
GitHub 使用 MySQL 作为所有非 git 仓库数据的主要存储, 它的可用性对 GitHub 的访问操作至关重要。GitHub 站点本身、GitHub 的 API、身份验证等等都需要进行数据库访问。我们运行着多个 MySQL 集群来为不同的服务和任务提供支持。我们的集群使用经典的主从配置, 主集群中的某个节点能够接受写入。其余的从集群节点异步同步来自主服务器的更改, 并提供数据的读取服务。
主节点的可用性尤为重要。没有主服务器, 集群无法接受写入:任何需要保留的写入数据都不能持久化保存,任何传入的更改(如提交、问题、用户创建、审阅、新存储库等)都将失败。
为了支持写操作,我们显然需要有一个可用的数据写入节点,一个主集群。但同样重要的是,我们需要能够识别或找到该节点。
在一个写入失败,提示说主节点崩溃的场景中,我们必须确保能启用一个新的主节点,并快速表明其身份。检测故障所需的时间、进行故障转移并公布新的主节点所花费的时间,构成了总的停机时间。
本文将介绍 GitHub 的 MySQL 高可用性和主服务发现解决方案,它使我们能够可靠地运行跨数据中心操作,容忍数据中心隔离,并使得出现故障时耗费的停机时间变得更短。
高可用目标
本文描述的解决方案,迭代并改进了之前在 GitHub 实现的高可用(HA)解决方案。随着规模的扩大,MySQL 的高可用策略必须适应变化。我们希望为 GitHub 中的 MySQL 和其他服务,提供类似的高可用策略。
在考虑高可用和服务发现时,有些问题可以引导你找到合适的解决方案。包含但不限于:
你能容忍多长的中断时间?
崩溃检测的可靠性如何?你能容忍错误报告(过早的故障转移)吗?
故障转移的可靠性如何?什么情况下可以失败?
解决方案在跨数据中心的场景下效果如何?在低延迟和高延迟的网络情况下如何?
解决方案是否允许一个完整的数据中心故障或者出现网络隔离?
有没有防止或缓解脑裂(两台服务器都宣称是某个集群的主节点,不知情对方的存在,并且都能接受写操作)的机制。
你能允许数据丢失吗?在多大程度上?
为了说明上面的一些情况,首先让我们讨论一下之前的高可用方案,并说说我们为什么要修改它。
移除基于 VIP 和 DNS 的服务发现
在之前的迭代版本中,我们:
使用 orchestrator 来做检测和故障转移
使用 VIP 和 DNS 做主节点的发现
在这个迭代版本中,客户端使用名字服务(比如 mysql-writer-1.github.net)来发现写节点。名字可以解析为一个虚拟 IP(VIP),这个 VIP 指向主节点。
因此,在正常情况下,客户端只需要解析名称,连接到解析后的 IP上,然后发现主节点也正在另一边监听链接(也就是客户端连上了主节点)。
考虑这个跨越三个不同数据中心的复制拓扑:
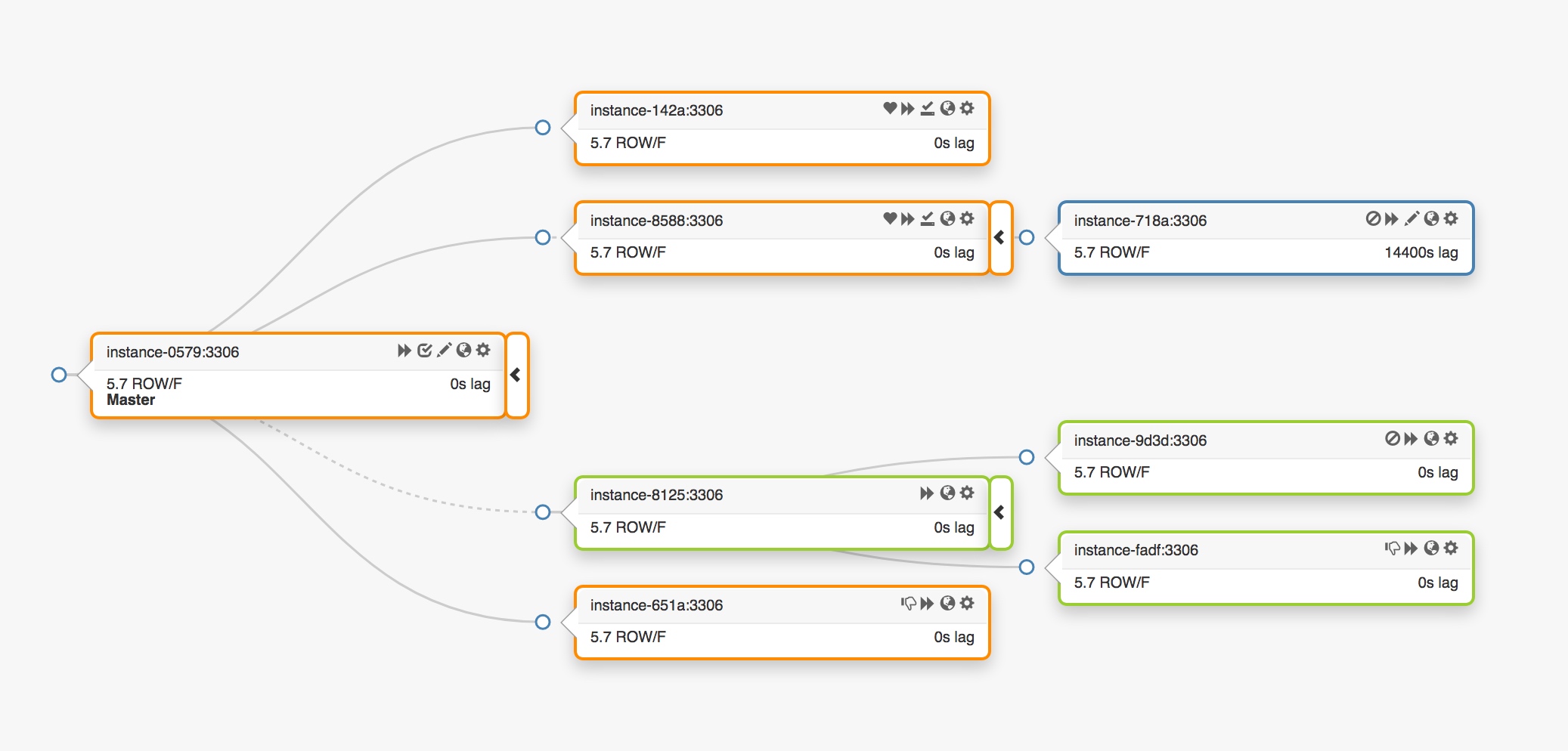 

当主节点发生故障时,必须在副本集中选出一个服务器,提升为新的主节点。
orchestrator 将会检测到故障,选举出一个新的主节点,然后重新分配 name(名称)和 VIP(虚拟 IP)。客户端实际上并不知道主节点的真实身份:它们只知道 name(名字),而这个名字现在必须解析给新的主节点。不过,需要考虑:
VIP 是需要协作的:它们由数据库服务器自己声明和拥有。为了获得或释放 VIP,服务器必须发送 ARP 请求。拥有 VIP 的服务器必须在新提升的主节点获得 VIP 之前先释放掉。这还有一些额外的影响:
有秩序的故障转移操作会首先通知故障主节点并要求它释放 VIP,然后再通知新提升的主节点并要求它获取 VIP。如果无法通知到原主节点或者拒绝释放 VIP 怎么办?首先要考虑到,该服务器上存在故障场景,它不可能会不及时响应,或根本不响应。
我们最终可能会出现脑裂情况:两个注解同时声称拥有同一个 VIP。根据最短的网络路径,不同的客户端可能会连接到不同的服务器。
事实源于两个独立服务器间的协作,并且这个设置是不可靠的。
即使原主节点确实配合,工作流程也浪费了宝贵的时间:当我们通知原主节点时,切换到新主节点的操作一直在等待。
即使 VIP 发生变化,现有的客户端连接也不能保证与原服务器断开连接,而且我们可能仍然会经历脑裂。
VIP 受限于物理位置。它们属于交换机或者路由器。所以,我们只能将 VIP 重新分配到位于同一位置的服务器上。特别是,当新提升的服务器位于不同的数据中心时,我们无法分配 VIP,只能修改 DNS。
修改 DNS 需要较长的传播时间。根据配置,客户端会缓存 DNS 一段时间。跨数据中心(cross-DC)故障转移则意味着更多的中断时间:为了让所有客户端知晓新主节点的身份,需要花费更长的时间。
仅这些限制,就足以促使我们寻求新的解决方案,但考虑更多的是:
主节点通过 pt-heartbeat 心跳服务进行自行注入,目的是测量延迟和节流。这项服务必须从新提升的主节点开始。如果有可能的话,原主节点的服务将被关闭。
同样的,Pseudo-GTID 注入也是主节点自己管理的。它将从新的主节点开始,并在原主节点结束。
新的主节点被设为可写。如果可能的话,原主节点被设为只读。
这些额外的步骤是导致中断总时间的一个因素,并且引入了它们自己的故障和摩擦。
该解决方案生效了,GitHub 已经成功完成 MySQL 的故障迁移,但我们希望我们的 HA 在以下方面有所改进:
数据中心不可知
允许数据中心出现故障
删除不可靠的协作工作流
减少总的中断时间
尽可能地进行无损故障转移
GitHub 的高可用解决方案:orchestrator, Consul, GLB
我们的新策略,除了附带的改进外,还解决或减轻了上面的许多问题。在今天的高可用设置中,我们有:
使用 orchestrator 来做监测和故障转移。我们使用跨数据中心的 orchestrator/raft 方案,如下图。
使用 Hashicorp 的 Consul 来做服务发现。
使用 GLB/HAProxy 作为客户端和写节点的代理层。
使用选播(anycast)做网络路由。
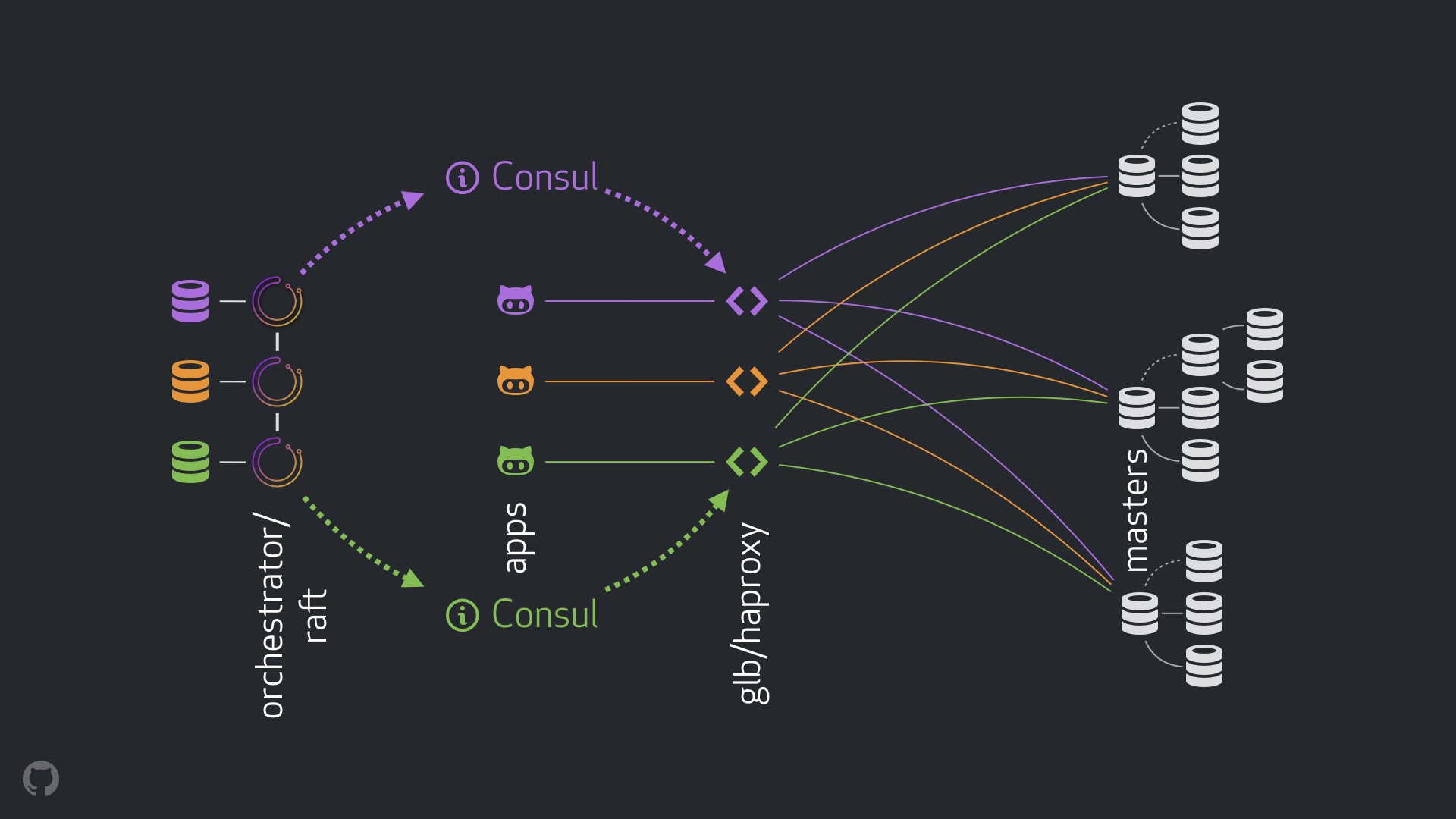 

新的设置将完全删除 VIP 和 DNS 的修改。在我们引入更多组件的同时,我们能够将组件解耦并简化任务,并且能够使用可靠、稳定的解决方案。下面逐一分析。
正常流程
正常情况下,应用程序通过 GLB/HAProxy 连接到写节点。
应用程序永远不知道主节点的身份。和之前一样,它们使用名字。例如,cluster1 的主节点命名为 mysql-writer-1.github.net。在我们当前的设置中,名字被解析为一个选播(anycast) IP。
使用选播时,名字在任何地方都被解析为相同的 IP,但流量会根据客户端位置的不同进行路由。需要指出的是,在我们的每个数据中心,都有 GLB(我们的高可用负载均衡)被部署在不同的容器中。指向 mysql-writer-1.github.net 的流量总是路由到本地数据中心的 GLB 集群。因此,所有客户端都由本地代理提供服务。
我们在 HAProxy 上运行 GLB。我们的 HAProxy 维护了一个写连接池:每个 MySQL 集群一个连接池,其中每个连接池只有一个后端服务器:集群的主节点。DC 中的所有 GLB/HAProxy 容器都具有相同的连接池,并且它们都指向相同的后端服务器。这样,如果一个应用程序想要写入 mysql-writer-1.github.net,它连接到哪个 GLB 服务器并不重要。它总会被路由到实际的 cluster1 主节点上。
对于应用程序而言,服务发现结束于 GLB,并且不再需要重新发现。就这样,通过 GLB 将流量路由到正确地址。
GLB 如何知道哪些服务器可以作为后端服务器,以及如何将更改传播到 GBL 呢?

/filters:no_upscale()/news/2026/02/mysql-foreign-keys/en/resources/1innodb-vs-sql-engine-foreign-key-cascade-1024x510-1770991931623.jpg "MySQL 9.6:对外键约束及级联操作的修改")


/filters:no_upscale()/news/2026/02/github-layered-def/en/resources/1Screenshot 2026-02-03 at 4.12.07 PM-1770164607749.png "GitHub:在原有保护机制的基础上重新构建分层防御体系,以阻止合法流量的被阻断")