
库伯奈斯现在越来越受欢迎。难怪!这是一项令人敬畏的技术,在各种云环境中(无论是私有云还是公共)中部署和编排应用程序方面,都有很大的帮助。
我,作为一个与阿帕奇点燃工作很多的人,几乎每天都会问如何与库伯内特一起使用。Ignite 是一个分布式数据库,因此利用 Kubernets 来部署它似乎非常有吸引力。此外,许多公司目前正在将其整个基础设施过渡到 Kubernetes,有时包括多个 Ignite 群集以及数十个与 Ignite 相关的应用程序。
我认为阿帕奇·伊金非常对库伯内斯友好。首先,它通常与它运行的地方无关。它本质上是一组 Java 应用程序,因此,如果您可以在环境中运行 JVM,则很可能运行 Ignite 没有任何问题。其次,Ignite 附带了 Docker 映像和有关如何在库伯奈斯使用它们的详细文档:https://apacheignite.readme.io/docs/kubernetes-deployment
同时,有一些陷阱特定于 Ignite_Kubernetes 组合,我想与您分享。以下是我将尝试给出答案的问题:
- 群集发现 – 如何在库伯内斯实现?
- 无状态和状态群集 – 什么是区别,它如何影响 Kubernetes 配置?
- 粗客户端与瘦客户端 – 在库伯内斯运行时应使用哪些客户端?
群集发现
部署 Apache Ignite 时,需要确保节点相互连接并形成群集。这是通过发现协议完成的:https://apacheignite.readme.io/docs/tcpip-discovery
为 Ignite 配置发现的最常见方法是简单地列出预期运行节点的服务器的套接字地址。喜欢这个:
Ⅹ
<属性名称="发现Spi">>
<豆类="org.apache.ignite.spi.发现.tcp.Tcp发现斯皮">
<属性名称="ipFinder">
<豆类="org.apache.ignite.spi.发现.tcp.ipfinder.kubernetes.Tcp发现库伯内斯IpFinder">
<属性名称="命名空间"值="点燃"/>
• </豆>9</属性>10</豆>11</属性>12</豆>无状态和状态群集
如何使用 Ignite 有两种不同的方法:作为现有数据源(关系数据库和 NoSQL 数据库、Hadoop 等)之上的缓存图层,或作为实际数据库。在后一种情况下,Ignite 使用开箱即用的本机持久性存储。
如果 Ignite 充当缓存,则所有数据都保留在缓存外部,因此 Ignite 节点是易失性的。如果节点重新启动,它实际上以全新的节点开始,没有任何数据
另一方面,如果 Ignite 充当数据库,则对数据的一致性和持久性承担全部责任。每个节点都会在内存和磁盘上存储一部分数据,如果重新启动,则只会丢失内存中的数据。但是,必须保留磁盘上的数据。有一个永久状态必须维护,所以群集是有状态的。
在 Kubernetes 世界中,这转换为不同的控制器,您应该用于不同类型的群集。下面是一个简单的规则:
遵循此规则将帮助您不要使无状态群集的配置过于复杂,同时确保有状态群集按预期工作。
粗客户端与瘦客户端
Ignite 提供各种客户端连接器,它们具有不同的用途,其设计方式也大不相同。我在之前的一篇文章中详细地写了这个问题:https://dzone.com/articles/apache-ignite-client-connectors-variety。Kubernetes 环境的具体情况为主题增加了其他注意事项。
库伯奈斯不会将单个吊舱直接暴露给外部世界。相反,通常有一个负载均衡器负责接受所有外部请求并将其重定向到 pod。Ignite 服务器节点和客户端应用程序都可以在负载均衡器的任意一侧运行,这会影响粗客户端和瘦客户端之间的选择。
通常,您将看到这三种方案之一。
方案 1:库伯内斯的一切
通过"一切",我指的是 Ignite 群集和与此群集说话的应用程序。它们在同一库伯奈斯环境的同一命名空间中运行。
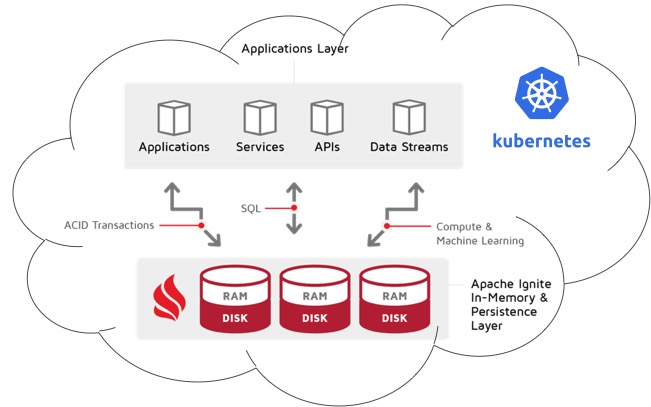
在这种情况下,没有任何限制 - 您可以自由使用任何类型的客户端连接器
方案 2:库贝内斯外部的群集
对于正在进行将现有群集和应用程序从更传统的裸机部署转换为 Kubernetes 部署的公司来说,这是非常典型的。
此类公司通常更喜欢先转换应用程序,因为它们更具动态性 — 由大量单独的开发人员经常更新。这使得应用程序的正确编排比 Ignite 群集重要得多,该群集可以运行数月甚至数年,而不会中断,并且通常由一小群人维护。
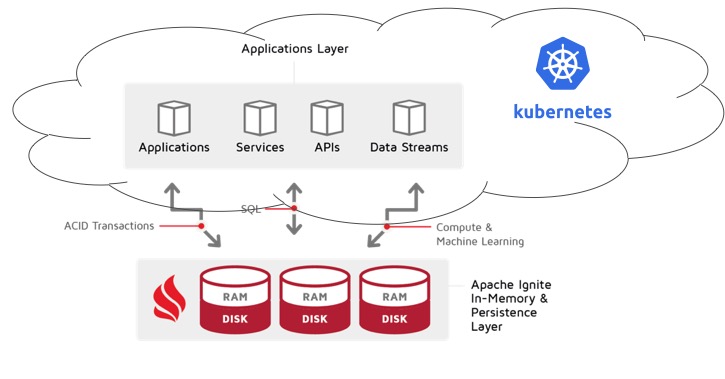
在这里,我们有一个重大的限制:厚客户端不兼容此方案。原因是服务器节点可能尝试尝试创建具有特定粗客户端的 TCP 连接。由于 Kubernetes 群集前面的负载均衡器,这很可能会失败。
如果您发现自己处于这种情况中,您当前有两个选项:
- 使用瘦客户端或 JDBC/ODBC 驱动程序,而不是粗客户端。
- 将 Ignite 群集移动到 Kubernetes 环境(有效地过渡到没有这些限制的方案 1)。
但好消息是:Apache Ignite 社区认识到此限制的影响,目前正在进行改进,允许在此类部署中使用厚客户端。敬请关注!
方案 3:库贝内斯以外的应用程序
这与前面的方案相反 - Ignite 群集在 Kubernetes 中运行,但应用程序不在它之外。
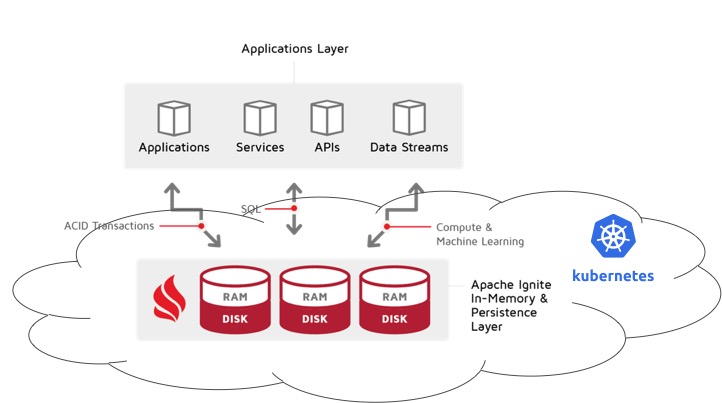
虽然我见过几次,但与其他两个相比,这种情况极为罕见。你以后可以感谢我了!
从 Ignite 的角度来看,这种类型的部署仅允许瘦客户端和 JDBC/ODBC 驱动程序。在这种情况下,不能使用粗客户端。
我上面描述的是在库伯内斯环境中使用 Apache Ignite 时可能会遇到的主要并发症。
作为下一步,我建议看看这个 GitHub 存储库,其中我上传了可用于在 Amazon EKS 中部署有状态 Ignite 群集的完整配置文件:https://github.com/vkulichenko/ignite-eks-config
当然,请随时参考 Ignite 文档了解更多详细信息:https://apacheignite.readme.io/docs/kubernetes-deployment