
1. 背景
在进入正题之前,这里先提出一个问题,如何在多线程中去对一个数字进行+1操作?这个问题非常简单,哪怕是Java的初学者都能回答上来,使用AtomicXXX,比如有一个int类型的自加,那么你可以使用AtomicInteger 代替int类型进行自加。
AtomicInteger atomicInteger = new AtomicInteger();
atomicInteger.addAndGet(1);
如上面的代码所示,使用addAndGet即可保证多线程中相加,具体原理在底层使用的是CAS,这里就不展开细讲。基本上AtomicXXX能满足我们的所有需求,直到前几天一个群友(ID:皮摩)问了我一个问题,他发现在很多开源框架中,例如Netty中的AbstractReferenceCountedByteBuf 类中定义了一个refCntUpdater:
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater;
static {
AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> updater =
PlatformDependent.newAtomicIntegerFieldUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
if (updater == null) {
updater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
}
refCntUpdater = updater;
}refCntUpdater 是Netty用来记录ByteBuf被引用的次数,会出现并发的操作,比如增加一个引用关系,减少一个引用关系,其retain方法,实现了refCntUpdater的自增:
private ByteBuf retain0(int increment) {
for (;;) {
int refCnt = this.refCnt;
final int nextCnt = refCnt + increment;
// Ensure we not resurrect (which means the refCnt was 0) and also that we encountered an overflow.
if (nextCnt <= increment) {
throw new IllegalReferenceCountException(refCnt, increment);
}
if (refCntUpdater.compareAndSet(this, refCnt, nextCnt)) {
break;
}
}
return this;
}俗话说有因必有果,netty多费力气做这些事必然是有自己的原因的,接下来就进入我们的正题。
2.Atomic field updater
在java.util.concurrent.atomic包中有很多原子类,比如AtomicInteger,AtomicLong,LongAdder等已经是大家熟知的常用类,在这个包中还有三个类在jdk1.5中都存在了,但是经常被大家忽略,这就是filedUpdater:
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
- AtomicReferenceFieldUpdater
这个在代码中不经常会有,但是有时候可以作为性能优化的工具出场,一般在下面两种情况会使用它:
- 你想通过正常的引用使用volatile的,比如直接在类中调用
this.variable,但是你也想时不时的使用一下CAS操作或者原子自增操作,那么你可以使用filedUpdater。 - 当你使用AtomicXXX的时候,其引用Atomic的对象有多个的时候,你可以使用filedUpdater节约内存开销。
2.1 正常引用volatile变量
一般有两种情况需要正常引用:
- 当代码中引入已经正常引用,但是这个时候需要新增一个CAS的需求,我们可以将其替换AtomicXXX对象,但是之前的调用都得换成
.get()和.set()方法,这样做会增加不少的工作量,并且还需要大量的回归测试。 - 代码更加容易理解,在
BufferedInputStream中,有一个buf数组用来表示内部缓冲区,它也是一个volatile数组,再BufferedInputStream中大多数时候只需要正常的使用这个数组缓冲区即可,再一些特殊的情况下,比如close的时候需要使用compareAndSet,我们可以使用AtomicReference,我觉得这样做有点乱,使用filedUpdater来说更加容易理解,
protected volatile byte buf[];
private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf");
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}2.2 节约内存
之前说过在很多开源框架中都能看见filedUpdater的身影,其实大部分的情况都是为了节约内存,为什么其会节约内存呢?
我们首先来看看AtomicInteger类:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
}在AtomicInteger成员变量只有一个int value,似乎好像并没有多出内存,但是我们的AtomicInteger是一个对象,一个对象的正确计算应该是 对象头 + 数据大小,在64位机器上AtomicInteger对象占用内存如下:
- 关闭指针压缩:16(对象头)+4(实例数据)=20不是8的倍数,因此需要对齐填充 16+4+4(padding)=24
- 开启指针压缩(-XX:+UseCompressedOop): 12+4=16已经是8的倍数了,不需要再padding。
由于我们的AtomicInteger是一个对象,还需要被引用,那么真实的占用为:
- 关闭指针压缩:24 + 8 = 32
- 开启指针压缩: 16 + 4 = 20
而fieldUpdater是staic final类型并不会占用我们对象的内存,所以使用filedUpdater的话可以近似认为只用了4字节,这个再未关闭指针压缩的情况下节约了7倍,关闭的情况下节约了4倍,这个在少量对象的情况下可能不明显,当我们对象有几十万,几百万,或者几千万的时候,节约的可能就是几十M,几百M,甚至几个G。
比如在netty中的AbstractReferenceCountedByteBuf,熟悉netty的同学都知道netty是自己管理内存的,所有的ByteBuf都会继承AbstractReferenceCountedByteBuf,在netty中ByteBuf会被大量的创建,netty使用filedUpdater用于节约内存。
在阿里开源的数据库连接池druid中也有同样的体现,早在2012的一个pr中,就有优化内存的comment:
,在druid中,有很多统计数据对象,这些对象通常会以秒级创建,分钟级创建新的,druid通过filedUpdater节约了大量内存:
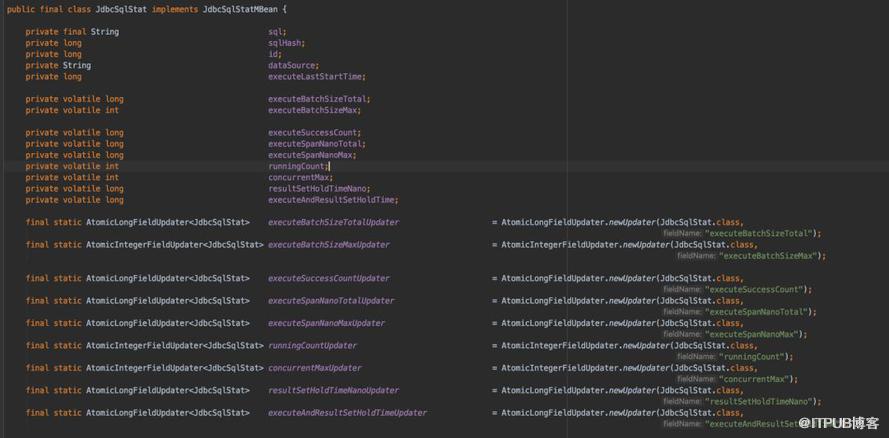
3.最后
AtomicFiledUpdater的确在我们平时使用比较少,但是其也值得我们去了解,有时候在特殊的场景下的确可以作为奇技淫巧。