

吴鑫 Booking.com数据库工程师Team Lead
2015年加入总部位于阿姆斯特丹的Booking.com数据团队,现任数据库工程师团队负责人,主要是负责Booking.com里MySQL相关的运营和研发。具有超过10年MySQL的工作经验,曾经在瑞典担任数据库顾问,解决不同公司的MySQL问题。
摘要: Booking.com于1996年成立于荷兰阿姆斯特丹,是全球规模最大的酒店预订网站之一,隶属于Booking Holdings Inc.(纳斯达克上市公司:BKNG),拥有超过160万家住宿合作伙伴,遍布全球229个国家和地区,日均客房预订量超过150万间。
Booking.com使用MySQL做为主要的数据库解决方案,目前是欧洲最大的MySQL用户之一。本文主要会分享Booking.com的数据库构架?如何实现数据库的高可用性,如何自动化维护和管理大数量级的服务器, 以及如何实现测试环境每日更新亿万数量级的在线数据。
Booking.com数据库构架
Booking.com的MySQL约有数千台服务器,上百个集群,多个数据中心。 数据中心同时实现了异地容灾和异地多活。数据中心间的切换只需要数十秒的时间
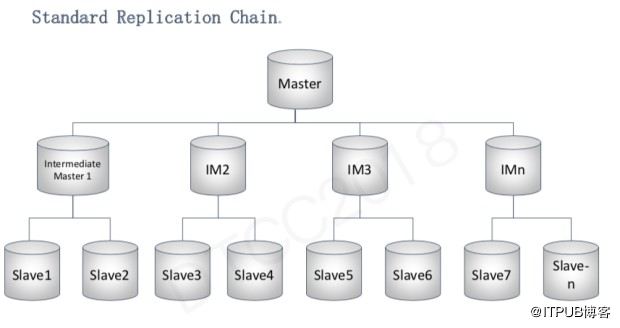
上图是我们一个比较常规的MySQL集群构架图. 一个数据链一般分为三层,最上层是主服务器,下面是IM(Intermediate Master),拖带着不同的从服务器。
之所以会分成三个层级是因为两个原因:
首先为了满足异地容灾的需求,各个数据中心必须要有一套完整的复制链路以确保程序持续稳定的运行,所以需要配备两个以上的IM。
另一个原因是网络带宽的限制。我们的集群小的只有5-10台服务器,大的有200-300台服务器。目前单个服务器的标准网络带宽是10G。大家知道Master slave是通过binlog传输的,如果一个IM下挂载太多的从服务器,会直接用掉所有的网络带宽,所以我们用多个IM来进行网络带宽的分流。我们所有服务器的硬件配置都是一样的,这样的优势是主服务器宕机后,任何一台从服务器都能升级成新的主服务器。
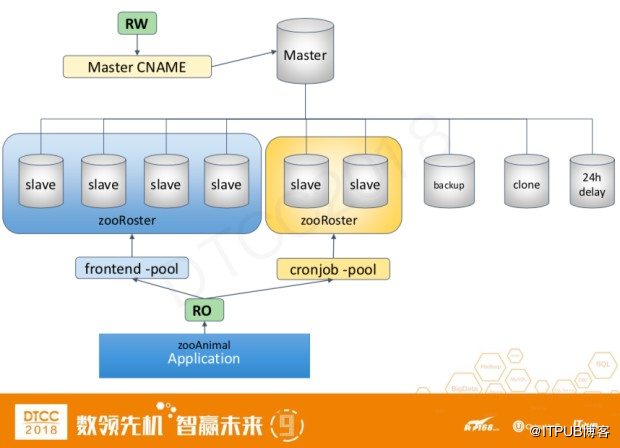
这个是一个比较详细的构架图,我们在主服务器上会绑定一个cname,然后应用程序通过cname在主服务器上进行写操作。从服务器会根据不同的应用程序种类划分到不同的数据库池里面,从而提供读的请求。之所以会分成不同的数据库池,也是因为请求是分优先级的,而且请求的数量级也不通。以图里面的两个数据库池为例,一个是frontend-pool,这一类型的SQL语句一般都比较简短,而且对响应速度要求很高。而第二个cronjob-pool 一般是一些定时任务的语句。这类型的语句一般会比较复杂,而且有时需要花几秒或者几十秒才能完成。把不同类型的请求分开可以避免它们之间的互相影响。另外一个优势是当查询语句都基本相似的时候,hot data会缓存在innodb_buffer_pool里,这样减少了直接的磁盘读取,提高了响应速度。
我们的数据库池是通过zookeeper来进行管理的。如果一个从服务器宕机,或者添加新的从服务器,我们会用内部研发的zooRoster和zooAnimal在MySQL端和应用程序端自动添加和删除。
我们除了有对应用提供服务的从服务器,每个集群还有一些特殊的从服务器。比如用于备份,数据克隆,以及24小时延时的从服务器。延时的从服务器是为了更快的进行线上的数据恢复。
自动化案例分析

由于我们有大量的服务器,但是团队人数只有个位数,所以基本上所有的系统维护都是通过自动化实现的。我们内部研发的Booking Admin(badmin)软件,它能实现操作系统和MySQL版本的自动升级。对指定任务进行自动执行,其中包括数据库的备份与恢复。也能通过监测服务器和数据库的状态对数据池进行自动添加和删除的操作。
我们有几百万个表,每天开发人员都会添加新表或者更改表结构,我们开发了一套系统,开发人员可以在网页上提交对表结构修改的语句,然后后台会自动对提交的语句进行检测,其中包括语法是否正确,以及是否符合公司内部的要求。如果提交的语句有问题,会实时给出修改建议。如果通过检测,DDL语句会在主服务器上自动运行。
接下来给大家详细介绍一下如何进行数据库的读写扩展。
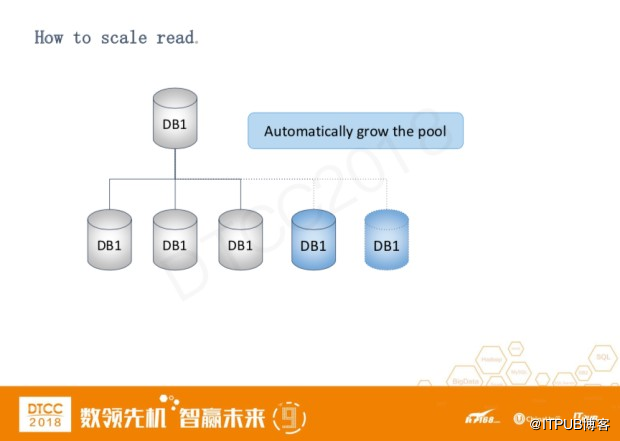
首先介绍一下,我们是如何扩展读操作。这个相对来说比较简单,当badmin检测到服务器容量不够,它会自动的往数据库池里面添加服务器。
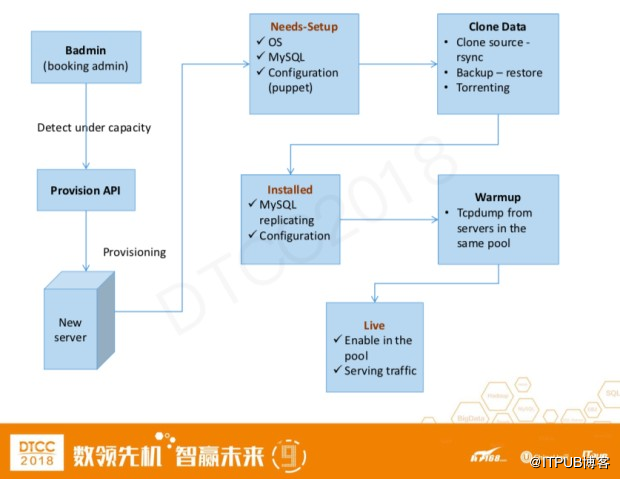
上图是这个添加服务器的具体流程。
● badmin 检测到容量不够, 自动像ProvisionAPI请求新建服务器
● ProvisionAPI根据集群的类型提供相应的服务器配置
● 服务器系统安装完成会被设置成needs-setup的状态,在这个状态下MySQL和部分系统配置安装完成。以上几个过程大概需要十到十五分钟的时间。
● 配置完成后接下来进行数据的克隆。一共有三种方式可供选择
○ 从克隆从服务器上进行文件的rsync操作
○ 从备份进行恢复
○ 如果需要克隆的服务器很多,会自动进行Torrent的方式进行
● MySQL克隆完成后会进入到installed的状态,此时MySQL的主从复制已经开始执行,但是会有一定的数据延迟。
● 在主从库数据一致后,我们不会直接把服务器放到线上进行使用,而是通过tcpdump线上同一个数据库池里面的SQL语句进行一个warmup的过程。
● 当innodb_buffer_pool达到一定的百分比,服务器被设置成live状态,此时会在数据库池里面被激,接收线上请求。
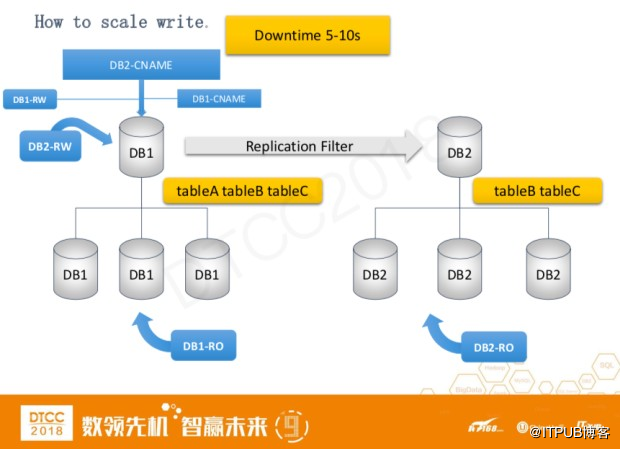
接下来是对写扩展的介绍,主要通过对数据库进行表分离来实现。
以上图为例,对DB1的tableB和tableC进行表分离。
● 首先搭建一个新的复制链DB2
● 把tableB和tableC复制到DB2上,然后再DB2通过replication filter从DB1上进行主从复制
● DB2搭建相应的数据库池,然后将读操作从DB1分离到DB2上
● DB2 主数据库的cname是指向在DB1服务器,所以写操作还是在DB1上。
● 修改所有应用程序的数据库DB2配置,然后等待所有应用程序的rollout。
● 当所有的tableB和tableC的流量分离到DB2上后,进行写操作的分离
○ DB2的cname指向到DB2的主服务器,此时tableB,tableC的写操作是宕机的,这个过程大概是5-10秒
○ 在DB2的主服务器上去掉replication filter,写分离完成。
高可用性解决方案
我们的高可用解决方式是用的开源软件orchestrator。https://github.com/github/orchestrator 软件的原开发者曾经任职于Booking.com,所以很多功能符合我们的需求。
orchestrator是一个对MySQL Replication的拓扑管理和可视化的工具。当有新的mysql节点添加或者删除时,它会自动对拓扑进行更新,也可以随时改MySQL在数据链里的层级。它提供网页的界面操作,也可以通过命令行进行操作。它可以自动检测MySQL的宕机,并且进行自动的恢复。
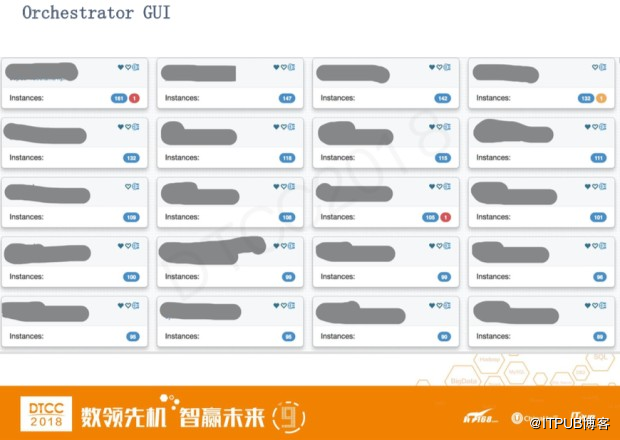
上图orchestrator的主界面,里面包含了所有集群的总信息。其中蓝色的数字表示集群的大小,红色的表示有多少服务器在这个几群里目前是无法连接上的,黄色的部分表示有多少现在是有延迟的。
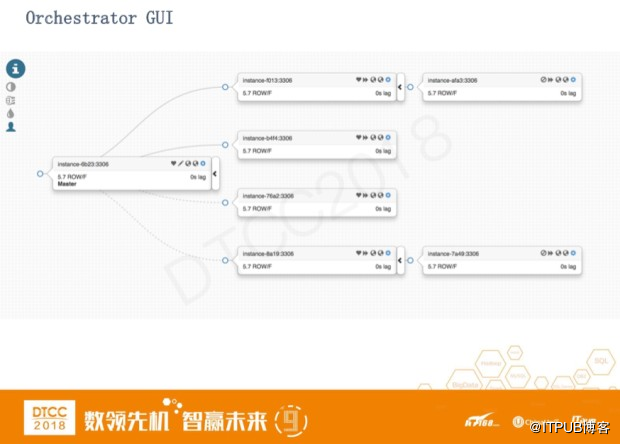
这是一个MySQL Replication集群的界面。Orchestrator自身是没有Intermediate Master这个概念的。只要服务器下面拖拽了一个从服务器,如果这个服务器宕机了就会进行自动恢复。它会把下面的从服务器自动的挂载到其他的性能优良的服务器上。
测试环境的搭建
我们所有的应用程序的测试系统都是搭建在虚拟机上的。每个程序员可以有一套或者多套自己的独立完整的测试系统。数据库的测试系统也是搭建在虚拟机上,并且95%的数据都是线上数据,而且每24小时会将线上的数据更新到测试系统中。需要更新的数据量是PB级别。
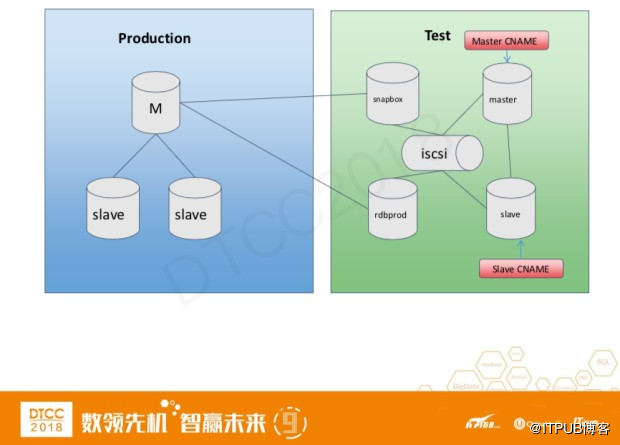
上图是我们的一个测试系统构架,左边是我们的线上环境,右边是我们的测试环境。
测试环境有4种不同类型的数据库
● snapbox: 和线上连接并实时接收线上的数据更新
● master – slave: 每24小时更新一次,开发者可以在这个数据链路上进行各种读写测试
● rdbprod: 实时接收线上数据更新,如果开发者想对线上数据进行读操作的测试,可以将配置文件切换到rdbprod上。
测试系统的存储方式用的是ISCSI,所以每次更新的时候master和slave是对snapbox上的iscsi做snapshot。由于测试系统是每24小时更新一次,所以所有的数据改变在系统更新后都会自动删除。
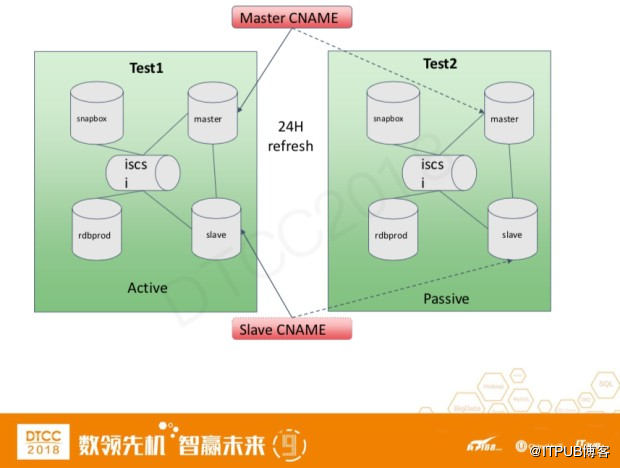
我们一共有两套测试系统,这样做的目的是为了保持测试系统能随时在线提供服务。每次做snapshot的时候,主从服务器是不能访问的,这个过程短则5-10分钟,长则30-40分钟。两套系统会被分成active和passive两个状态。主从服务器的cname一直指向active set。当passive set成果的做完了snapshot的操作,cname会自动切换到passive set上。这样宕机的过程只有5-10秒的时间。