
在 SQL 被引入的 47 年中,它经历了许多数据库的诞生和消亡,也经历了许多数据处理方式的诞生和消亡。
以下为译文:
四十七年前,两位年轻的IBM研究人员在数据库上提出了一种新的语言,这是一种关系型语言,它奉行一切数据可以被声明性地操作和容易操作的思想。自Don Chamberlin和Ramond Boyce出版《SEQUEL:结构化英语查询语言》一书后的几年里,关系模型和SQL已经扩展并被大量的技术所采纳,如OLTP、OLAP、对象数据库、对象关系数据库,甚至NoSQL等等。SQL同时也启发了非关系数据库的查询语言设计:如SQL for Object-Database(用于对象数据库的SQL),SQL for Object-Relational(用于对象关系型数据库的SQL),SQL for XML、SQL for Spatial、SQL for Search、SQL for JSON、SQL for Timeseries、SQL for Streams等等。每个BI工具都使用各种各样的SQL与数据交互。实际上,SQL是最成功的第四代语言。
“SQL是一种只有它自己的力量才能超越它的神秘手段。”
——Lukas Eder正如Don最近所说的,SQL是基于关系代数的基础,目的是通过提供一个类似于英语的查询语言来更简单地实现以下目标:
SQL是一种只有它自己的力量才能超越它的神秘手段。”——Lukas Eder正如Don最近所说的,SQL是基于关系代数的基础,目的是通过提供一个类似于英语的查询语言来更简单地实现以下目标:
- 声明性的语言和流程(而不是程序性的)
- 使语言可组合以帮助轻松编写复杂的查询
- 和Edger F Codd开发的关系模型共同工作
虽然大数据试图为数据仓库扩展和替换关系型系统,但它们试图使用相同的SQL语言。Hive, Impala、Drill、BigSQL使用的语言都深受SQL启发,优化器和执行类似于SQL的MPP执行。他们还定期添加新的SQL功能。所有这些都发生在你能想到的每种类型的数据存储和模型上。SQL中数据存储格式、数据模型和查询处理的分离带来了显著的好处。
在SQL被引入的45年中,它经历了许多数据库的诞生和消亡,也经历了许多数据处理方式的诞生和消亡。支持NoSQL运动的一些人暗示SQL和SQL数据库不能将会消亡,即使是无意的。但SQL阵营已经迈步前进,Don Chamberlin最近说道:“当一种语言得到了普遍认可,以至于其他语言开始将自己定义为不是那种语言时,它必须做得非常好。”
另一方面,数据库只是转向了No-SQL。虽然目前对No-SQL的定义是“Not Only SQL”,但最初的想法是不使用SQL,而代之以其他语言和框架,如map-reduce。然而十年后,每个流行的NoSQL数据库都有了一个SQL变体:如Couchbase的N1QL,Cassandra的CQL,Elastic的ElasticSearch。你会说,“MongoDB没有SQL”。我会说,“眯眼想一想!你会看到一个非常简单的SQL实现。” 通过在MongoDB中使用一个简单的,有些程序化的,特别的设计,一些松散组合性的查询,优化以及许多创新都可以使用SQL完成。
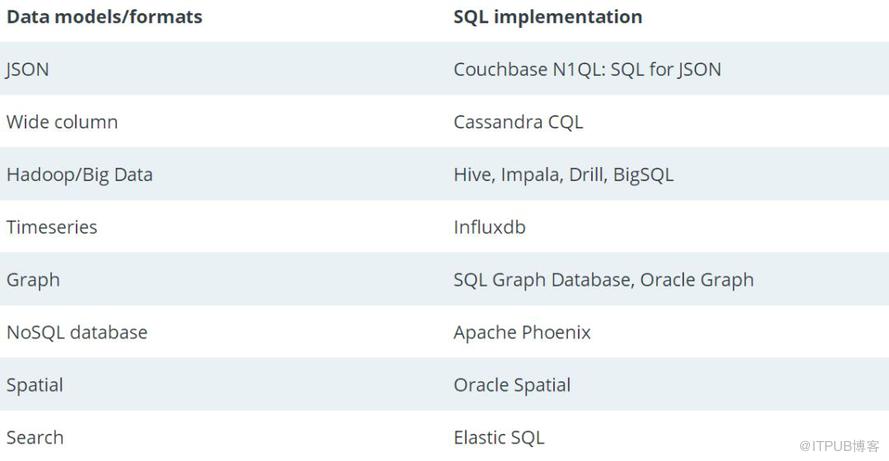
虽然关系模型非常成功,但是数据库支持各种数据模型:如JSON, Graph, XML, Timeseries, Spatial, Wide-column, Columnar, Document等等。大多数(如果不是全部)数据库都有自己的SQL版本。如N1Q1(SQL for Jason)、SQL/XML、SQL from InfluxDB、SQL/Spatial、CQL in Cassandra等等,甚至NoSQL数据库也实现了SQL和SQL启发的查询语言。即使在新的酷炫的“数据科学”世界中,SQL技能也是强烈推荐的。Lukas Eder在他的“must-see”谈话中阐述了这一点。有关他的谈话,请参见相关链接。
现在,NoSQL数据库相关的SQL项目要比SQL数据库的项目多。
SQL 为何会成功?
- 声明性:你只需要声明输出,查询引擎就会找出执行查询的最佳方式。优化器,特别是1979年Pat Selinger等人发明的基于成本的优化器,帮助持续地改进性能。这为每个新进入者提供了一个很高的标准。最近一篇关于Apache Hive的论文就是一个复杂性和完善涉及的例子为什么SQL如此成功?
- SQL不仅用于“查询”,还用于更新数据、执行事务。存储过程,UDF通过将过程语言与声明性SQL相结合来扩展访问范围。
- SQL具有可塑性。它已经多次标准化,每次都会添加一本功能齐全的书,一个充满语法的商店,以及一个充满关键词的词典。当然,并非所有的SQL都是相同的。即使是RDBMS上的传统SQL实现也不完全兼容,除非您小心地编写SQL使其兼容。通过所有这些,SQL的原始精神得以保留。SQL的一个进化的例子是SQL++。Don Chamberlin和Mike Carey教授讨论了支持复杂数据模型的需求,使用户和开发人员可以轻松访问JSON中的数据。Don写的书《SQL++ for SQL users:A Tutorial》介绍了SQL++的最新发展,SQL++这种语言是为灵活的JSON数据模型上的数据处理而设计的,它保持了与SQL的兼容。
- 就像它所借用的英语一样,SQL对新数据类型、访问方法和用例的新思想和扩展持开放态度。
- SQL与数据表示的独立性使其可以用于非关系数据:CSV, JSON和所有大数据格式。有些人把关系模型表示的刚性和SQL的刚性混为一谈。实际上,对于任何给定的Schema,SQL允许你对任何数据格式执行select-join-group-aggregate-project操作
评估SQL支持
既然SQL无处不在,那么你就需要在支持级别上进行尽职调查。
- 找出每个工作负载的特征和目标。例如,交互式应用程序,或交互式分析,或批量分析,或BI工作负载等等。
- 支持的声明反映了操作能力。
- 在表达式(标量、聚合、布尔值)、联接(内联、左联/右联/全联)、子查询、派生表、排序和分页(LIMIT / OFFSET)方面的语言能力。
- 索引:没有正确索引的SQL只是一个图灵机器原型。
- 优化器:查询重写,选择正确的访问路径,创建最佳执行路径是使得SQL语言成为成功的第4代语言的原因。有些具有基于规则的优化器,有些具有基于成本的优化器,而有些则两者都有。评估优化器的质量至关重要。典型的基准(TPC-C、TPC-DS、YCSB、YCSB-JSON)在这里对你没有帮助。
- 正如我们常说:“数据库有三个重要方面:性能、性能和性能”。测量工作负载的性能很重要。YCSB和扩展的YCSB-JSON将使评估更容易。
- SDK:丰富的SDK和语言支持,加快你的开发速度。
- BI工具支持:对于大型数据分析,通过标准数据库连接驱动程序来支持BI工具通常非常重要。
N1QL的创建者Gerald Sangudi曾经说过,SQL是成功的,因为它代表了数据处理的基本操作。SQL支持一组丰富的操作:select-join-nest-unnest-group-aggregate-having-window-order-paginate-set-ops。这是我们(或机器)在指定数据操作时的想法吗?虽然还有待观察,但像Python和Java这样的语言正在为数据的这些操作添加运算符。也许,其他人也会效仿。SQL已经进入了关系型数据库模型不曾涉足的领域。
可以毫不夸张地说:SQL已死,但SQL将永存!

