
如果你一直关注最近围绕微服务架构模式的讨论,你也许就听过这个建议:“你需要创建一个事件驱动架构,来有效地解耦你的(微)服务”。
这个想法受到领域驱动设计(Domain-Driven Design,DDD)社区的支持。DDD社区为此提供了利用领域事件的具体细节,并展示了他们是如何改变我们看待系统的方式。
尽管我们拥护面向事件的架构,但是还需要问问自己,如果没有深入反思就使用事件驱动架构,会遇到哪些风险。为了解答这个问题,我们重新审视了以下三个基本假设:
- 事件减少耦合
- 需要避免集中控制
- 工作流引擎是令人痛苦的(这也许看起来毫无关联,但是我们稍后会展示其关联关系)
我们之前已经在muCon London 2017(幻灯片和录像)、O'Reilly Software Architecture London(幻灯片和录像)以及KanDDDinsky(幻灯片和录像)上发表了讲话,展示了我们重新审视的结果。
我们的讲话基于现实生活中的各种不同项目的经历,但是使用了一个虚构的零售例子,这个例子受到(一次见面会上分享的)Zlando订单处理流程的启发。
假设我们有四个绑定的上下文,产生4种专用的服务(微服务、独立的系统或者一些其它形式的服务):
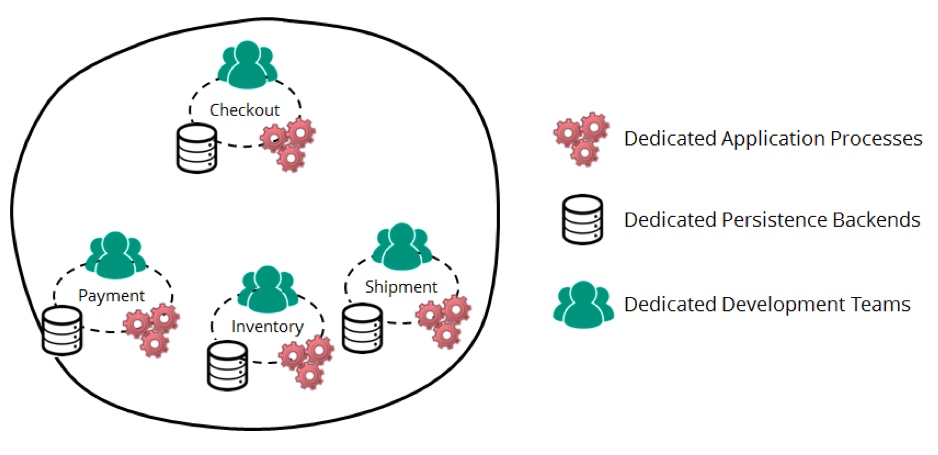 

如何利用事件来解耦服务
我们假设,如果一项产品有现货而且可以马上交货,结账服务应该给用户反馈。结账服务可以使用请求/响应的方式来向库存服务询问存货的数量,但是这样就将结账服务与库存服务(在可用性、响应时间等方面)耦合起来了。
一个替代方案是,库存服务将存货数量的任何变更作为一个广播事件发布,让整个系统都知道这些变更。结账服务可以监听这些事件并内部保存当前的存货数量,然后对相关的问题进行本地应答。这个信息是一份拷贝,可能不是绝对一致的。然而,在分布式系统中,某种程度的最终一致性是可以接受的,也是一种必要的折衷。

另外一个用例是在非核心功能中插入钩子,例如切面问题(cross-cutting concerns,在面向切面软件开发中,是指程序中影响其它相关业务的切面)。例如,你想要向客户发送关于订单的重要通知。通知服务可能是用一种完全自治的方式实现的,为客户存储通知偏好和联系人数据。它能在发生特定事件(例如收到付款、商品发货)时向客户发送邮件,而不需要在其他服务中做任何更改。这令事件驱动架构(event-driven architectures,EDA)非常灵活,并且增加新服务或者扩展现有的服务变得非常简单。
点到点事件链的风险
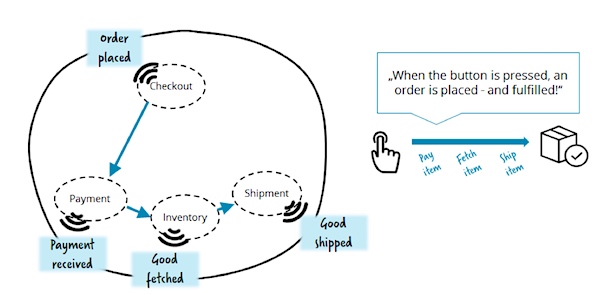
一旦团队开始使用事件驱动架构,他们通常会对事件着迷,因为事件提供了惊人的解耦能力,那么让我们为所有业务都使用事件驱动架构吧!当你实现点到点的事件流,就像通过点到点的事件链实现订单流程,问题就会开始浮现。假设一个相当小的流程,它的实现方式是,服务链中的下游服务总会知道它需要在什么时候做什么事情。
这样是没有问题的。然而,问题是没有任何一个服务清楚全局情况,令这个流程难以理解,更重要的是,难以改变。另外,你要记住,现实情况下的流程不会是那么简单的,通常会涉及更多的服务。我们曾经见到过一些微服务的应用导致出现这种情况:一个包含许多服务的复杂系统做了某些事情,但是没有人真正地清楚具体做了什么以及怎么做的。
现在,想想我们如何实现,在我们进行支付之前发送一个简单的数量变更请求来获取商品存量信息:
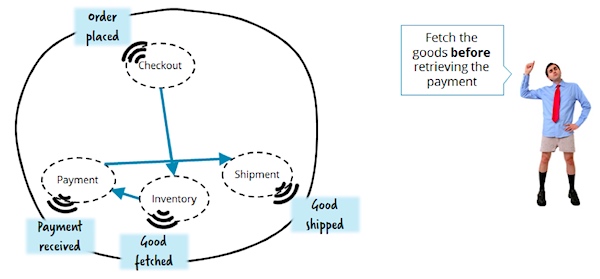 

你不得不为步骤序列中的一个简单的变更做出调整并重新部署一些服务。这通常是使用微服务的反面模式,因为这种架构模式的核心设计原则是努力争取低耦合和服务自治。因此,我们建议你在使用事件来实现对到点服务流之前要反复思考,尤其是可能会有相当大的复杂性的时候。
命令,但不需要集中控制
一种更靠谱的处理这种流程的解决方案是用一个专门的服务来实现它。这个服务可以作为一个协调者,向其它服务发送命令,例如,发起支付。这通常是一种更自然的方案,在这种情况下,如果支付服务通过订阅大量能够触发支付检索的业务事件来了解其所有消费者,我们通常不认为这是一种好的设计。以下的方案避免了这种耦合,可以认为是一种编排方案:“订单服务编排支付服务、库存服务和运输服务,来满足客户业务需求。”
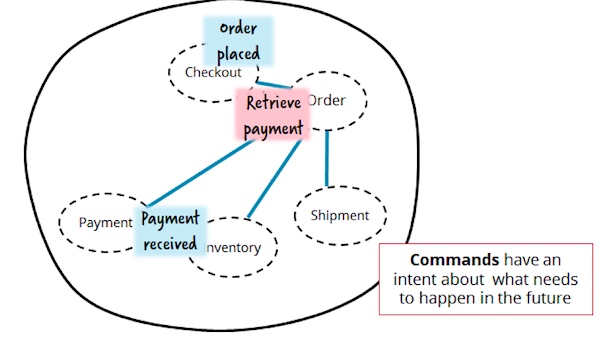 

然而,当我们一提到编排,一些人会想到“神奇的”企业服务总线(Enterprise Service Buses,ESB)或者集中化的业务流程建模(Business Process Modelling,BPM)解决方案。在过去关于这些工具有许多不好的经历,因为这通常意味着,你因为要使用一些太复杂的专业工具而不得不放弃易测性和自动化部署。James Lewis和Martin Fowler建议更好地使用“智能端点和哑管道”,奠定了微服务架构的一些基础。
然而,上面的图片没有建议智能端点。编排服务将订单服务作为一等公民来处理,并作为一个专门的服务来实现。像这样的服务可以用你喜欢的任何方式和你喜欢的任何技术栈来实现。这个流程现在非常简单,你有一个专门的地方可以在其中了解流程,并且可以通过只更改一个服务来更改整个流程。
Sam Newman在他的《Building Microservices》一书中描述了这种订单编排服务的另外一种风险:随着时间的推移,这个服务会引入所有的业务逻辑而发展成一个“上帝服务”,而其它服务会退化成“贫血的“服务,甚至在更坏的情况下变成CRUD那样的“实体”服务。之所以会发生这样的事情,是因为我们有时更偏好命令而不是事件吗?或者是因为服务编排?并不是。让我们快速复习下Martin Fowler提出的“智能端点”概念。什么构成了一个智能端点?这大概与良好的API设计有关。对于支付服务,你可以设计一个高效的粗粒度的API,这个API可以按照检索支付命令执行,并且可以发送付款收到事件或者付款失败事件。付款处理的中间状态,例如客户信誉值或信用卡付款失败不会被暴露出来。在这种情况下,服务不会变得贫血,因为它是在其它环境下被编排的(或者更简单地说,“被使用”)。
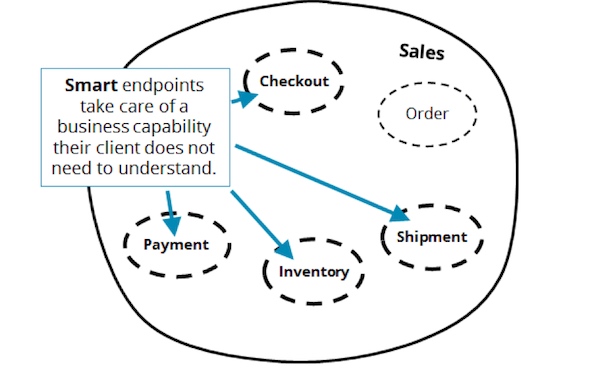 

考虑服务潜在的长期运行的性质
为了设计智能端点并向你的客户提供一个有价值的API,你必须认清,许多服务都存在长期运行的可能性,因为它们需要解决各种场景的业务难题。假设,在信用卡过期的情况下,我们给客户一个机会去更新这个信息(从GitHub获得的启发,GitHub允许你在付款失败需要关闭账户之前有2周的缓冲期)。如果支付服务完全不关心这些等待用户的细节,这将会把这种需求的责任推给它的使用者——订单服务。然而,将这种职责保留在支付服务中是更加简洁的做法,也更符合领域驱动设计中绑定上下文的理念。等待客户提供新的信用卡信息,意味着付款操作可以继续被恢复或者失败。因此,支付API变得更加清晰,服务也变得更容易使用。然而,目前在某些情况下,我们在得到一个业务响应之前可能需要等待2周时间。这就是我们所谓的“长期运行的”业务流。
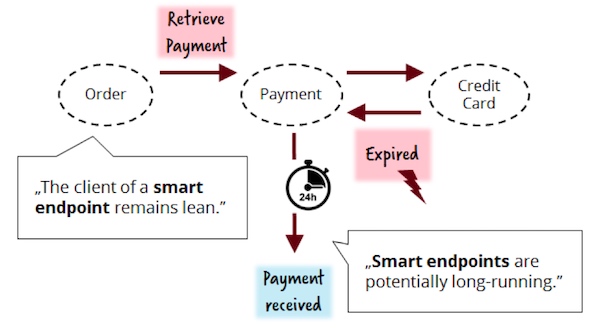 

为长期运行的服务实现状态持久化
长期运行的服务需要以某种方式保存持久化状态。在我们的例子中,我们不仅需要记住付款操作还没有恢复,还需要记住订单也还没有完成并且处于等待支付的状态。这些状态需要在系统重启后仍能够保留。当然,处理状态持久化并不是一个新的问题,对此有两种典型的解决方案:
实现你自己的持久化机制,例如Entity、Persistent Actor等。问问你自己,你是否曾经建过一个订单表,表中有一列叫做状态?那就是你要的东西。
利用状态机或者工作流引擎。市面上有不少工具和框架,其中一些已经非常成熟。最近在这个领域也有一些创新,例如Netflix和Uber正在开发他们自己的开源项目。

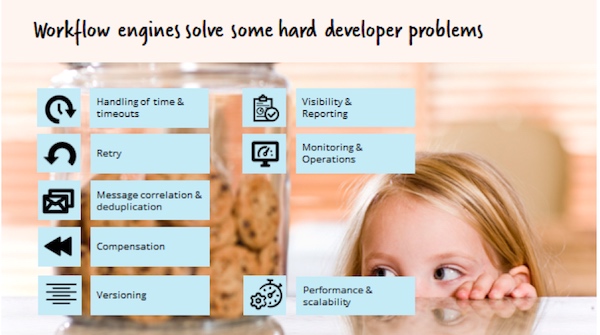
根据我们的经验,实现你自己的状态持久化机制通常会导致出现一种只适合你自己的业务而不能通用的状态机。这是由于,你会经常遇到后续的需求,例如超时处理(“嗨,让我们给这个游戏加个进度条”)、可视化和生成报告(“为什么业务人员不能直接使用SQL去查询信息?”),或者如果发生错误时监控操作的需求。
实现自己的状态机之所以如此普遍,不仅仅是因为“非我所创”综合症(Not-Invented-Here syndrome,是指在社会、公司或组织中的一种文化,人们不采用某种产品或知识成果,不是出于技术或法律等因素,而只是由于它们源自其它地方),也是因为市场上围绕工作流和过时的BPM工具的一些概念。许多开发者对于那些通常定位为“零代码”的工具有非常痛苦的经历。这些工具被销售给业务部门,伴随着不需要开发者参与的想法,但它其实并没有如预期的那样。相反,这些工具被转交给IT部门并与那里的系统“格格不入”。这些工具通常都是非常重量级的和负责专门业务的,而开发人员要面对我们所谓的“死亡属性面板”。
轻量级的状态机和工作流引擎
轻量级的灵活的业务流程引擎确实存在,并且可以像其它库一样被使用,只需要几行代码就可以了。它们没有将自己定位为“零代码”,而是定位为开发者工具箱中的一种工具。它们解决了比较难的状态机问题,并且经常在很多项目的早期就可以看到成果。

这些工具允许你使用ISO标准的BPMN来以绘图的形式定义流程,也可以使用其它流程语言来定义流程。这些流程语言通常基于JSON、YAML或者依赖DSL(领域专用语言)的语言(例如Java或者Golang)。一个重要的方面是,流程是高效地通过源代码定义的,因此它们可以直接被执行。执行意味着,状态机知道如何从一种状态转变到另外一种状态。
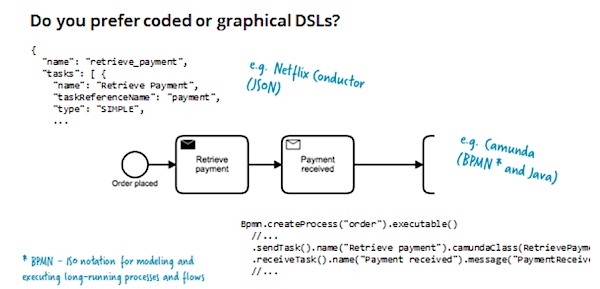 

像BPMN那样成熟的流程语言提供许多相当有用的概念,例如,处理时间和超时,或者复杂的业务事务。由于有这么多项目使用BPMN,我们知道我们可以用它解决相当复杂的需求。
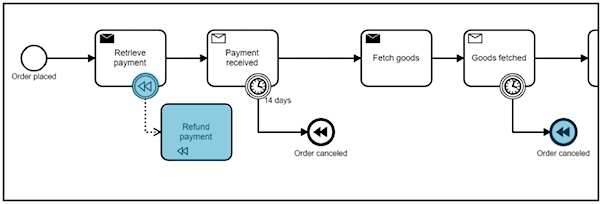 

在上面的示例中,工作流实例需要在一个特定的超时事件触发前等待一个商品收货事件。如果发生了超时,业务事务就需要补偿,意味着所有的补偿活动都要被执行,而且在这种情况下付款会被退还给客户。状态机会跟踪已经执行过的活动,因此能够触发所有必要的补偿动作。这允许状态机来协调业务事务,其基本理念也被称为Saga模式。
使用图形符号来定义这种流程也被加入到实时文档的想法中。文档与你运行中的系统保持一致,在这种方式下,它不会与实际的系统行为不一致。有些工具为包括长期运行行为等特定场景的单元测试提供特殊支持。例如,在Camunda中,每一次测试运行都会生成一个将执行场景高亮显示的HTML输出结果,而这个结果可以很容易地插入到普通的持续集成报告中。通过这种方式,图形化的模型带来了更多的价值:
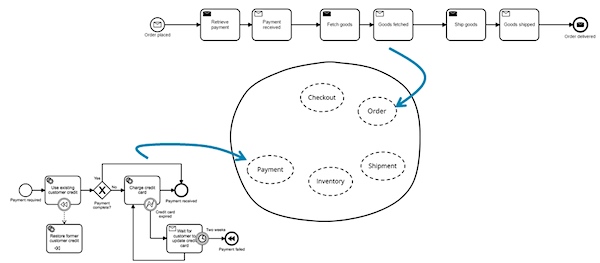 

工作流在服务边界内是有效的
非常重要的一个概念是,使用工作流框架和工具是一个由每个服务团队做出的分散的决定。状态机从服务外部应该是不可见的。不需要任何集中的工作流工具,状态机应该仅仅是一个库,用它来让你的某些服务的长期运行行为变得更加容易。
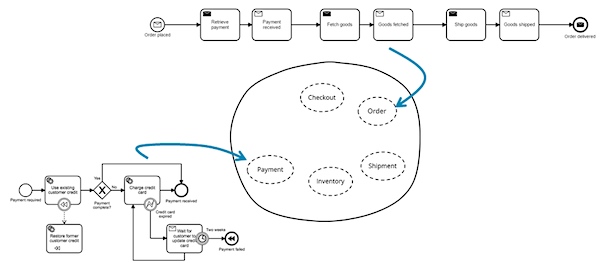 

对此的另外一种看法是,这种工作流引擎是你的服务逻辑的一部分。基于你选择的工具,它能够嵌入到你的应用程序进程中运行(例如,使用Java、Spring和Camunda),使用简单的语言客户端(例如,使用Java或者Go和Zeebe)作为一个独立的进程,或者被一个REST API使用(例如,使用Camunda或者Netflix Conductor)。使用这些基础设施,将服务从需要自己实现状态处理的负担中解放出来,可以专注于业务逻辑。你能够设计出好的服务API和真正的智能端点,因为你能够非常容易地让服务具备长期运行的可能性。
代码示例
为了确保我们不是仅仅在理论上讨论这些概念,我们开发了一个小型的样本应用,用实际例子展示所有这些概念。这些代码可以在GitHub上获取到。我们只用了Java和一些开源组件(Spring Boot、Camunda和Apache Kafka),因此可以非常容易地用它来进行探索和实验。

综上所述
像业务工作流建模这样复杂的话题,我们只能通过提出一些常见的假设来触及这个话题的表面。下面是一些重点:
- 事件能够减少耦合吗?有时候会!老实说,事件对于分散的数据管理、生成可读模型或者应对切面问题是非常棒的。然而,你最好不要实现复杂的点到点的事件链。如果你冒险这么做了,那么就要确保你是通过发送命令和编排其它服务的方式实现的。
- 需要避免集中化控制吗?只有某些情况下需要。我们同意,集中管理的ESB不适合微服务架构。智能端点和哑管道更可取。然而,不要忘记,所有重要的业务功能都需要一个中枢。如果你使用智能端点,就不会使一个服务变成臃肿的上帝服务。智能端点经常意味着,你会有许多潜在的长期运行的服务,它们内部处理所有它们负责的业务问题。
- 工作流引擎是令人痛苦的吗?只有其中一些是这样的!过去,BPM和工作流引擎是被过度炒作的概念,它们是供应商驱动的,因此市场上有许多可怕的“零代码”工具。然而,轻量级的易用的框架也是存在的,并且它们大部分是开源的。它们可以以一种分散的形式运行,帮助开发者解决一些棘手的问题。不要花时间去写你自己的状态机,利用现有的工具。