
什么是数据探索?
数据探索或探索性数据分析 (EDA) 提供了一套简单的探索工具,这些工具将实时数据的基本理解引入数据分析。数据探索的结果对于理解数据结构、值分布和相互关系是一个强有力的因素。数据探索还有助于数据科学家获得对以前不易看到的业务数据的正确见解。
数据探索是数据分析的第一步。了解业务数据对于做出精心规划的决策至关重要,这通常涉及总结数据集的主要特征,例如其大小、模式、特征、准确性等。
整个过程由一组数据分析师使用可视化分析工具和一些先进的统计软件(如 R) 进行。数据探索可以使用手动方法和自动化工具(如数据可视化、图表和初步报告)的组合。
什么是数据准备?
数据准备通常用于正确的业务数据分析。数据准备过程包括收集、清理和合并数据到可进一步用于分析的文件中。
您可能还喜欢:
具有微查询和数据锐化的大数据探索。
为什么需要准备数据?
- 筛选非结构化、不一致和无序的数据。
- 从实时多个数据源连接数据。
- 用于快速报告数据。
- 处理从刮伤文件(如 PDF 文档)收集的数据。
数据准备过程
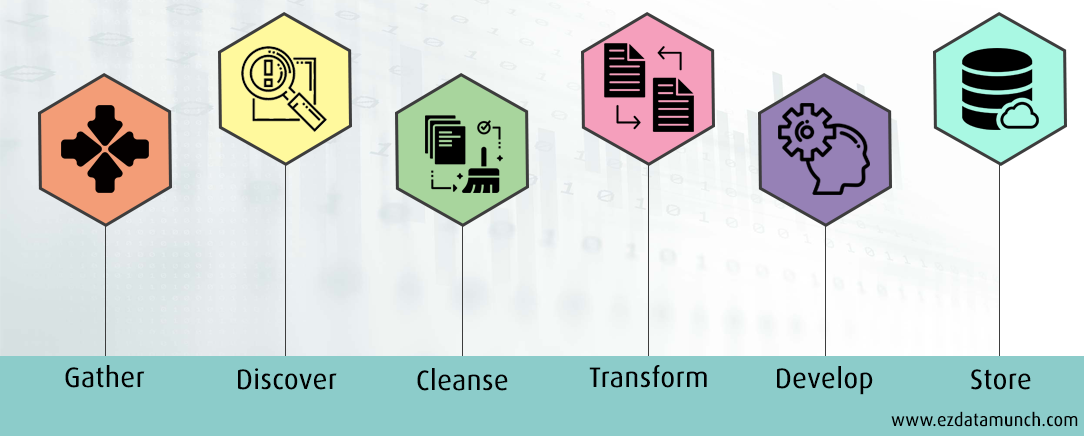
在这里,我们将讨论标准的数据准备过程,每个企业都遵循该程序。
收集数据
这是每个业务的初始过程。在此阶段,有必要从各种来源收集数据 – 源可以是任何类型的,如从目录或临时可以添加。
发现数据
下一步是发现数据;在这里,了解数据并将其分类到不同的数据集是非常重要的
清理和验证数据
这对于删除您认为在下一步中可能无用的错误和关键数据是必需的。需要在此处采取重要步骤:
- 删除不必要的数据和异常值。
- 使用适当的模式来优化所有数据。
- 使用锁定来保护敏感数据。
- 填充数据流的空白空间。
清理数据后,应通过测试团队,其中必须重新检查所有优化数据。
转换数据
转换数据定义维护格式或值条目,以满足良好的定义输出,并可以清楚地了解更广泛的受众。
存储数据
这是完成上述所有过程后的最后一步。清除数据后,即可提供第三方工具,例如用于分析的商业智能工具。
数据准备的好处
以下是数据准备的几个优点:
- 在处理错误之前快速响应。
- 通过清理和重新格式化数据集来生成数据。
- 更高质量的数据可帮助您更高效、更快速地分析数据。
数据勘探方法
数据探索有两种格式:自动和手动。大多数情况下,分析师更喜欢自动化方法,例如数据可视化工具,因为它们的准确性和响应速度很快。另一方面,手动数据探索方法包括筛选和深入到 Excel 电子表格中的数据或编写脚本来分析原始数据集。
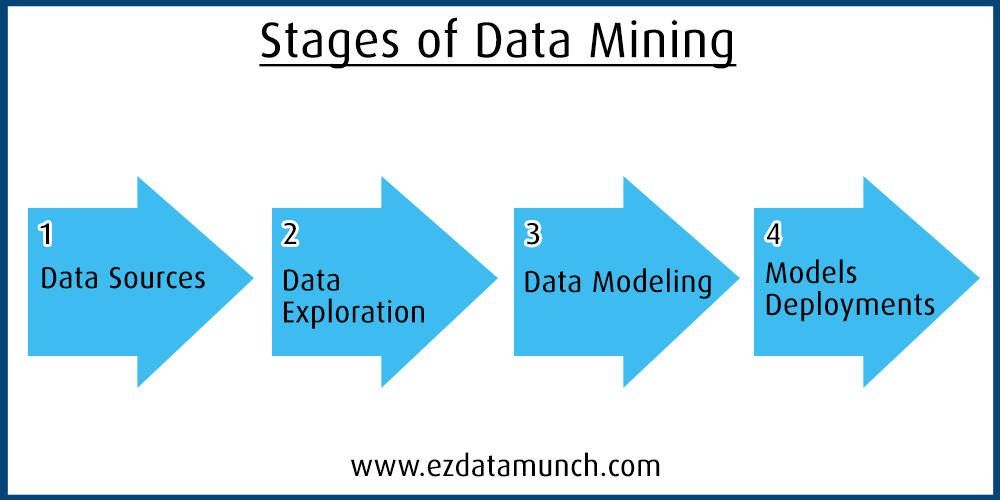
数据勘探在数据挖掘过程中起着至关重要的作用。分析数据有几种技术,例如:
统一分析:它是分析数据的最简单形式。统一变量意味着数据中只有一个变量。
双变量分析:它是最简单的定量分析形式。它包括用于计算两个变量之间的经验关系的两个变量(如 x,y)的分析g. 在多重回归或 GLM 方差分析中)。
主要成分分析:将可能相关的变量分析和转换为少量不相关变量。
数据探索后的下一步是数据发现。在此阶段,商业智能工具用于检查趋势、序列和事件,并创建可视化效果以呈现给业务经理。
数据探索工具
提供许多商业智能工具和数据可视化软件。一些常用的数据分析工具是 Microsoft Power BI、Qlik 和 Tableau。
提供许多商业智能工具和数据可视化软件。数据分析师使用的一些常用工具是微软PowerBI、Qlik和Tableau。
数据探索和准备步骤
输出的质量始终取决于输入的质量。因此,使输入值如此通用,使输出保持不变。
以下是了解、清除和准备数据以构建预测模型的步骤:
- 变量标识。
- 单变量分析。
- 双变量分析。
- 缺失值处理。
- 异常治疗。
- 变量转换。
- 变量创建。
让我们开始详细讨论每个步骤。
可变标识
在此步骤中,您必须首先标识输入和输出变量。然后,确定变量的数据类型和类别。让我们通过应用一个实时示例来更加专注
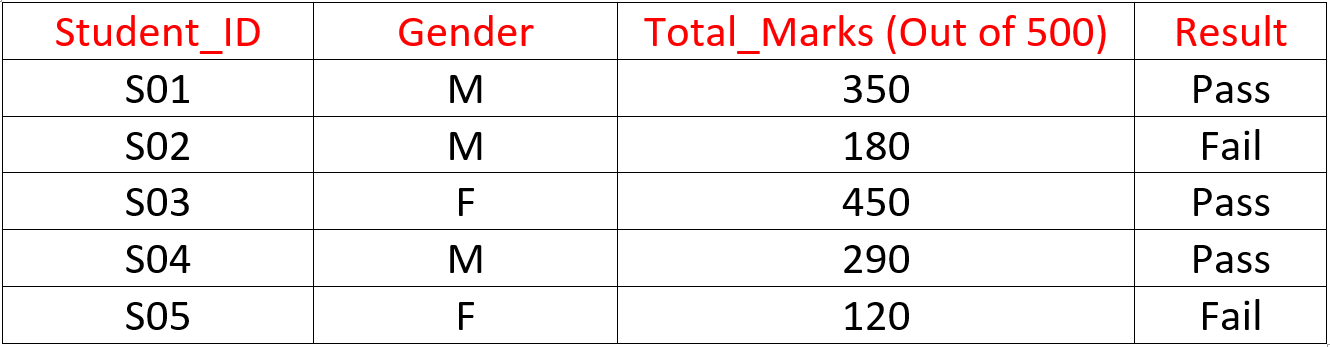
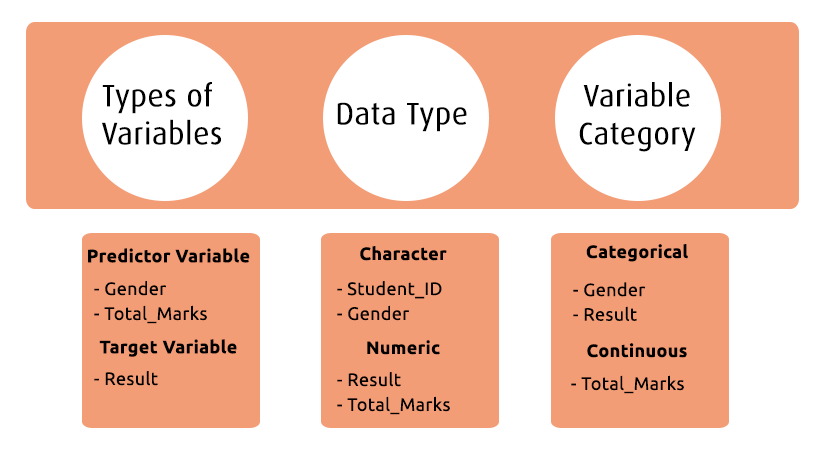
假设学校想要预测学生成绩的比率(通过或失败)。在这里,您需要收集预测变量、目标变量、数据类型和变量类别。
下面,变量已在不同的类别中定义:
单变量分析
在单变量分析中,变量被逐一探索它可以使用两个指标(计数和计数百分比)针对每个类别进行测量。条形图可用作可视化效果。
双变量分析
双变量分析是双变量数据的分析。它用于找出两组值之间是否有关系。它通常涉及变量 X 和 Y。
双变量分析示例:
- 散点图
- 回归分析
- 相关系数
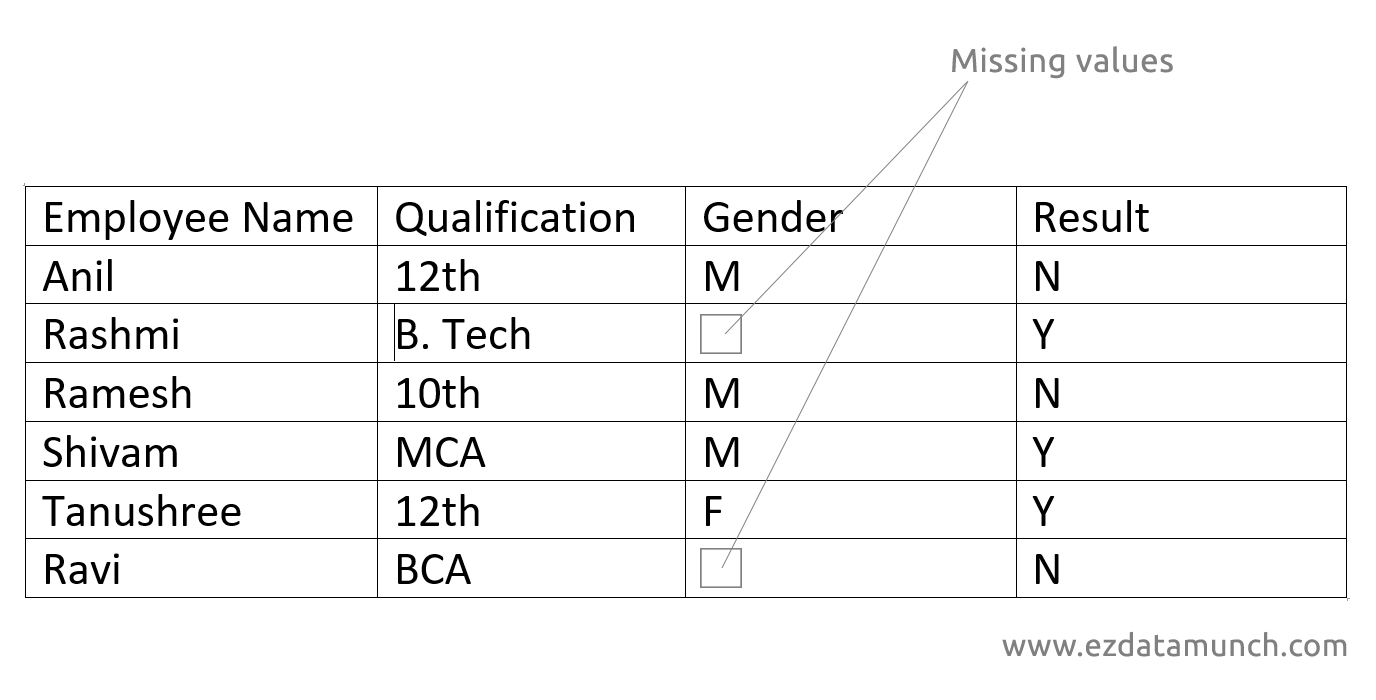
缺失值处理
有必要理解缺失值的概念,因为如果处理不当,就会发生不准确的干扰。它可能导致不正确的预测和分类。
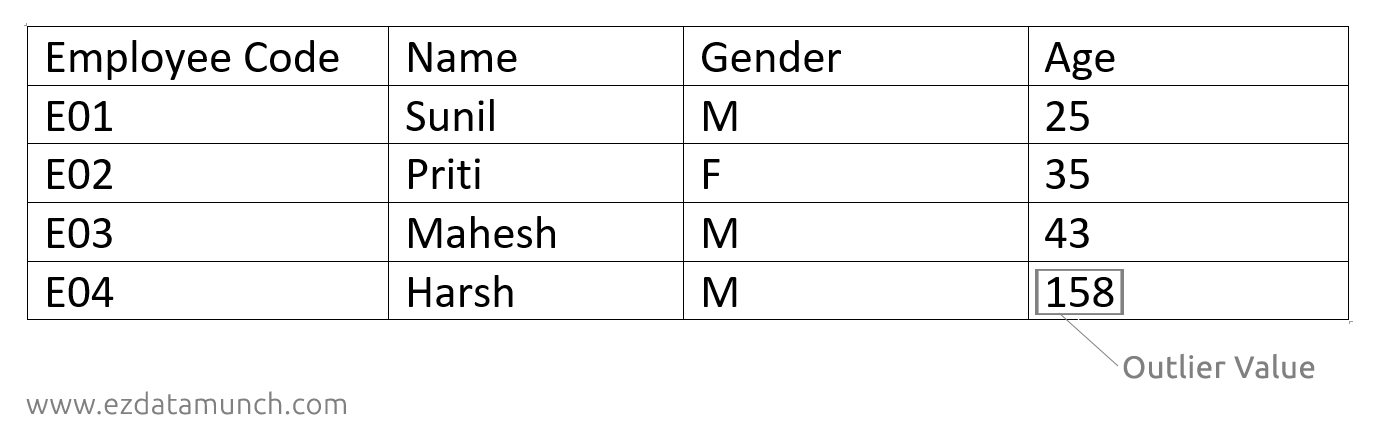
Outlier 治疗
异常值是远离另一个不同点的数据点。这些异常值应从数据集中删除。这可以通过查看数据表或工作表直接识别。
变量转换
数据并不总是以立即适合分析的形式提供。在分析之前,我们经常必须更改变量。转换是使用函数或每个观测值上的一些数学运算对数据的递归。
结论
从上述讨论中可以明显看出,通过使用正确的工具,组织可以轻松有效地检测和呈现数据。然而,与任何事情一样,制定计划并集中精力会产生最好的结果