
Spark 提供流式处理库,以处理来自实时系统的连续数据流。
概念
Spark 流式处理最初使用在 Spark RDD 上运行的 DStream API 实现,其中数据从流源划分为块,然后进行处理,然后发送到目标。
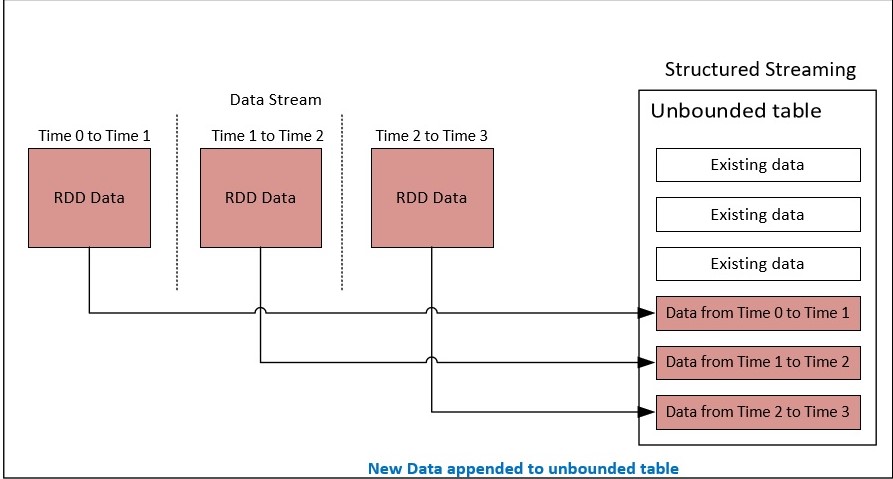
从 Spark 2 中,在 Spark 中开发了一个新模型,该模型是结构化流式处理,该模型构建在用于 DataFrame 和数据集的 Spark SQL 引擎之上。
结构化流利用连续数据流作为无界表,在从流处理事件时不断更新。
Spark 流式处理应用程序可以使用 SQL 查询实现,这些查询对此未绑定数据执行各种计算。
结构化流处理几个挑战,如一次次的流处理、增量更新等。
结构化流基于从源提取数据的触发间隔轮询数据。在将结果数据集设置为接收器时,需要输出模式。它支持追加模式(只有添加到结果表中的新数据元素将写入接收器)、更新模式(只有结果表中更新的数据元素将写入接收器)、完整模式(结果表中的所有项目都将写入接收器)。
内置源和接收器
结构化流支持跟踪内置数据源。
文件源:允许读取放置在特定目录中的文件。支持的格式包括文本、CSV、镶木地板、JSON
卡夫卡来源:流库为卡夫卡消费者提供从卡夫卡经纪人读取数据。这在生产中使用非常多。
套接字源:可以使用 UTF-8 格式的套接字连接从套接字读取数据
支持的各种内置接收器如下所示
文件接收器:将输出存储到目录
卡夫卡水槽:将输出存储在卡夫卡中的一个或多个主题
控制台接收器:将输出打印到控制台,用于调试目的
内存接收器:输出作为内存中表存储在内存中,用于调试目的
Foreach 接收器:对输出中的记录运行临时计算
处理容错
结构化流通过使用检查点保存作业状态并从失败阶段重新启动作业来提供容错。这也适用于使用 DStreams 的火花流
- 源必须是可重播的,尚未提交
- 流式处理接收器设计为处理后处理的幂等功能
示范
文件源
在本演示中,我们将看到 Spark 流与一些计算使用文件源和生成输出到控制台接收器。
此用例包含与员工相关的示例 csv 数据集,其中包含”empId、empName、部门”字段。csv 中的数据将放置在文件夹的特定位置。
Spark Stream 内置文件源侦听目录更新事件通知,并将数据传递到计算层以进行所需的分析。在此示例中,输出将流式传输到控制台。
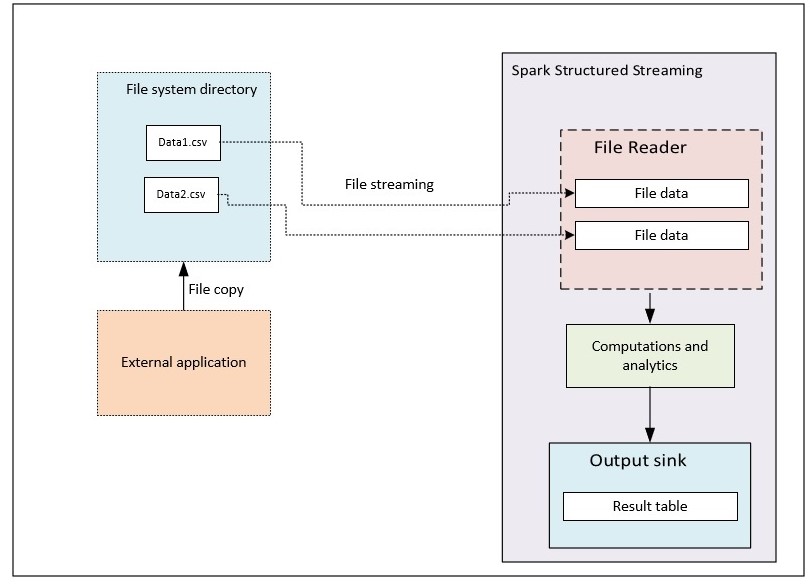
下面的示例是 Spark 结构化流程序,它根据文件流数据计算特定部门的员工计数
将结果记录到控制台
流查询查询 = 结果
.写入流()
.格式("控制台")
.输出模式(输出模式)选项("截流",假)
.选项("numRows",50)
.开始();
查询.await 终止();
}
}
"数据朗="文本/x-java"*
Ⅹ
包com.火花流;
导入组织。阿帕奇.火花。sql.数据集;
导入组织。阿帕奇.火花。sql.编码器;
阿帕奇.火花。sql.行;5导入组织。阿帕奇.火花。sql.火花会话;6导入组织。阿帕奇.火花。sql.api.贾亚.UDF1;7导入组织。阿帕奇.火花。sql.流。输出模式;8导入组织。阿帕奇.火花。sql.流。流查询;9导入组织。阿帕奇.火花。sql.流式处理1px;"*导入组织。阿帕奇.火花。sql.类型。数据类型;
11公共类数据流|12公共静态void主(字符串args抛出流查询异常)13{14//设置卡夫卡源的 hadoop 主目录15系统。套属性("hadoop.home.dir""d:/winutils");16生成器()17.主("本地]")18.应用程序名称("结构化查看报告")19.获取或创建();20会话.火花上下文()。设置LogLevel("错误");21//定义 UDF 来解析可传递给 Spark SQL 的 kafka 消息22会话寄存器("会话持续时间Fn",新的 UDF1<字符串,长>() |
23公共长调用(字符串消息值引发异常|25字符串= strArr=消息值。分裂(",");26//返回 Kafka 消息的会话持续时间值,这是通过 fron Kafka 代理的昏迷分隔字符串值中的第一个值27返回长1px;"> }
29数据类型。长型;30会话.乌夫()。寄存器("用户名Fn"新UDF1<字符串String>() |31公共字符串调用(字符串消息值引发异常|33字符串= strArr=消息值1px;"• //从 Kafka 消息返回用户名值,这是通过 fron Kafka 代理的昏迷分隔字符串值中的第二个值
35返回strArr=1=;36}37数据类型。字符串类型;38//定义卡夫卡流媒体阅读器40数据集<行>df=会话1px;"> .格式("卡夫卡")
42.选项("kafka.bootstrap.server""本地主机:9092")43.选项("订阅""会话数据")44.负载();45启动 数据帧操作47创建或替换TempView("session_data_init");48键、值、时间戳是 kafka 消息中的核心属性。值包含具有会话持续时间、使用 id 值格式的昏迷分隔字符串49数据集<行>预结果=会话。sql("选择会话DurationFn(以字符串(值为字符串))作为session_duration,用户名Fn(以字符串值))作为用户名,时间戳从session_data_init";50预结果。创建或替换TempView("session_data");51//计算 2 分钟窗口和用户名上会话持续时间分组的总和52数据集<行>结果|53sql("选择窗口,总(session_duration)作为session_duration,用户名从session_data组(时间戳,'2 分钟'),用户名";54//将结果记录到控制台56流查询查询=结果57.写入流()58.格式("控制台")59.输出模式(输出模式)。更新())60选项("截流",假)61.选项("numRows"50)62.开始();63查询。等待终止();64}65}66在此示例中,Kafka 代理在键值对中发送消息,其中值为闭空,使用会话持续时间和用户名值分隔字符串jpg" 数据-新="false"数据大小="259652"数据大小格式化="259.7 kB"数据类型="临时"数据 url="/存储/临时/13448028-un 标题8.jpg"src="http://www.cheeli.com.cn/wp-内容/上传/2020/05/13448028-无题8.jpg"样式="宽度:637px;"/>
这些用例构建为 maven 项目。以下是在 pom.xml 中添加的依赖项
Xml
xxxxxxx1311<依赖>2<组 Id>org.apache.spark</组 Id>3<工件Id>火花-core_2.11</工件Id>4<版本>2.4.0</版本>5</依赖项 >6[ <组 Id>org.apache.火花< /组Id>8<工件Id>火花-sql_2.11</工件Id>9<版本>2.4.0</版本>10</依赖项 >11<依赖>12<组 Id>组织火花</组 Id>
13<工件Id>火花-streaming_2.11</工件Id>14<版本>2.4.0</版本>15</依赖项 >16<依赖>17<组 Id>组织.apache1px;"[ lt;工件Id>火花流-卡夫卡-0-10_2.11</工件Id>
19<版本>2.4.0</版本>20</依赖项 >21<依赖>22<组 Id>org.apache.spark</组 Id>23</工件Id>24<版本>2.4.0</版本>25</依赖项 >26<依赖>27<组 Id>org.apache.hadoop</组 Id>28<工件Id>有op-hdfs</工件Id>29</版本>30</依赖项 >性能调优技巧
以下是 Spark 流式处理应用程序中需要考虑的几个性能提示
1. 在上述 Kafka 源的 Spark 流输出中,有一些延迟到达数据。例如,如下所示,用户19数据的第一个版本可能应以批处理 1 形式到达,但已到达第 2 批进行计算。
存在延迟到达数据的情况,必须在较早的窗口数据上执行此数据的计算。在这种情况下,早期窗口数据的结果存储在内存中,然后与延迟到达数据聚合。像 Spark 流式处理这样的框架负责此过程。但是,由于历史数据存储在内存中,直到丢失的数据到达,这可能导致内存累积,因此可能存在更多的内存消耗。在这些情况下,Spark 流具有水印功能,当它超过阈值时丢弃 延迟到达数据。在某些情况下,由于丢弃了这些值,业务结果可能会不匹配。为了避免这些类型的问题,必须实现自定义功能来检查数据的时间戳,然后将它存储在 HDFS 或任何云本机对象存储系统中,以便对数据执行批处理计算,而不是应用水印功能。此实现会导致复杂性。
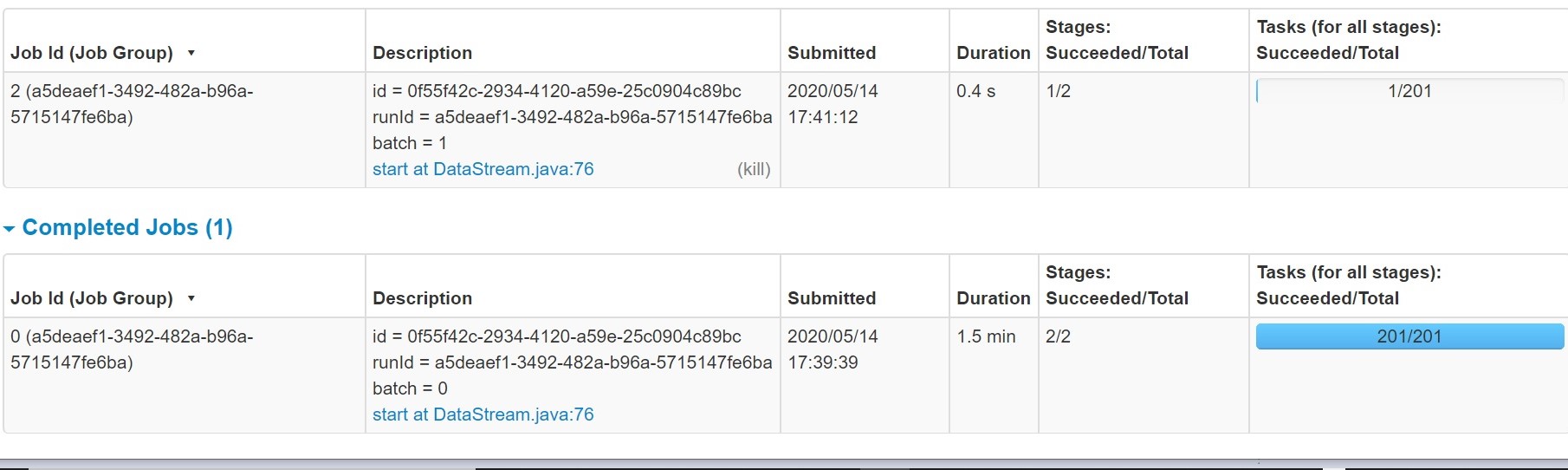
2. 在上述kafka源的Spark流输出中,数据计算缓慢存在一些性能滞后
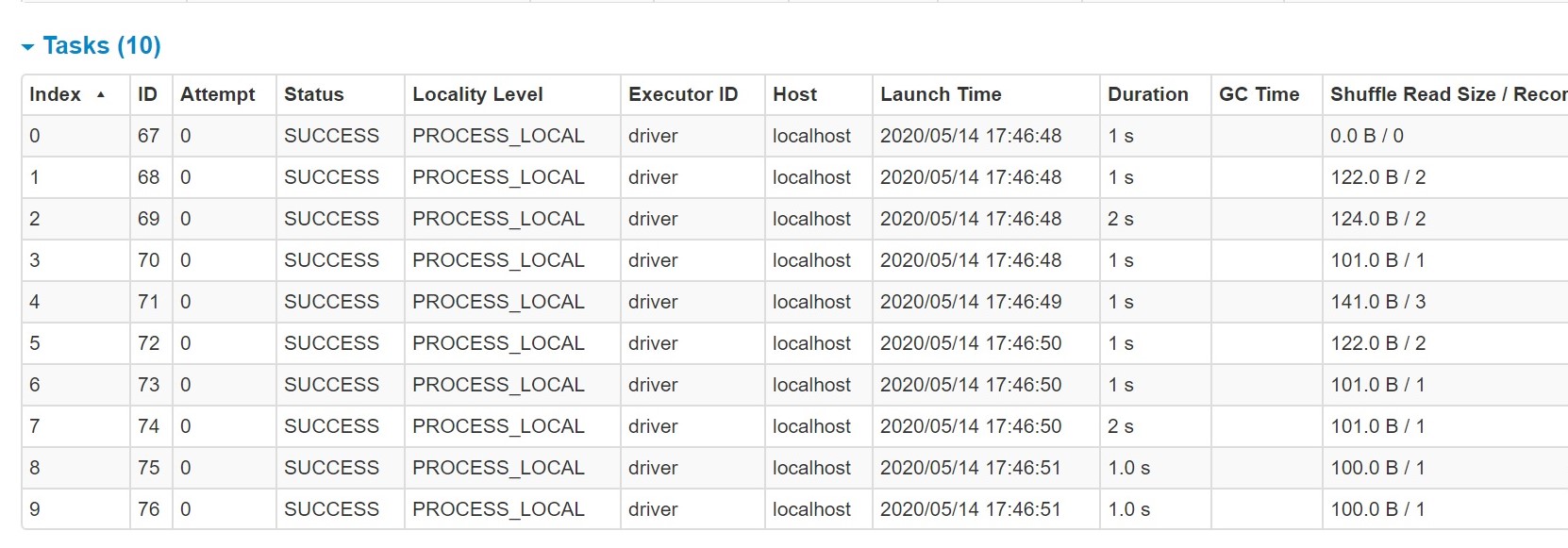
这项工作需要1.5分钟以上
当我们打开已完成作业的任务信息时,我们可以看到有许多分区创建,处理了 0 个洗牌任务。这些分区上的这些虚拟任务将需要一些时间来启动和停止,并且通过增加导致延迟的总处理时间来达到
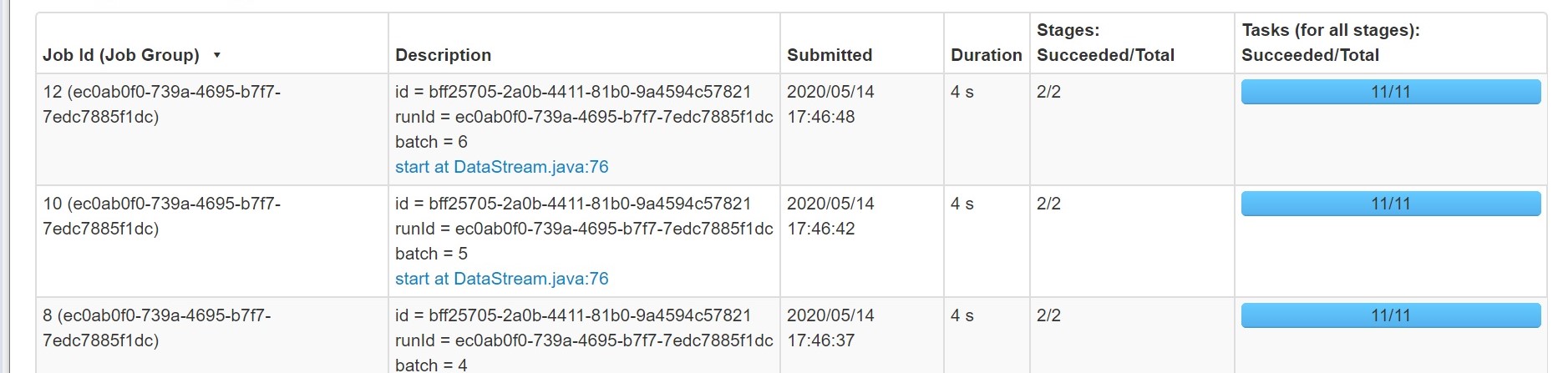
默认情况下,将创建 200 个分区,如上所示。执行分组操作时,处理时的火花使用洗牌。在洗牌期间,将创建数据分区,每个分区都将分配任务。Spark SQL 必须决定使用多少个分区。在这些情况下,将在随机读取期间创建更多分区,许多分区将没有数据可处理。 这是因为输出中作为分区大小的键并不多。 这些分区上的这些虚拟任务将需要一些时间来启动和停止,并且通过增加导致延迟的总处理时间来达到此时间。建议在 Spark 代码中设置以下属性。 此属性确定在洗牌联接或聚合的数据时使用的分区数
Java
xxxxxxx1会话。()设置("spark.sql.shuffle.分区","10"); "10"使用此参数,我们可以观察到作业性能已提高,并且创建了最佳分区数,如下所示,从 Spark 控制台查看
通过这种方式,我们可以在实时应用程序中利用 Spark 结构化流,并基于流数据获得基于 Spark SQL 的优化计算的优势。


 概述")