
深度学习能力 AI 药物发现方法
长期失望的人有一个共同的说法,它有点像这样:”如果这是未来,我的喷气背包在哪里?与无处不在的计算、可编程单元和重新萌芽的空间探索的奇迹世界结合这种对复古未来的渴望,可以使这种抱怨的声音在粗略的检查中变得杂乱无章。对有些人来说,这种错位的怀旧未来主义可能非常持久。这导致一种倾向,坚持预测,看起来古朴回想起来,忽略了惊人的现实,没有人能预测。然而,通过对药物发现的深刻学习,我们现在能够预测这么多!这在医药行业具有十分重要的意义。
应用于人工智能,一个有这种风度的人可能会调整他们的抱怨,就像”自从AlexNet已经快8年了,我的自动驾驶汽车/AI调解的乌托邦/压制性的AI霸主在哪里?看起来,2010年代中期的预期似乎已经落空,悲观主义者对下一个AI冬季的预测正在增强。本文旨在探讨药物发现在现实世界中有意义的机器学习进展。我希望说服你考虑另一个古老的格言,这句来自人工智能研究人员,略带解释:”AI只是人工智能,直到它工作,之后它只是软件。
我们将看到,几年前机器学习中一直流血的边缘基础研究,现在通常被称为”公正”的数据科学(甚至分析),并在颠覆制药行业方面取得真正的进展。甚至有一个很好的机会,深入学习方法的药物发现改变生活,以更好地做有意义的好事在世界上。
生物医学成像中的计算机视觉与深度学习
几乎只要科学家进入计算机,就可以将图像上传到计算机上,而且几乎在那之后,人们就努力以数字方式处理这些图像。在”好老式AI”的时代,这通常意味着在边缘和亮度等简单功能上手工制作的逻辑语句。在 20 世纪 80 年代,人们开始采用监督学习算法的转变,但这些算法仍依赖于手工设计的功能。简单的监督学习模型(例如线性回归或多项式拟合)将训练由 SIFT(缩放不变性特征变换)和 HOG(定向梯度的直方图)等算法提取的要素。但是,几十年前对导致实际深度学习的发展进行调查,这不足为奇。
卷积神经网络首次应用于生物医学图像是在1995年,当时Lo等人引入了一种检测肺X射线癌结节的模型。他们的方法与我们今天习惯的方法稍有不同,推理大约需要15秒,但概念本质上是相同的,通过反向传播完成训练,一直回到卷积内核。Lo等人使用的模型有两个隐藏层,而当今流行的深层网络架构通常有一百个或更多。
快进到2012年:随着AlexNet的出现,conv-net 以大的方式进入石灰灯,在现在著名的 ImageNet 数据集上实现了性能的重大飞跃。AlexNet 的成功,一个具有 5 个卷积和 3 个密集连接层的卷网,在游戏 GPU 上训练,在机器学习领域非常出名,人们谈论 ML 和 AI 不同利基的”ImageNet 时刻”。如同在 2018 年开发超大型变压器模型时,自然语言处理可能有其 ImageNet 时刻”或”强化学习仍在等待其 ImageNet 时刻”。AlexNet 开发已近十年,我们在深度学习计算机视觉模型方面进行了大量逐步改进。应用程序已扩展到分类之外,通常包括分割、深度估计和场景重建等许多用途。
围绕生物医学图像分析深度学习的一连串热情的副作用是噪音的不可避免的增加。在2019年发表的17,000篇深度学习论文中,并不是每篇都值得阅读。许多结果可能过度拟合其小型数据集,没有多少人对基础科学研究或机器学习做出重大贡献。但是,以前对机器学习毫无兴趣的学术研究人员的深厚学习热潮是一个重要的现实wikipedia.org/wiki/Universal_approximation_theorem”rel=”nofollow”目标=”_blank”=Cybenko和Hornik的通用近似定理),它通常可以更快更好地完成,同时减少与每个新应用程序相关的繁琐的手工工程工作。
对抗被忽视疾病的难得机会
这让我们想到了今天的药物发现这个话题,这个行业可以利用好的变革。制药公司和它们雇佣的公司很快提醒我们,将一种新药推向市场的巨大成本。这些费用主要是由于许多药物进入开发管道,在被丢弃之前停留了一段时间。业界估计,开发新药的成本可能高达25亿美元或更多,尽管这个数字可能在很大程度上受到该行业报告高成本的激励,以证明其产品的溢价率的合理性。无论如何,由于这种高成本和相对较低的回报率,药物类的基本工作,如抗生素得到优先排序。
这也意味着被适当命名的被忽视疾病类别的疾病,其中包括估计无法治愈的热带疾病和发病率较低的罕见疾病。尽管每种疾病患的受感染人数相对较少,但受一种罕见疾病或另一种罕见疾病影响的人数却相当高。据估计,全世界患有罕见疾病的人数约为3亿。但是,即使这个数字可能因为令人沮丧的预后而看似低:大约30%患有罕见疾病的人从未度过五岁生日。
罕见疾病的“长尾”是改善大量生活的大好机会,机器学习和大数据工程也乐于介入。制药行业对这些罕见疾病的盲点,尤其是没有FDA批准的治疗的孤儿疾病,为创新的生物学家和机器学习开发人员团队提供了立足点的机会。考虑到大型制药公司雇用的数据科学家数量之多,用一个小团队建造真正新颖的东西需要找到一个阴暗的地方,以便更好地避免更多厌恶风险的既定实体的饥饿眼睛递归制药公司认为,忽视疾病缺乏有意义的药物开发,是制药行业的差距,从而推动着一个激进的新工作流程的楔子。基于自动化的高通量显微镜和机器学习,它们通过机器人显微镜和液体处理生成大量新数据。深度神经网络的广义性和灵活性利用由此产生的数据海来揭示实验噪声中的疾病/治疗表型。到2019年底,他们已经从数千个实验中产生了超过4PB的数据。他们打包了他们为 NeurIps 2019 竞赛轨道生成的一小部分数据,您可以从RxRx 网站下载 (46 GB) 数据集,亲自使用。
本文中描述的工作流程主要基于递归制药公司白皮书[pdf]中的信息,但没有理由不能为传统制药公司未能取得进展的其他领域提供灵感。事实上,这个领域的其他初创公司包括生物实验室专注于与衰老有关的疾病,著名的实验室研究癌症,和TwoXAR处理各种疾病缺乏治疗选择。这些公司往往是具有新兴数据管道的年轻初创公司,他们采用不断变化的机器学习技术到他们感兴趣的领域,除了或代替计算机视觉深度学习我们今天将讨论。
我们将主要关注以递归为主导的方法,因为它们严重依赖图像模型,自 2013 年以来,它们一直在出现,他们发布了大量有关其方法的信息,并且已开始产生有希望的结果。我将介绍图像分析过程,以及深度学习如何从高水平开始融入罕见疾病药物发现工作流程,这些经验教训可应用于药物发现的其他各种领域。例如,该工作流程可以很容易地用于筛选癌症药物对肿瘤细胞形态的影响,甚至可能确定单个患者对药物选项面板的细胞反应。该方法从非线性PCA(语义散列)中借用概念
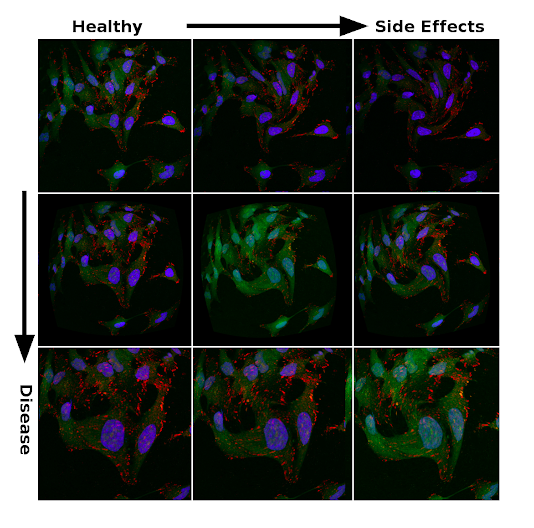
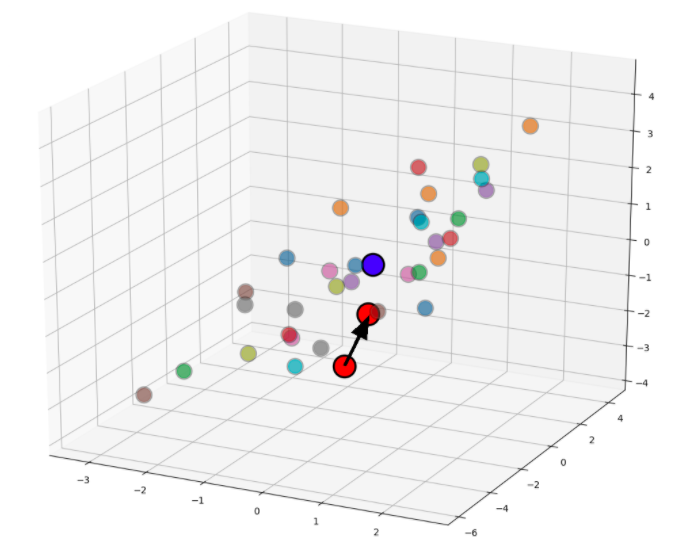
生物学是混乱的。这在高通量、高含量的显微镜中显而易见,并且一直是细胞生物学家感到沮丧的根源。任何给定实验生成的图像可能因批次而异。温度、暴露时间、试剂批次等的波动都会产生与所研究表型或候选药物化合物的影响无关的误导性变化。实验室的气候控制在夏天和冬天的表现是否不同?有人在午餐时把装有细胞的96孔盘子放在显微镜上之前,有没有把细胞放在外?是否有人将供应商换成了培养介质成分?供应商更换自己的供应商了吗?能促成实验变异的变量数量是巨大的。跟踪和分离非实验扰动(又称意外噪声)的影响是数据驱动药物发现中的一大挑战。 显微镜图像可能因实验的复制而急剧变化。图像亮度、细胞形状、细胞形状和许多其他特征可能因相关的生理效应或随机实验噪声而发生变化。本文顶部面板中的图像都来自斯科特·威尔金森和亚当·马库斯对转移癌细胞的同一公有领域显微图。强度和形态的变化是实验噪声的代表,使用图像处理扭曲产生。这些扩展与在分类任务中固定深度神经网络可能使用的扩增类型相同,因此,给定大型数据集的大型模型的通用化能力是揭示噪声海洋中生理上有意义的差异的逻辑选择也就不足为奇了。 在嘈杂的强度变化中,治疗效果和副作用的变异代表。 罕见疾病通常有基因突变作为其根本原因。为了建立模型来发现这些疾病的治疗,有助于了解大量突变的影响以及由此产生的表型的相关性wikipedia.org/wiki/Small_interfering_RNA”rel=”无跟随”目标=”_blank”=小干扰RNA(siRNA)。这有点像蹒跚学步的孩子抓住你的脚踝:即使你能够跑得相当快,你也会少得多的有效与侄女或侄子挂在每条腿。siRNA的工作方式非常相似,小序列的干扰RNA粘在特定基因的信使RNA片段上,阻止这些基因得到充分表达。 通过训练数千个突变,而不是特定疾病的奇异细胞模型,神经网络可以学会在高维潜伏空间中编码表型。由此产生的代码允许评估药物的能力,使疾病表型更接近健康的表型,每个由多维坐标集表示。同样,药物副作用可以嵌入编码的表型表示,药物不仅可以评估减少疾病症状,还可以对有害副作用进行最小化。 表示治疗对疾病细胞模型(由红点表示)影响的图表,将表型编码移近健康表型(蓝点)。这是多维潜伏空间中表型编码的简化 3D 表示形式。 用于此工作流的深层学习模型将与其他具有大型数据集的分类任务大致相同,尽管如果您习惯于处理 CIFAR-10 和 CIFAR-100 数据集等少量类别,则数千个不同的分类标签需要一些时间才能适应。除此之外,这种类型的基于图像的药物发现将很好地与同一种基于密集网或 ResNet 的深层体系结构配合使用,这些体系结构具有 100 个左右,这些层可能会在 ImageNet 等数据集上获得最先进的性能。 通过将其中一个层的活化值作为表型的高维编码,疾病病理学以及治疗、副作用和其他疾病之间的关系可以通过编码空间中的位移进行分析。此类型代码可以进行定制化正化(例如,最小化不同激活的协方差),以减少编码相关性或根据需要用于其他目标。下面的卡通是一个简化的示例模型,黑色箭头表示卷积 – 池操作和蓝色线表示密集连接,图层数量减少(未显示剩余连接),以便清晰png”数据-新=”假”数据大小=”105461″数据大小格式化=”105.5 kB”数据类型=”临时”数据 url=”/存储/临时/13212536-屏幕拍摄-2020-04-10-在25434 -pm.png”src=”http://www.cheeli.com.cn/wp-内容/上传/2020/04/13212536屏幕拍摄-2020-04-10-在25434-pm.png”样式=”宽度:795px;”/> 药物发现深度学习模型的简化说明 将一种新药推向市场的巨大成本导致制药公司忽视对严重疾病的所需药物发现和开发,而转而选择畅销药物。初创企业中规模较小、数据精通的团队更有能力在此领域开发新的创新,而被忽视和罕见的疾病提供了在数据驱动管道中站稳脚跟并展示机器学习价值的机会。 这种方法的价值证明在实质性进展中得到了证明,并且已经在第一阶段的临床试验中,几种药物已经通过数百名科学家和公司(如递归制药公司)的工程师团队取得了这一成就。其他初创公司紧随其后:TwoXAR有几个候选药物,他们通过其他疾病类别的临床前试验。 深入学习的计算机视觉方法对药物开发可以预期对大型制药公司和医疗保健行业产生重大影响。我们应当很快看到,这种影响是开发治疗普遍疾病(包括心脏病和糖尿病等现代生活方式疾病)的新疗法,以及在治疗疾病方面急需的进展。对嘈杂形态进行分类
药物发现与制药行业深度学习的未来