
本文通过实战跑分来展示HBase2.x的写入性能
首先,简单介绍一下我们的测试环境:集群由5个节点组成,每个节点有12块800GB的SSD盘、24核CPU、128GB内存;集群采用HBase和HDFS混布方式,也就是同一个节点既部署RegionServer进程,又部署DataNode进程,这样其实可以保证更好的写入性能,毕竟至少写一副本在本地。关于软件版本,我们使用的HBase2.1.2版本以及HDFS 2.6.0版本,Java使用OpenJDK1.8.0_202。
对每一个RegionServer进程,我们正常的线上配置是50GB堆内内存和50GB堆外内存(RS合计占用100GB内存),其中堆内内存主要用于Memstore(~36GB),堆外内存主要用于BucketCache(~36GB)。这里,我们为了保证尽量跟线上配置一样,虽然现在是100%写入的测试场景,我们还是保留了50GB的堆外内存给BucketCache。在搭建好集群后,我们提前用YCSB压入了100亿行数据,每行数据占用100字节。注意,压入数据时,采用BufferMutator的方式批量写入,单机吞吐可以达到令人恐怖的20万QPS,所以这个过程是非常快的。
>>>>正常写入性能结果
接着我们开始测试正常的单行Put(设置autoflush=true)延迟了。我们在100亿行数据集规模的基础上,用YCSB持续写入数据到HBase集群,将YCSB的性能数据制作成如下监控图:
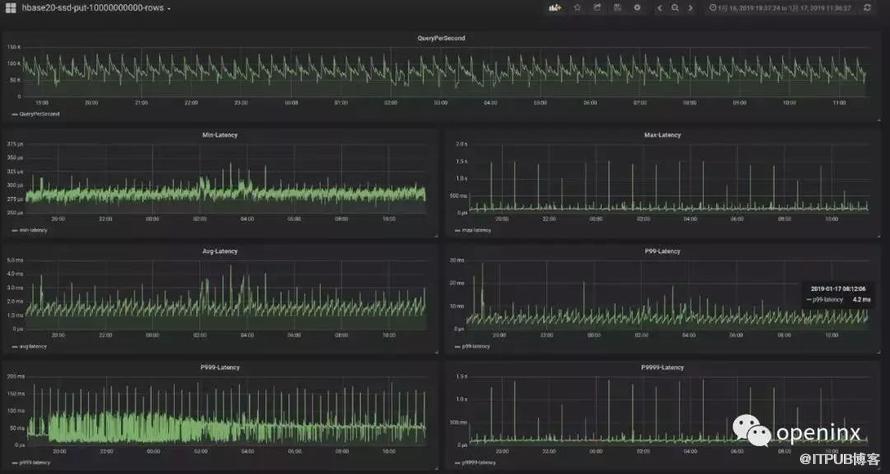
我们可以看到5个节点的总QPS在10w/s左右,单机QPS在2w+/s左右,avgLatency<4ms,P99-Latency<20ms。从基本面上看,这个数据还是很不错的。 但是,图中我们也能发现一些非常明显的问题:
1.QPS曲线呈现出明显的高峰和低谷,而且高峰和低谷是周期性出现的,大概15min出现一次高峰,对应的平均延迟(avg-Latency)也出现相应的周期性。这种不稳定的吞吐和延迟表现,对业务是非常不友好的,因为在低谷时期业务的QPS将受到极大的限制。
2.有时会出现大量P999为150ms的请求,P999曲线毛刺非常突出,而且毛刺点比平均的P999延迟要高100ms,这是一个非常令人困惑的数据。
3.P9999延迟出现部分超过1s的毛刺点。
>>>>优化毛刺
我们来分析上述几个问题的原因。首先,我们找了几个QPS低谷的时间点,去RegionServer的日志中看了下,确认低谷时间点基本上是 Memstore做Flush的时间点 。另外,确认P999毛刺时间点也是Flush的时间点。由此,推断出可能的几个原因有:
1.在测试集群中,每个节点的Region数以及各Region数据写入量都非常均衡。这样可能造成的一个问题就是,某一个时间点所有的Region几乎同时进入Flush状态,造成短期内磁盘有巨大的写入压力,最终吞吐下降,延迟上升。
2.MemStore Flush的过程,分成两步:第一步加写锁,将Memstore切换成snapshot状态,释放写锁;第二步,将snapshot数据异步的刷新成HFile文件。其中第一步持有写锁的过程中,是会阻塞当前写入的,第二步已经释放了写锁,所以刷新相当于是异步的,不会阻塞当前的写入请求。如果在第一步持有写锁过程中,有任何耗时操作,都会造成延迟飙升。
针对问题1在真实的线上集群其实不太可能发生,因为线上不可能做到绝对均衡,Flush必然是错峰出现。另外,即使绝对均衡,也可以采用限流的方式来控制Flush的写入速率,进而控制延迟。这个问题我们暂时可以放一放。针对问题2,我们尝试加了点日志,打印出每次Flush时RegionServer持有写锁的时长。发现一些如下日志: “–> Memstore snapshotting cost: 146ms”
这说明在Memstore snapshot过程中,确实有一些长耗时的操作。在进一步核对代码之后,我们发现一个如下存在问题的栈:
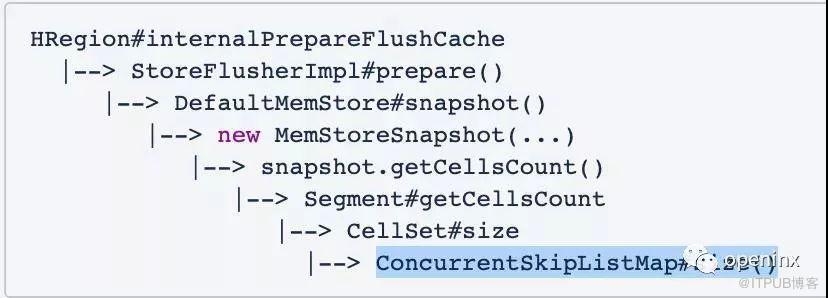
换句话说,在Memstore Snapshot中调用了一次ConcurrentSkipListMap#size()接口,而这个接口的时间复杂度是O(N)的。也就是说,如果有256MB的Memstore,那么这个size()接口会逐个扫描Memstore中的KV,最终统计得出Map中元素个数。ConcurrentSkipListMap为什么要这么实现呢?因为ConcurrentSkipListMap为了保证更好的写入并发性,不会在更新删除Map时维护一个线程安全的size变量,所以只能实时的统计Map元素个数。
这是一个潜藏在HBase代码仓库中很长时间的一个bug,从0.98一直到现在的2.0,甚至3.0,都没有用户发现这个bug。更多详情可以参考HBASE-21738。
其实,找到了问题之后,修改起来也就很简单,只需要把这个耗时的size()操作去掉,或者用其他的方式来替换即可。 我们已经在各分支最新版本中修复了这个bug,建议对性能有更高追求的用户升级。当然,对此我们也做了进一步的性能测试:
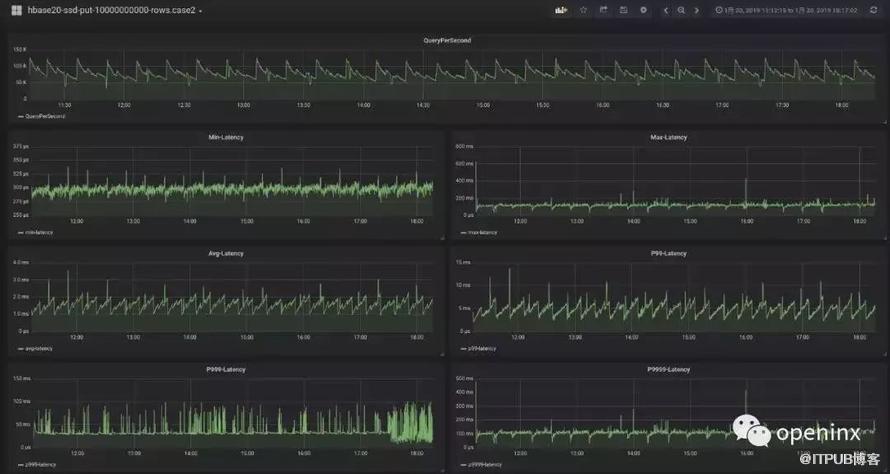
从图中看出,至少我们把P999的延迟控制在了100ms以内,另外,我们也可以很容易发现P9999的毛刺也从之前的1000ms下降到200ms~500ms左右。这说明,上述fix对解决毛刺问题还是很有效果的。
>>>>采用In-Memory Compaction进一步优化毛刺
但事实上,就目前的情况来说,我们仍然觉得P999~100ms不够好,其实大部分的P999是小于40ms的,但由于毛刺的问题,还是把P999拉到了100ms。进一步分析日志之后,我们发现此时G1 GC的STW是影响P999最大的因素,因为毛刺点都是GC STW的时间点,而且STW的耗时正好是100ms左右。
于是,我们考虑采用社区HBase 2.0引入的In-memory compaction功能来优化集群的写性能。这个功能的本质优势在于,把256MB的Memstore划分成多个2MB大小的小有序集合,这些集合中有一个是Mutable的集合,其他的都是Immutable的集合。每次写入都先写Mutable的集合,等Mutable集合占用字节超过2MB之后,就把它切换成Immutable的集合,再新开一个Mutable集合供写入。Immutable的集合由于其不可变性,可以直接用有序数组替换掉ConcurrentSkipListMap,节省大量heap消耗,进一步控制GC延迟。甚至更进一步,我们可以把MSLAB的内存池分配到offheap内。从此,整个Memstore几乎没有堆内的内存占用。理论上,这个feature的性能表现将非常强劲,我们做个测试来验证一下。
测试环境跟之前一样,不同的是我们会将Memstore配置为CompactingMemstore。注意,目前我们的MSLAB仍然是放在heap上的(若想把MSLAB为offheap,需要设置hbase.regionserver.offheap.global.memstore.size=36864,相当于把36GB的堆外内存给MSLAB)。
RegionServer的核心配置如下:
hbase.hregion.memstore.block.multiplier=5
hbase.hregion.memstore.flush.size=268435456
hbase.regionserver.global.memstore.size=0.4
hbase.regionserver.global.memstore.size.lower.limit=0.625
hbase.hregion.compacting.memstore.type=BASIC最终,我们得到的In-memory compaction测试结果如下:
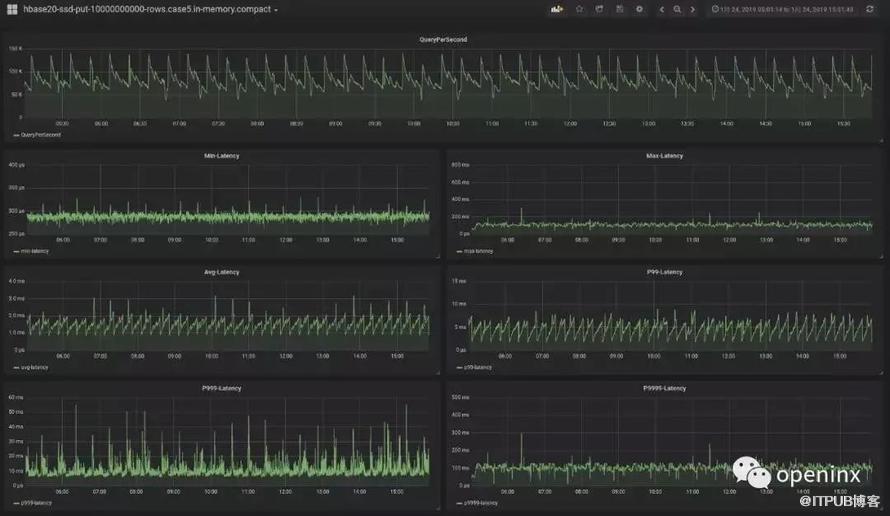
从图中可以非常明显的看出,P999延迟控制在令人惊讶的50ms以内,同时P9999控制在100ms左右,远低于之前的200ms~500ms。与此同时,吞吐跟平均延迟几乎没有任何损耗。如果使用堆外的CompactingMemstore,理论上毛刺会控制的更加严格,但有可能稍微拉升平均延迟。这里我没有再提供进一步的详细测试结果,感兴趣的朋友可以尝试一下。
>>>>总结
社区HBase2.1.2版本的写入延迟和吞吐表现都非常出色,但是某些场景下容易出现较高的毛刺。经过HBASE-21738优化之后,我们已经能很好地把P999延迟控制在100ms左右。这中间大部分时间点的P999<40ms,少数时间点因为GC STW拉高了P999的表现。接着,我们采用堆内的In-Memory Compaction优化之后,P999已经能控制在满意的50ms以内,甚至P9999可以控制在100ms以内。从这些点上来说,HBase2.1.3和HBase2.2.0版本已经是性能非常强悍的版本。