
作者 | 小鹿
来源 | 小鹿动画学编程
说到程序员找女朋友,不是用动态规划最为合适吗?求最优解吗,你一下子就想到了,值得表扬。
但是这篇文章的前提是必须要有一个女朋友,你没有,对不起,防劝退。今天主题主要是通过广度和深度优先搜索,找到丢失的女朋友,希望通过这个有趣的问题,可以加深你对广度和深度优先遍历的理解。
本篇文章会涉及到图的相关基础知识,可以先回顾一下之前分享过图的文章。
图解:什么是图?
广度优先搜索
什么是广度优先遍历?继续借助上方找女朋友的问题继续探索。你女朋友和你吵了一架,然后就离家出走了。为了能够找到她,你不得不使用像雷达方式一样的搜索方式去找。

像上边雷达一样地毯式搜索,这种从一条边开始,进行地毯式搜索方式就是广度优先搜索。
深度优先搜索
深度优先搜索就不同了,换一个场景我们再试试。这次并不是女朋友吵架丢失,而是去游乐场走迷宫丢失了,你为了能够找到她,不得不每条迷宫线路都要去走,如果前方碰到了死胡同,那么你就回退到上一个交叉路口,然后再走另一个线路,直到找到女朋友或者所有迷宫路线为止。
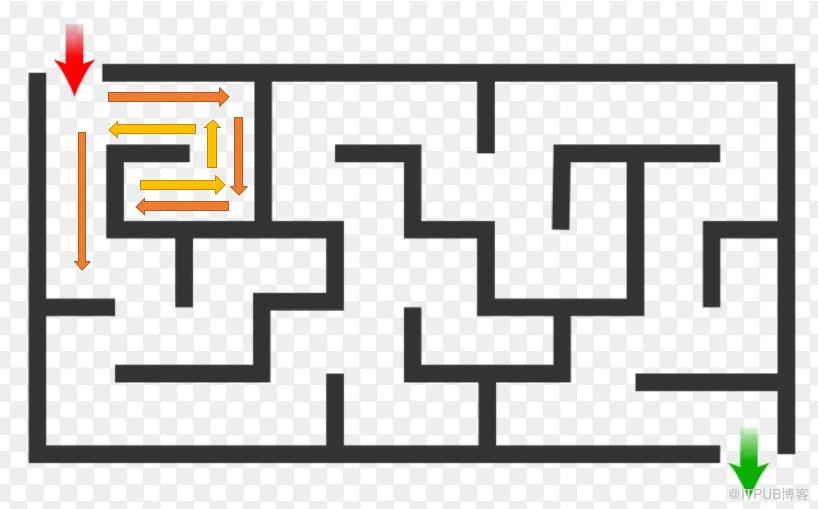
问题分析
为了更好的去理解广度和深度优先遍历的思路和代码,我会通过以图为例子,整体的搜索思路是怎么样的,明白了思路和逻辑,这样才会让你轻松理解代码和手写代码。
我们把雷达的四分之一部分抽象成图,这次我们并不像雷达横向扫描,而是从中心点向外扩散扫面如下图所示:
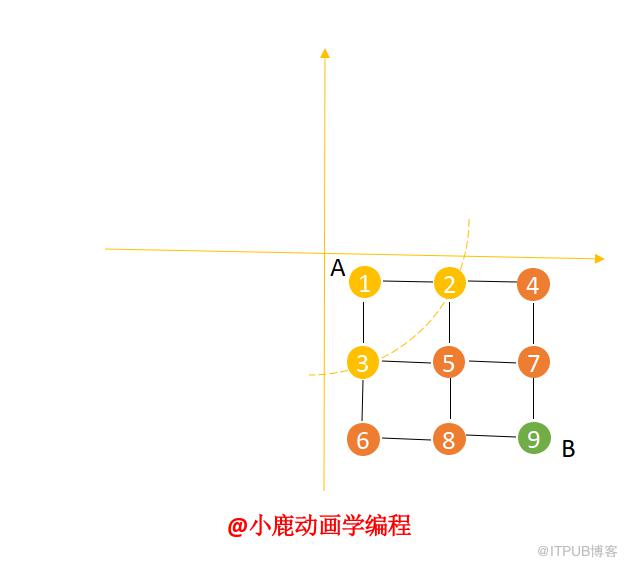
首先来看广度优先遍历,以图为例子,从图的一个顶点到另一个顶点,通过广度优先遍历的方式进行搜索,直到搜索到为止,打印出最短搜索路径。
我们从上图中的 A 点开始搜索,通过广度优先遍历求出到 B 点的最短搜索路径。
动画实现
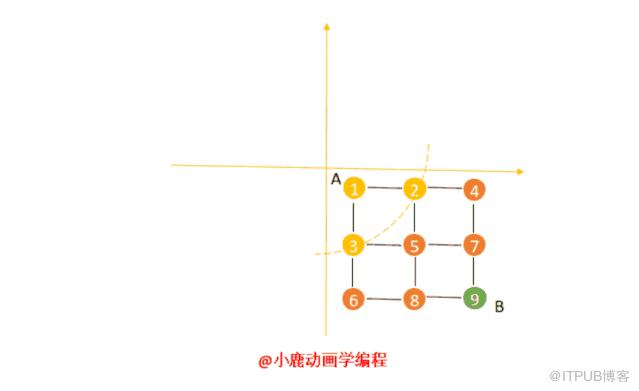
广度优先遍历:
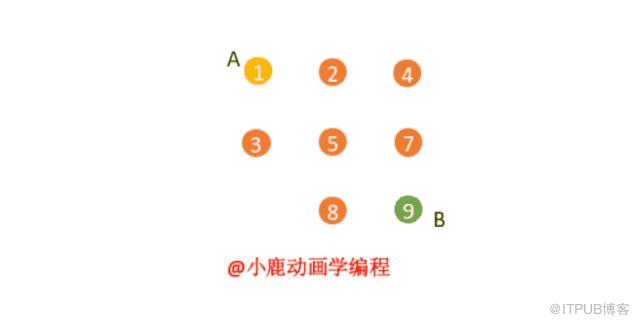
深度优先遍历:
广度优先搜索的思路
如果我们想将以上转化为代码实现,首先我们要明确解题思路。
先分析广度优先遍历。我们从 A 点出发,先对邻接顶点进行扫描,1 的邻接顶点是 2 和 3,然后判断是否有我们要找的终点 B ,如果没有,我们继续按照上述方法找出 2 和 3 的邻接顶点,分别为 4、5、6,然后再判断这一层中是否存在我们要找的顶点,如果没有我们继续依次遍历。
直到我们搜索到最后一层 9 ,程序执行结束。虽然整个搜索过程不是很难理解,但是转化为代码需要稍微思考一下。
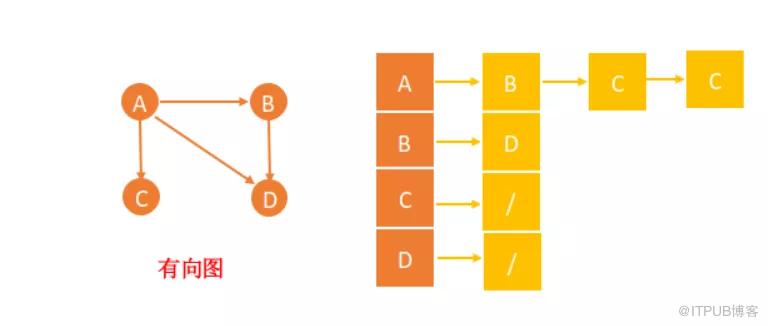
之前图的文章已经分析过,图的存储有两种方式,我们此次采用了邻接表法存储。
1constructor(v) {
2 this.v = v;
3 this.adj = [];
4 this.visited = [];
5 this.pre = [];
6 this.queue = [];
7 this.found = false;
8 for (let i = 0; i < v; i++) {
9 this.adj[i] = new Array();
10 }
11}
12
13// 无向图的边存储两次
14addEdge(s, t) {
15 this.adj[s].push(t)
16 this.adj[t].push(s)
17}通过以上观察到的规律,每一层的顶点都是由上一层得到的。我们可以维护一个队列 queue,每遍历一层,我们就将该层的顶点推进队列,当前层遍历完毕的时候,我们开始遍历下一层时,我们依次出队,通过顶点之间存储的关系可以得到下一层的顶点。
与此同时,我们还需要创建一个数组 result,用来储存从 A 搜索到 B 的路径。result[2] = 3 代表的是 3 顶点是由 2 顶点搜索过来的,到最后我们倒序递归数组就会得出 A 到 B 的最短路径。
鹿哥,如果你的顶点重复被扫描了,不就多一次了吗?是的,除此之外,我们还需要一个数组 visited 来记录已经扫描过的顶点,每扫描一个顶点,我们就拿该顶点在该数组中判断是否之前扫描过,如果没有扫描,我们就加入到其中,否则,直接跳过扫描下一个顶点。
代码实现
1class Graph {
2 constructor(v){
3 this.v = v;
4 this.adj = [];
5 this.visited = [];
6 this.pre = [];
7 this.queue = [];
8 for(let i = 0;i < v;i++) {
9 this.adj[i] = new Array();
10 }
11 }
12
13 // 无向图的边存储两次
14 addEdge(s, t) {
15 this.adj[s].push(t)
16 this.adj[t].push(s)
17 }
18
19 // 递归打印数组
20 // 0 ——> 6
21 print(preArr, s, t) {
22 if(preArr[t] !== -1 && s !== t){
23 this.print(preArr, s, preArr[t])
24 }
25 console.log(t);
26 }
27
28 // 广度优先遍历最短路径
29 // s 起始 t 终点
30 bfs1(s, t) {
31 var queue = this.queue,
32 pre = this.pre,
33 visited = this.visited,
34 adjTemp = this.adj;
35
36 // 判断起始点是否相同
37 if(s === t) return 0;
38 queue.push(s);
39 visited[s] = true;
40
41 // 初始化搜索路径
42 for(let i = 0;i < this.v;i++){
43 pre[i] = -1;
44 visited[i] = false;
45 }
46
47 // 开始遍历队列
48 while(queue.length !== 0) {
49 console.log(queue)
50 // 出队
51 const temp = queue.shift();
52
53 // 遍历所有于 temp 相邻的结点
54 for(let i = 0; i < adjTemp[temp].length;i++){
55
56 // console.log(adjTemp)
57 var q = adjTemp[temp][i];
58
59 // 如果没有遍历过
60 if(!visited[q]){
61 // 并记录搜索路径
62 pre[q] = temp
63
64 // 判断是否为终点
65 if(q === t){
66 // 打印路径
67 this.print(pre,s,t)
68 // console.log(pre)
69 return;
70 }
71
72 // 存到队列汇总,等待下一次的遍历
73 queue.push(q)
74
75 // 记录已访问的结点
76 visited[q] = true
77 }
78 }
79 }
80 }
81 }深度优先搜索的思路
深度优先搜索其实就是用到了回溯算法的思想,这条道路我走不通,我退回到上一个十字路口再尝试着走下一个道路,直到走到我想找到的终点为止。
虽然这样子看起来有点“蠢”,但是回溯算法可以帮助我们解决很多生活中类似的问题。

无论是广度优先搜索还是深度优先搜索,都是借助递归来实现的。它的代码实现也是有以上几个数组,result 存储搜索的路径,visited 用来记录访问过的结点。
但是有一点不同,需要定义一个变量用来当做递归终止条件,当我们照找到当前顶点了,我们就不再递归下去。
代码实现
1class Graph {
2 constructor(v) {
3 this.v = v;
4 this.adj = [];
5 this.visited = [];
6 this.pre = [];
7 this.queue = [];
8 this.found = false;
9 for (let i = 0; i < v; i++) {
10 this.adj[i] = new Array();
11 }
12 }
13
14 // 无向图的边存储两次
15 addEdge(s, t) {
16 this.adj[s].push(t)
17 this.adj[t].push(s)
18 }
19
20 // 递归打印数组
21 // 0 ——> 6
22 print(preArr, s, t) {
23 if (preArr[t] !== -1 && s !== t) {
24 this.print(preArr, s, preArr[t])
25 }
26 console.log(t);
27 }
28
29 // 深度优先遍历最短路径
30 // s 起始 t 终点
31 dfs1(s, t) {
32 const v = this.v,
33 pre = this.pre,
34 queue = this.queue,
35 visited = this.visited;
36
37 // 初始化 pre
38 for (let i = 0; i < v; i++) {
39 pre[i] = -1;
40 }
41
42 this.recurDfs(s, t, pre, visited);
43 this.print(pre, s, t);
44 }
45
46 recurDfs(s, t, pre, visited) {
47 if (this.found) return;
48
49 // 判断是否为终点
50 if (s == t) {
51 this.found = true;
52 return;
53 }
54
55 // 记录第一个已访问结点
56 visited[s] = true;
57
58 for (let i = 0; i < this.adj[s].length; i++) {
59 let temp = this.adj[s][i];
60
61 // 判断是否已经访问过
62 if (!visited[temp]) {
63
64 // 记录未访问结点的路径
65 pre[temp] = s;
66
67 // 回溯遍历
68 this.recurDfs(temp, t, pre, visited)
69 }
70 }
71 }
72 }性能分析
广度优先搜索和深度优先搜索的性能效率是如何的呢?
对于广度优先搜索来说,最坏的情况下,我们要遍历所有的顶点(n)和边(k),时间复杂度为 O(n+k)。如果是一个全通图(顶点之间都有两条连线)的话,k 是大于 n 的,时间复杂度可以写为 O(k)。
其中搜索遍历的同时,我们需要借助几个数组空间用来存储顶点,空间复杂度为 O(n)。
深度优先遍历在最坏的情况下会重复遍历两次边,时间复杂度为 O(k)。
空间复杂度主要是递归调用需要额外的栈空间,栈空间的大小和顶点 n 成正比关系,所以空间复杂度为 O(n)。
小结
以上就是今天主要的分享内容,对于广度和深度优先搜索是一个面试重点内容,尤其是做前端开发,会结合二叉树、图等数据结构来考察你该算法能力。
文章中主要分享到一个重要的思想,叫做回溯思想,这是一个重要的编程思想。除此之外,还有分治思想、贪心思想等几个重要的编程思想。掌握算法的精髓不在于多,而在于能够找出它不变的东西。
最后,你女朋友丢了就不用怕了,拿出深度和广度优先搜索就开始扫描。除此之外,关于搜索算法还有 A*算法、枚举算法、蒙特卡洛树搜索等,我们后期会抽空分享。