
前面几个章节我们使用到了 Lucene 的中文分词器 HanLPAnalyzer,它并不是 Lucene 自带的中文分词器。Lucene 确实自带了一些中文分词器,但是效果比较弱,在生产实践中多用第三方中文分词器。分词的效果直接影响到搜索的效果,比如默认的 HanLPAnalyser 对「北京大学」这个短语的处理是当成完整的一个词,搜索「北京」这个词汇就不一定能匹配到包含「北京大学」的文章。对语句的处理还需要过滤掉停用词,除掉诸于「的」、「他」、「是」等这样的辅助型词汇。如果是英文还需要注意消除时态对单词形式的影响,比如「drive」和「driven」、「take」和「taked」等。还有更加高级的领域例如同义词、近音词等处理同样也是分词器需要考虑的范畴。
Lucence 中的分词器包含两个部分,分别是切词器 Tokenizer 和过滤器 TokenFilter。切词器顾名思义负责切,将一个句子切成一连串单词流,切词器输出的单词流是过滤器的输入,它负责去掉无用的词汇比如停用词,过滤器还可以是词汇转换,比如大小写转换,过滤器还可以生成新词汇,比如同义词。抽象类 Tokenizer 和 TokenFilter 都继承自 TokenStream 抽象类,Tokenizer 负责将文本(Reader)转成单词流,TokenFilter 负责将输入单词流转成另一个单词流。

有了上图中的流水线构造出的最终的 TokenStream,Lucene 就会将输入的文章灌入其中得到最终的单词流,然后对单词流中的每个单词建立 Key 到 PostingList 的映射以形成倒排索引。这里的单词流串联的是带有 Payload 的单词,每个单词都会有一些附加属性,诸于单词的文本、单词在文档中的偏移量、单词在单词流中的位置等。
而 Lucene 的分词器 Analyzer 就是上述流水线的工厂类,由它负责制造整条流水线。Lucene 内置了很多种不同功用的分词器,每种分词器都会生产出不同的流水线。
下面我们使用 Lucene 提供的标准切词器观察分词效果,标准切词器是一个基于空格的切词器。
var tokenizer = new StandardTokenizer();
tokenizer.setReader(new StringReader(“Dog eat apple and died”));
tokenizer.reset();
var termAttr = tokenizer.addAttribute(CharTermAttribute.class);
var offsetAttr = tokenizer.addAttribute(OffsetAttribute.class);
var positionIncrAttr = tokenizer.addAttribute(PositionIncrementAttribute.class);
while(tokenizer.incrementToken()) {
System.out.printf(“%s offset=%d,%d position_incr=%d\n”, termAttr.toString(), offsetAttr.startOffset(), offsetAttr.endOffset(), positionIncrAttr.getPositionIncrement());
}
————-
Dog offset=0,3 position_incr=1
eat offset=4,7 position_incr=1
apple offset=8,13 position_incr=1
and offset=14,17 position_incr=1
died offset=18,22 position_inc=1
incrementToken() 表示往前走一个词,单词位置+1,到了文本末尾它就会返回 false。termAttr、offsetAttr 和 positionIncrAttr 都是当前单词位置上的附加属性,分别是单词的文本、字符偏移量的开始和结束位置和单词的位置间隔(一般都是 1),这三个属性就停在那里「守株待兔、雁过拔毛」,来一个单词,就立即抽取它的属性值。其中 positionIncrement 代表单词的位置间隔,通常连续两个单词之间的间隔都是 1。

下面我们再加上过滤器,将停用词过滤掉,同时再加上大小写转换器,将大写字母转成小写字母。从代码形式上过滤器和切词器会通过构造器串联起来形成一条流水线。
var tokenizer = new StandardTokenizer();
tokenizer.setReader(new StringReader("Dog eat apple and died"));
var stopFilter = new StopFilter(tokenizer, StopFilter.makeStopSet("and"));
var lowercaseFilter = new LowerCaseFilter(stopFilter);
lowercaseFilter.reset();
var termAttr = lowercaseFilter.addAttribute(CharTermAttribute.class);
var offsetAttr = lowercaseFilter.addAttribute(OffsetAttribute.class);
var positionIncrAttr = lowercaseFilter.addAttribute(PositionIncrementAttribute.class);
while(lowercaseFilter.incrementToken()) {
System.out.printf("%s offset=%d,%d position_incr=%d\n", termAttr.toString(), offsetAttr.startOffset(), offsetAttr.endOffset(), positionIncrAttr.getPositionIncrement());
}
-------------
dog offset=0,3 position_incr=1
eat offset=4,7 position_incr=1
apple offset=8,13 position_incr=1
died offset=18,22 position_incr=2注意和前面的例子输出进行对比,所有的单词 offset 值并没有发生变化,因为它表示的是在原文中的字符偏移量,而 position_incr 却发生了变化,因为它代表的是单词序列的位置。当停用词被过滤后,单词序列发生了变化,相应的位置也会跟着改变。

下面我们来编写分词器 Analyzer 将上述切词器、过滤器进行打包封装
var analyzer = new Analyzer(){
@Override
protected TokenStreamComponents createComponents(String fieldName) {
var tokenizer = new StandardTokenizer();
var stopFilter = new StopFilter(tokenizer, StopFilter.makeStopSet("and"));
var lowercaseFilter = new LowerCaseFilter(stopFilter);
return new TokenStreamComponents(tokenizer, lowercaseFilter);
}
};
var stream = analyzer.tokenStream("title", "dog eat apple and died");
stream.reset();
var termAttr = stream.addAttribute(CharTermAttribute.class);
var offsetAttr = stream.addAttribute(OffsetAttribute.class);
var positionIncrAttr = stream.addAttribute(PositionIncrementAttribute.class);
while(stream.incrementToken()) {
System.out.printf("%s offset=%d,%d position_incr=%d\n", termAttr.toString(), offsetAttr.startOffset(), offsetAttr.endOffset(), positionIncrAttr.getPositionIncrement());
}
----------
dog offset=0,3 position_incr=1
eat offset=4,7 position_incr=1
apple offset=8,13 position_incr=1
died offset=18,22 position_incr=2var analyzer = new Analyzer(){ @Override protected TokenStreamComponents createComponents(String fieldName) { var tokenizer = new StandardTokenizer(); var stopFilter = new StopFilter(tokenizer, StopFilter.makeStopSet("and")); var lowercaseFilter = new LowerCaseFilter(stopFilter); return new TokenStreamComponents(tokenizer, lowercaseFilter); }};var stream = analyzer.tokenStream("title", "dog eat apple and died");stream.reset();var termAttr = stream.addAttribute(CharTermAttribute.class);var offsetAttr = stream.addAttribute(OffsetAttribute.class);var positionIncrAttr = stream.addAttribute(PositionIncrementAttribute.class);while(stream.incrementToken()) { System.out.printf("%s offset=%d,%d position_incr=%d\n", termAttr.toString(), offsetAttr.startOffset(), offsetAttr.endOffset(), positionIncrAttr.getPositionIncrement());}----------dog offset=0,3 position_incr=1eat offset=4,7 position_incr=1apple offset=8,13 position_incr=1died offset=18,22 position_incr=2注意到 analyzer 的 createComponents 有一个 fieldName 参数,这意味着分析器支持为不同的字段定制不同的流水线,这里的 Component 含义就是流水线。analyzer 之所以将流水线的制造过程抽象出来就是为了考虑对象的复用,流水线可以很复杂,涉及到非常繁多的对象构建,analyzer 内部会每个线程共用同一条流水线。当单个流水线对象处理一条又一条文本内容时,需要通过 reset() 方法来重置流水线的状态避免前一条文本内容的状态遗留给后面的内容。
同义词过滤器 SynonymGraphFilter
有一个面试常见的题目就是 Lucene 的同义词搜索是如何实现的?它的实现方式就是通过过滤器对单词流进行泛化扩充,将一个单词变成多个单词,再插入到倒排索引中,在查询阶段也对查询关键词进行同义扩展成多个词汇再合并查询。Lucene 提供了同义词过滤器的默认实现 SynonymFilter,如今在新的版本中它已经被 SynonymGraphFilter 替换,提供了更加精准的实现。同停用词过滤器一样,使用它需要用户自己添加一个同义词表。下面的代码给词汇 dog 增加了同义词 puppy 和 pup。
var analyzer = new Analyzer(){
@Override
protected TokenStreamComponents createComponents(String fieldName) {
var tokenizer = new StandardTokenizer();
var lowercaseFilter = new LowerCaseFilter(tokenizer);
var builder = new SynonymMap.Builder();
builder.add(new CharsRef("dog"), new CharsRef("puppy"), true);
builder.add(new CharsRef("dog"), new CharsRef("pup"), true);
SynonymMap synonymMap = null;
try {
synonymMap = builder.build();
} catch (IOException ignored) {
}
assert synonymMap != null;
var synonymFilter = new SynonymGraphFilter(lowercaseFilter, synonymMap, true);
var stopFilter = new StopFilter(synonymFilter, StopFilter.makeStopSet("and"));
return new TokenStreamComponents(tokenizer, stopFilter);
}
};
var stream = analyzer.tokenStream("title", "dog eat apple and died");
stream.reset();
var termAttr = stream.addAttribute(CharTermAttribute.class);
var offsetAttr = stream.addAttribute(OffsetAttribute.class);
var positionIncrAttr = stream.addAttribute(PositionIncrementAttribute.class);
while(stream.incrementToken()) {
System.out.printf("%s offset=%d,%d position_incr=%d\n", termAttr.toString(), offsetAttr.startOffset(), offsetAttr.endOffset(), positionIncrAttr.getPositionIncrement());
}
-----------
puppy offset=0,3 position_incr=1
pup offset=0,3 position_incr=0
dog offset=0,3 position_incr=0
eat offset=4,7 position_incr=1
apple offset=8,13 position_incr=1
died offset=18,22 position_incr=2从结果中我们能看出几个问题,第一个是 puppy 的长度是 5,但是 offset 还是原词 dog 的 offset,长度是 3。这意味着 TokenStream 中词汇的长度和 offset 不一定会 match。第二个问题是 puppy 和 dog 、pup 是同义词,但是 position_incr 很明显不一样,只有第一个词汇的增量是 1,其它同义词汇都是原地打转。至于为什么 puppy 在单词流中排在第一个位置而不是 dog,这个实际上是不确定的,它也不会对后续的搜索结果产生任何影响。
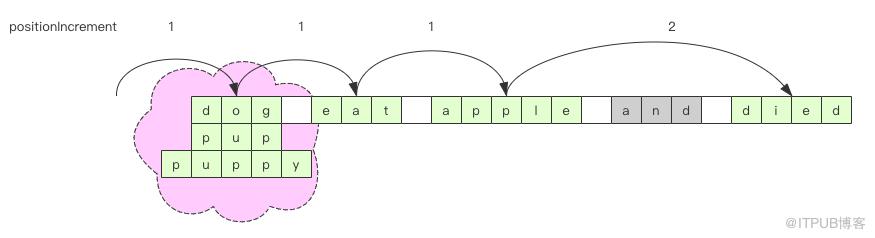
位置对短语查询 PhraseQuery 的影响
在上一节我们介绍了 Lucene 自带的短语查询功能,它有一个重要的参数 slop,代表着短语之间的最大位置间隔。下面我们来看看同义词对短语查询会产生怎样的影响。下面的代码将会用到上面构造的 analyzer 分析器实例,在构建索引和查询阶段都会用到。
var directory = new RAMDirectory();
var config = new IndexWriterConfig(analyzer);
var indexWriter = new IndexWriter(directory, config);
var doc = new Document();
doc.add(new TextField("title", "dog eat apple and died", Field.Store.YES));
indexWriter.addDocument(doc);
doc = new Document();
doc.add(new TextField("title", "puppy eat apple and died", Field.Store.YES));
indexWriter.addDocument(doc);
doc = new Document();
doc.add(new TextField("title", "pup eat apple and died", Field.Store.YES));
indexWriter.addDocument(doc);
indexWriter.close();
var reader = DirectoryReader.open(directory);
var searcher = new IndexSearcher(reader);
var parser = new QueryParser("title", analyzer);
var query = parser.parse("\"dog eat\"~0");
System.out.println(query);
var hits = searcher.search(query, 10).scoreDocs;
for (var hit : hits) {
doc = searcher.doc(hit.doc);
System.out.printf("%.2f => %s\n", hit.score, doc.get("title"));
}
reader.close();
directory.close();
------------
title:"(puppy pup dog) eat"
1.51 => dog eat apple and died
0.99 => puppy eat apple and died
0.99 => pup eat apple and died从代码中可以看到 QueryParser 会将查询短语进行同义扩展变成 OR 表达式(puppy OR pup OR dog),三个文档都被正确的匹配出来了,只不过原词的得分会偏高一些。另外代码中我们使用了 RAMDirectory,这个是用来进行测试的基于内存的虚拟文件目录,使用起来比较方便不需要指定文件路径拿来即用。这个类在 Lucene 的新版本中已经被置为 deprecated,被 MMapDirectory 所取代。MMapDirectory 使用起来和 FSDirectory 差不多,需要指定文件路径。