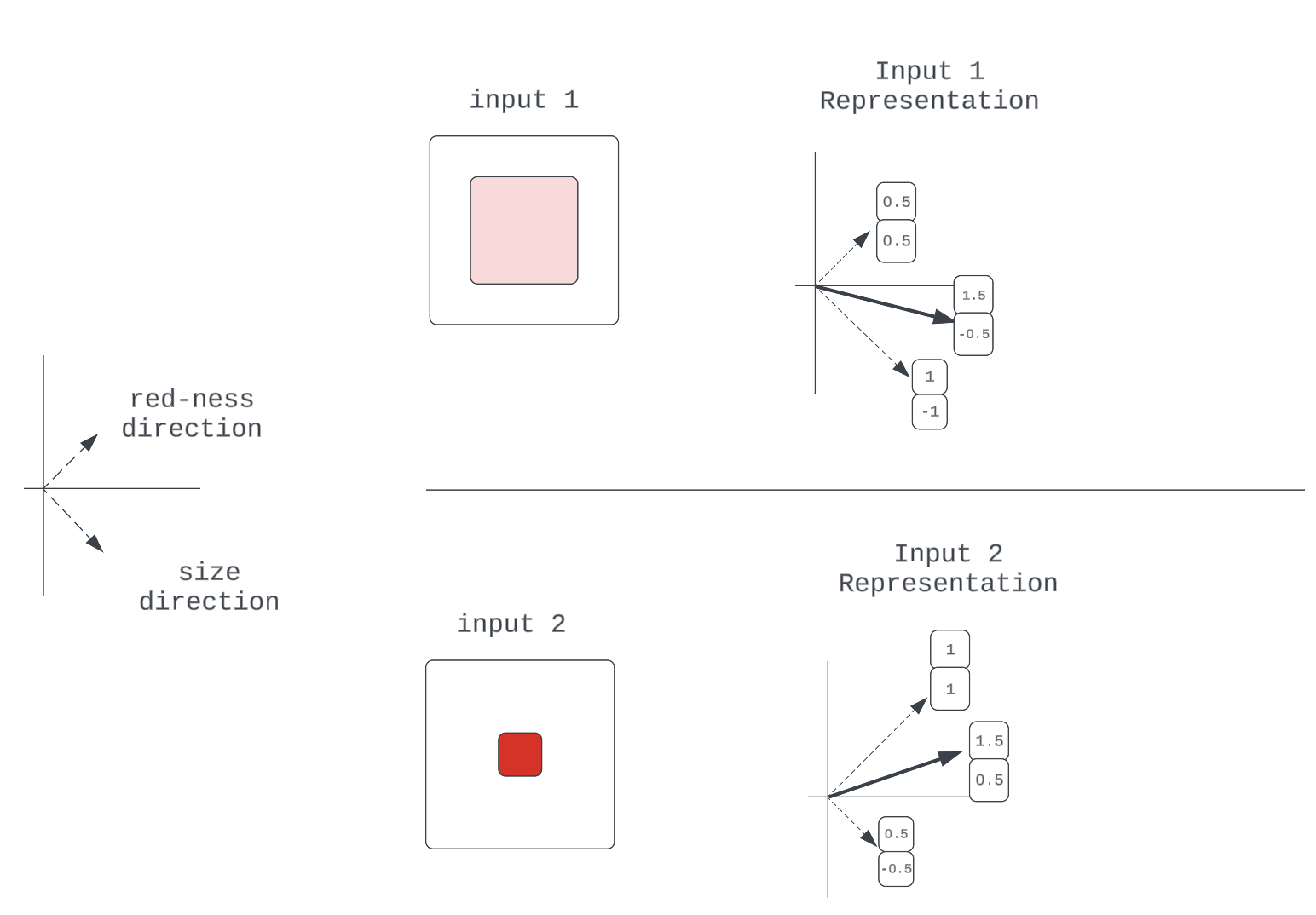
图 7:2 属性表示的示例
注意:我们假设属性之间独立,忽略大小为零意味着颜色不是红色(无)的退化情况。
矢量和可能看起来像是网络可以自然地(如果不是唯一)组合这些编码矢量的事情。为了理解为什么这个说法值得验证,值得研究替代非线性函数是否也能完成这项工作。回想一下,我们想要的是一个函数,它将这些编码组合在模型中的某个组件上,并为下游计算保留信息。所以这实际上是一个信息压缩问题。
正如 Elhage 等人 [3a] 中所讨论的,以下非线性压缩方案可以完成这项工作:
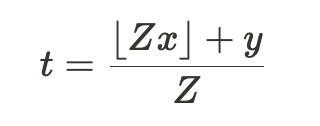
我们寻求将值 x 和 y 压缩到 t 中。 Z的值根据压缩所需的浮点精度来选择。
正如所演示的,我们能够很好地压缩和恢复向量 a 和 b,因此这也是一种压缩信息以供以后使用非-线性,例如神经网络可以近似的floor()函数。虽然这看起来比仅仅添加向量有点乏味,但它表明网络确实有选择。这需要一些证据和进一步的论据来支持线性。
线性证据
经常被引用的表现出强线性的模型组件的例子是语言模型 [4] 中的嵌入层,其中单词表示之间存在如下关系:
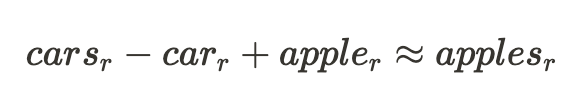 < /p>
< /p>
此示例暗示输入单词中的 $plurality$ 的质量与其表示的其余部分之间存在以下关系:
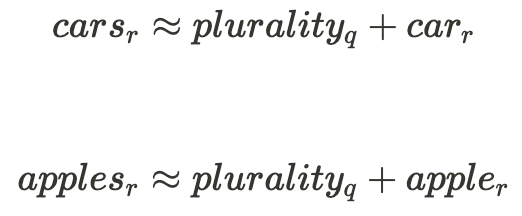
好的,这就是具有线性表示的神经网络类型中的一个组件的一些证据。关于这一点在网络中普遍存在的争论的大致轮廓是,线性表示对于神经网络来说是更自然和更高效的[3b][3a]选项。
这是真的对于可解释性有多重要?
如果非线性压缩在网络中普遍存在,则网络可以在两种替代机制中运行:
- 计算仍然主要在线性变量上完成:在这种情况下,当信息在组件之间非线性编码和移动时,模型组件将仍然解压缩表示以运行线性计算。从可解释性的角度来看,虽然这需要一些额外的工作来对解压缩操作进行逆向工程,但这不会造成太高的障碍。
图8:线性计算干预非线性压缩和传播
- 计算在非线性状态下完成:模型找到了一种直接对非线性表示进行计算的方法。这将带来需要新的可解释性方法的挑战。但是,根据之前讨论的有关模型架构可供性的论点,预计这种情况不太可能发生。
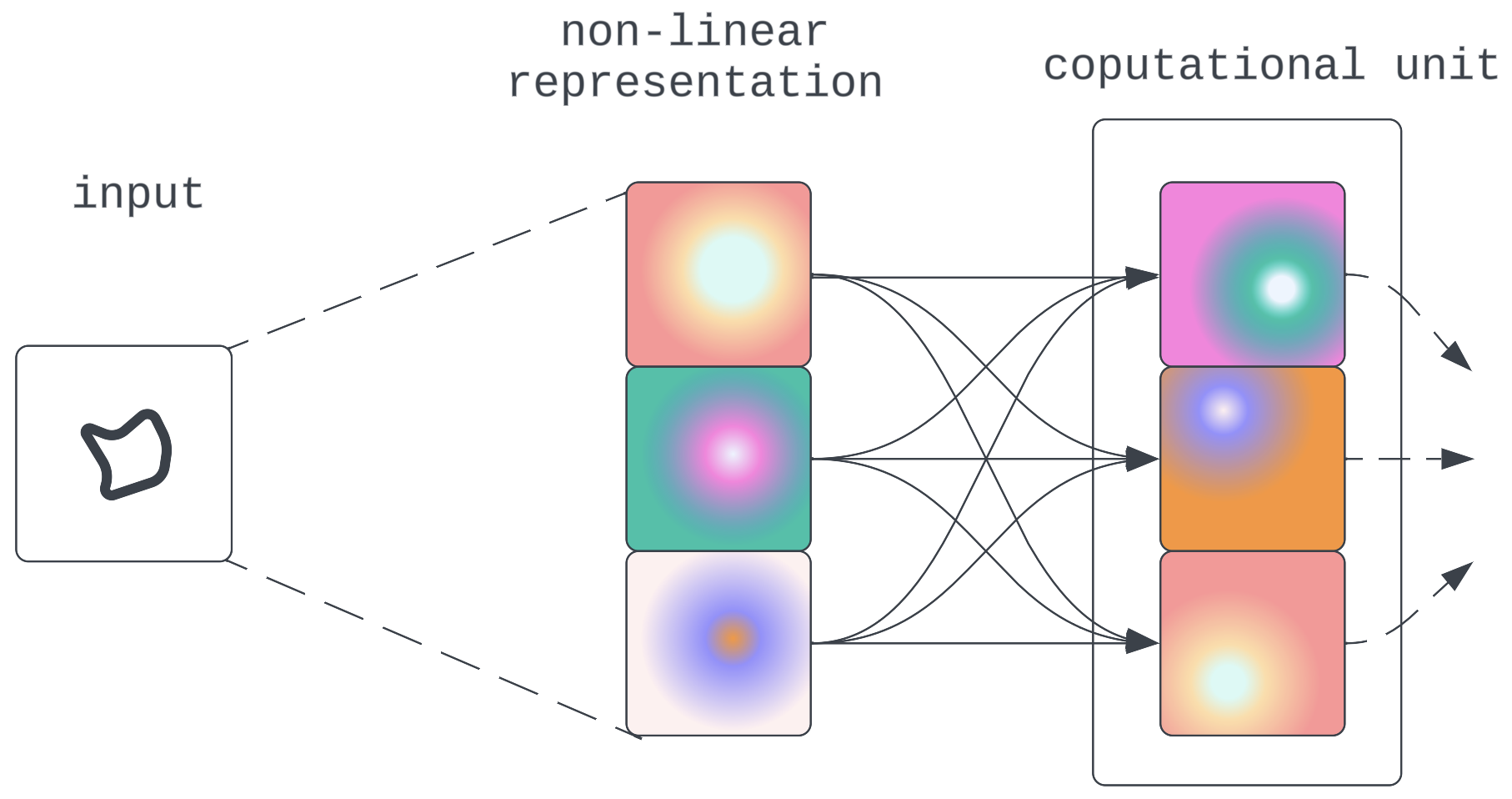
图 9:直接非线性计算
功能
正如引言中所承诺的,在这篇文章中避免使用“功能”这个词之后,我们将正确地介绍它。顺便说一句,我认为研究界对定义我们使用“特征”一词时的含义这一主题的参与是让机械插值作为一门前范式科学令人兴奋的事情之一。虽然已经提出了不同的定义 [3c] 并且最终的结论还没有出来,但在这篇文章和其他关于机甲解释的文章中,我将使用以下内容:
<块引用>
“给定神经网络的特征构成了网络在可能的情况下将神经元专用于的所有输入质量的集合。”
我们已经讨论了网络必须对输入的离散质量进行编码的想法,因此定义中最有趣的部分是,“……如果可以的话,将专门使用一个神经元。”
“…将神经元奉献给…”是什么意思?
如果所有质量编码方向都是激活空间中唯一的单热向量(例如,[0, 1] 和 [1, 0]),则称神经元是基对齐的;即网络中一个神经元的激活独立地代表一种输入质量的强度。
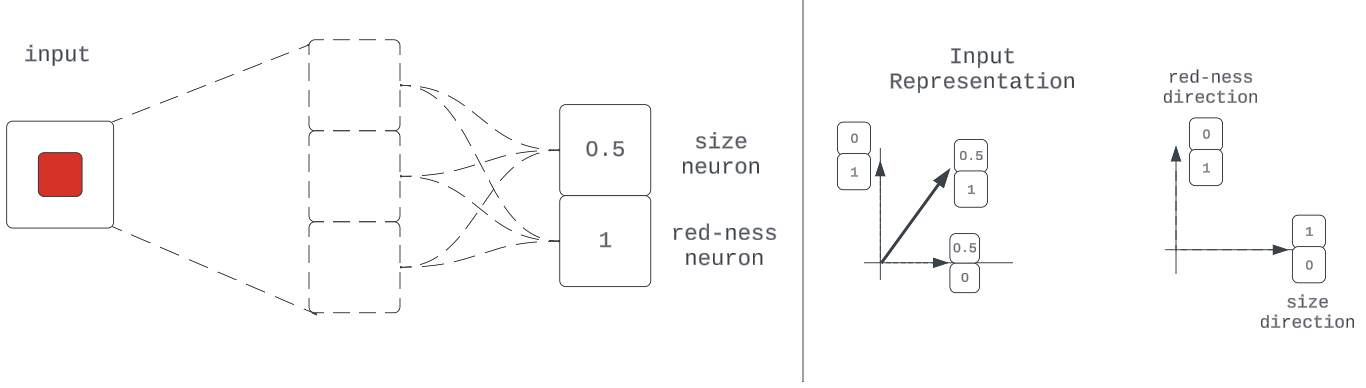
请注意,虽然此属性已足够,但对于使用矢量加法进行编码的无损压缩而言,该属性不是必需的。核心要求是这些特征方向是正交的。其原因与我们探索非线性压缩方法时相同:我们希望完全恢复下游的每个编码特征。
基础向量
根据线性假设,我们期望激活向量是所有缩放特征方向的总和:
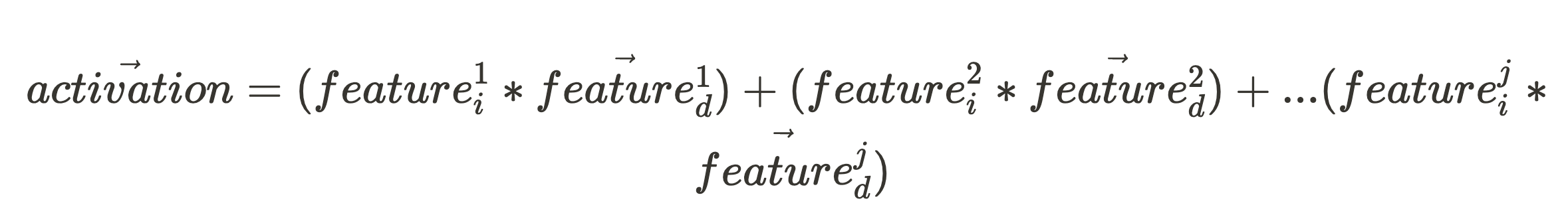
如果该网络组件的所有特征单元向量(组成集合,Features_d)彼此正交:

并且,对于任何向量:
这些简化了我们的方程,给出了我们的特征强度特征^j_i的表达式:
 < /p>
< /p>
允许我们完全恢复我们的压缩功能:

所有这些都是为了建立特征方向之间正交性的理想属性。这意味着,尽管“一个神经元由 x-much 激发 == 一个特征由 x-much 呈现”的想法很容易思考,但还有其他同样性能的特征方向,但没有其神经元激发模式将其与特征模式完全对齐。 (顺便说一句,事实证明基础对齐神经元并不经常发生。[3d])
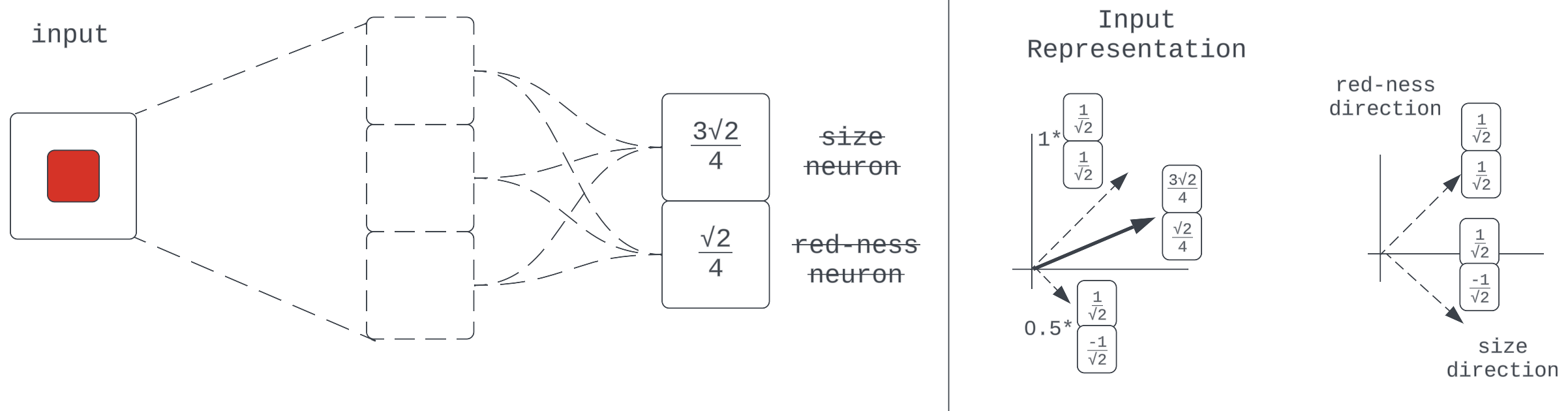
图 11:非基础对齐神经元的正交特征方向
在这种情况下,请求:“将一个神经元奉献给……”可能看起来是任意具体的。也许“专用一个额外的正交方向向量”足以容纳额外的质量。但正如您可能已经知道的那样,空间中的正交向量不会在树上生长。例如,二维空间一次只能有 2 个正交向量。因此,为了腾出更多空间,我们可能需要一个额外的维度,即 [X X] -> [X X X],这相当于有一个专门用于此功能的额外神经元。
这些特征如何存储在神经网络中?
为了快速触草,当模型组件学习了 3 个正交特征方向 {[1 0 0], [0 1 0], [0 0 1]} 来压缩输入向量 [a b c] 时,这意味着什么?
为了获得压缩的激活向量,我们期望每个特征方向的一系列点积来获得我们的特征尺度。

现在我们只需总结我们放大的特征方向即可获得“压缩”激活状态。在这个玩具示例中,特征只是向量值,因此无损解压缩让我们得到了我们开始时的结果。
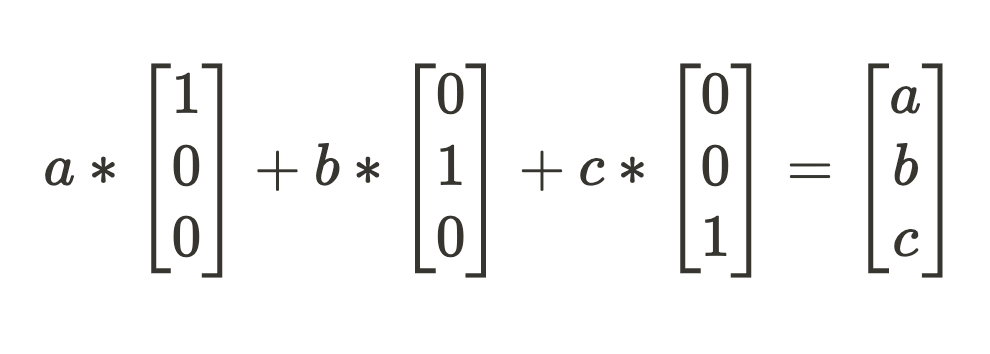
问题是:这在模型中是什么样子?上面的点积变换序列和求和相当于深度学习主力的运算:矩阵乘法。
前面的句子“……模型组件已经学习了 3 个正交特征方向”,应该是一个赠品。模型将其学习结果存储在权重中,因此我们的特征向量只是该层学习的权重矩阵 W 的行。

为什么我不一直说“矩阵乘法。本节结束。”因为我们在现实世界中并不总是遇到玩具问题。学习到的特征并不总是存储在一组权重中。它可以(并且通常确实)涉及任意长的线性和非线性组合序列以达到某些特征方向(但分解线性的关键见解是该计算可以通过用于组成某些激活的方向来概括)。我们讨论的线性承诺仅与特征表示的组成方式有关。例如,某些任意向量更有可能不会仅通过读取层权重矩阵的一行来发现,但对该特征进行编码的计算分布在多个权重和模型组件中。因此,我们必须将特征视为激活空间中任意奇怪的方向,因为它们通常都是这样。这一点使所提出的表示和算法可解释性之间的二分法受到质疑。
回到我们对功能的工作定义:
<块引用>
“给定神经网络的特征构成了网络在可能的情况下将神经元专用于的所有输入质量的集合。”
关于条件子句:“……如果可以的话,会将神经元奉献给……”
您可以将特征的定义视为解决其反事实假设的介绍的一个设置:当神经网络无法通过专用神经元提供其所有输入质量时会发生什么?
叠加
到目前为止,我们的模型在需要通过二维层压缩和传播 2 个学习特征(“大小”和“红色度”)的任务上表现良好。当新任务需要压缩和传播附加特征(例如正方形中心的 x 位移)时会发生什么?
图 12
这向我们的网络展示了一项新任务,要求它传播输入的另一个学习属性:中心 x 位移。为了方便起见,我们重新使用神经元对齐的碱基。
在我们进一步研究这个玩具模型之前,值得思考一下大型现实世界模型中是否存在类似的情况。我们以大语言模型 GPT2 为小语言模型 [5]。您是否认为,如果您有一整周的时间,您可以想到任意 700 个单词的查询的最多 769 个有用特征,这些特征将有助于预测下一个标记(例如,“是一封正式信件”、“包含多少个动词”) “是关于‘Chinua Achebe’”等)?即使我们忽略了特征发现是神经网络已知的超能力之一这一事实,并且假设 GPT2-small 最终也只会编码 769 个有用的输入特征,我们也会遇到类似于我们的玩具问题的情况多于。这是因为 GPT2 在其架构的最窄点只有 768 个神经元可供使用,就像我们的玩具问题有 2 个神经元但需要编码有关 3 个特征的信息一样。 [d]
因此,整个“模型组件编码它具有神经元的更多功能”业务应该值得研究。它可能还需要一个更短的名称。这个名字就是叠加假说。考虑到上述 GPT2 Small 的思想实验,这个假设似乎只是说明了一个显而易见的事实:模型能够以某种方式表示比其维度更多的输入质量(特征)。
关于叠加的假设到底是什么?
我在这篇文章的最后介绍它是有原因的:它取决于其他不一定是不言而喻的抽象。最重要的是预先制定特征。它假设线性分解——神经网络表示的表达为表示其输入的离散质量的缩放方向的总和。这些定义可能看起来是循环的,但如果按顺序定义它们就不是循环的:
<块引用>
如果您将神经网络视为将称为特征的输入离散信息编码为激活空间中的方向,那么当我们怀疑模型具有的这些特征多于神经元时,我们将其称为叠加。
前进的道路
正如我们所见,如果模型的特征与神经元对齐并且它们必须是正交向量以允许从压缩表示中无损恢复,那将会很方便。因此,如果认为这种情况没有发生,就会给解释带来困难,并引发网络如何实现这一目标的问题。
该假设的进一步发展提供了一个模型,用于思考叠加发生的原因和方式,清楚地揭示了玩具问题中的现象,并开发了解决可解释性障碍的有前途的方法[6]。在以后的文章中将详细介绍这一点。
脚注
[a] 也就是说,算法比“采用这个神经网络架构并用这些值填充其权重,然后进行前向传递”更具描述性。
[b] 主要来自 叠加玩具模型
[c] 这特指将功能编纂为超能力。人类非常擅长预测人类文本中的下一个标记;我们只是不擅长编写提取和表示该信息向量空间的程序。所有这些都隐藏在我们的认知机制中。
[d] 从技术上讲,与 768 维残差流宽度进行比较的数字是我们认为*任何*单层必须处理的最大特征数时间。如果我们假设各层之间的计算工作量相等,并假设每批特征都是基于之前的计算构建的,那么对于 12 层 GPT2 模型,您需要考虑的特征将是 12 * 768 = 9,216 个特征。
参考文献
[1] Chris Olah 谈 Mech Interp – 80000 小时
[2] 可解释的梦想
[3] 叠加玩具模型
[3a] 非线性压缩
[3b] 功能作为方向
[3c] 什么是功能?
[3d] 定义和动机
[4] 语言规律连续空间词表示:Mikolov, T.、Yih, W. 和 Zweig, G.,2013。计算语言学协会北美分会 2013 年会议记录:人类语言技术,第 746 页–751。
[5] 语言模型是无监督的多任务学习者:Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever