

在我们讨论黄铜钉之前,快速列出我们希望理想数据湖提供的具体优势会很有帮助。这些是:
- 能够从企业众多数据源和孤岛中的任意位置收集任何形式的数据。从收入数字到社交媒体流,以及介于两者之间的任何内容。
- 减少分析或处理不同应用程序出于不同目的的相同数据集所需的工作量。
- 保持整个操作的成本效益,能够根据需要扩展存储和计算容量,并且彼此独立。
考虑到这些要求,让我们看看如何使用 AWS 设置数据湖
您可能还喜欢:使用 AWS 的工具、提示和技巧。
数据湖架构
典型的数据湖架构旨在:
- 从各种来源获取数据。
- 通过某种处理层移动它们。
- 使其可供企业内的不同角色使用。
因此,在这里,我们有一些关键的体系结构部分要考虑:
着陆区:这是所有原始数据来自企业内所有不同来源的区域。该区域严格用于数据引入,在此阶段不应进行建模或提取。
固化区:您可以在此处播放数据。整个提取-转换-加载 (ETL) 过程在此阶段进行,对数据进行爬网以了解它是什么以及它有何用处。元数据的创建,或应用不同的建模技术来寻找潜在的用途,都在这里完成。
生产区域:这是您的数据可以被使用到不同的应用程序,或由不同的角色访问的地方。
带 AWS 的数据湖架构
有了我们的基本区域,让我们来看看如何使用正确的 AWS 解决方案创建完整的数据湖架构。在本文的其余部分中,我们将尝试引入适用于任何场景的 AWS 产品,但重点关注我们认为能带来最佳结果的几个关键产品。
着陆区 = 数据引入和存储
对于此区域,我们首先看一下数据引入的可用方法:
- 亚马逊直接连接:在您的场所或数据中心与 AWS 云之间建立专用连接,以确保数据引入安全。Amazon 直接连接具有行业标准 802.1q VLAN,可提供更一致的网络连接,用于将数据从内部系统传输到数据湖。
- S3 加速器:另一种快速的方法使数据引入到 S3 存储桶中是使用 Amazon S3 传输加速。这样,您的数据就会传输到任何全球分布的边缘位置,然后通过优化的安全路径路由到 S3 存储桶。
- AWS 雪球:使用 AWS Snowball,您可以安全地将大量数据传输到 AWS 云上
它是传输大量数据资产(如基因组学、分析、图像或视频存储库)的绝佳选择。
- 激酶数据流:将实时数据流从不同源引入 AWS,并创建默认情况下位于多个可用性区域上的任意二进制数据流。
- 基内斯火索:您可以使用 Kinesis Firehose 捕获、转换数据并快速将数据加载到 Amazon S3、RedShift 或弹性搜索中。AWS 托管系统可自动扩展以匹配您的数据吞吐量,并可以批处理、处理和加密数据,从而将存储成本降至最低。
- Kinesis 数据分析:Kinesis 数据分析是分析流数据的最简单方法之一,它选择任何流源,对其进行分析,并将其推送到其他数据流或 Firehose。
存储 + 亚马逊 S3
Amazon S3 是使用最广泛的云存储解决方案之一,非常适合在着陆区存储数据。S3 是一个区域级别、多可用性区域存储选项。它是一种高度可扩展的对象存储解决方案,可提供 99.999999999% 的耐用性。
但撇开容量不谈,Amazon S3 适用于数据湖,因为它允许您设置数据通过不同存储类移动的生命周期。
- Amazon S3 标准存储正在跨不同企业应用程序立即使用的热数据。
- Amazon S3 不频繁访问,以保存在整个企业中访问较少的暖数据,但在需要时需要快速访问这些数据。
- 与内部存储相比,Amazon S3 Glacier以极低的成本存档冷数据。
固化区 • 目录和搜索
由于数据湖中的信息采用原始格式,因此可以由不同的应用程序查询和用于多个不同的目的。但是,为了实现这一点,反映技术和业务意义的可用元数据也必须与数据一起存储。这意味着您需要有一个提取元数据并正确编目元数据的过程。
元包含有关数据格式、安全分类敏感、机密等信息、其他标签来源、部门、所有权等信息。这使得不同的应用程序,甚至运行统计模型的数据科学家,能够知道数据湖中存储的内容。
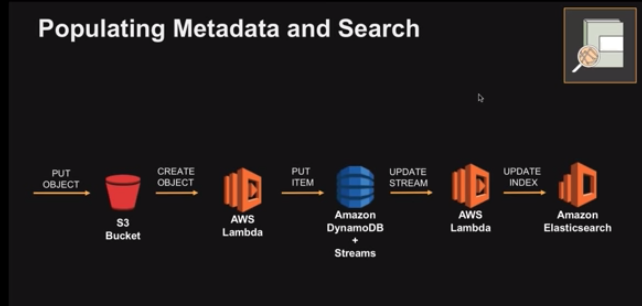 来自”在 AWS 上构建数据湖”的屏幕抓图,亚马逊网络服务,Youtube
来自”在 AWS 上构建数据湖”的屏幕抓图,亚马逊网络服务,Youtube
典型的编目过程涉及为提取元数据而编写的 lambda 函数,每次对象进入 Amazon S3 时都会触发元数据。此元数据存储在 SQL 数据库中,并上传到 AWS 弹性搜索,以便可供搜索。
AWS Glue是一个 Amazon 解决方案,可以管理此数据编目过程并自动执行提取-转换-加载 (ETL) 管道。这些解决方案在 Apache Spark 上运行,并维护与 Hive 兼容的元数据存储。工作原理是:
- 定义爬网程序以扫描进入 S3 的数据并填充元数据目录。您可以按设定的频率安排此扫描,也可以在每个事件触发。
- 定义 ETL 管道和 AWS Glue,并在 Python 中生成 ETL 代码。
- 设置 ETL 作业后,AWS Glue 将管理其在 Spark 群集基础结构上运行,并且仅在作业运行时向您收费。
AWS Glue 目录在数据处理引擎之外,使元数据保持分离。因此,不同的处理引擎可以同时查询其不同用例的元数据。可以使用 API 网关向 API 层公开元数据,并通过该网关路由所有目录查询。
固化区 + 加工
编目完成后,我们可以查看数据处理解决方案,这些解决方案可能根据不同的利益相关者对数据的不同要求而有所不同。
亚马逊弹性地图缩减 (EMR)
亚马逊的 EMR 是一个托管的 Hadoop 群集,可以以低成本处理大量数据。
典型的数据处理涉及在 EC2 上设置 Hadoop 群集、设置数据和处理层、设置 VM 基础结构等。但是,EMR 可以轻松处理整个过程。配置完成后,您可以在几分钟内启动新的 Hadoop 群集。您可以将它们指向任何 S3 以开始处理,并且一旦作业完成,群集就会消失。
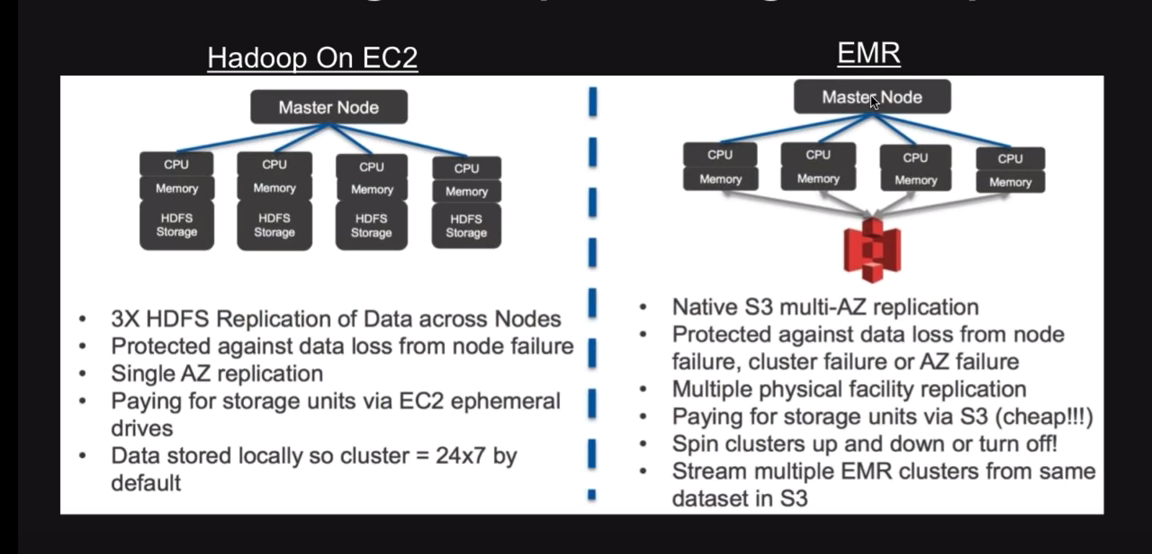
源:使用 EMR 而不是 EC2 上的 Hadoop 进行处理的主要好处是节约了成本。对于后者,您的数据位于 Hadoop 处理群集中,这意味着即使完成处理任务,群集也需要启动。所以,你仍在为此付出代价。
但是,使用 EMR 时,您的数据和处理层是分离的,允许您相互独立地缩放它们。因此,当数据驻留在 S3 中时,可以根据需要设置和停止 EMR 上的 Hadoop 群集,从而使处理成本完全灵活。通过轻松地将其与 Amazon 现货实例集成以降低定价,成本也降低了。
亚马逊弹性搜索
这是另一个可扩展的托管搜索节点群集,可轻松与其他 AWS 服务集成。它最适合日志分析用例。
亚马逊红移
如果您有很多 BI 仪表板和应用程序,Amazon RedShift 是一个伟大的处理解决方案。它价格低廉,完全管理,并确保安全性和合规性。使用 RedShift,您可以启动计算节点群集以同时处理查询。
这个处理阶段也是企业可以设置他们的沙盒的地方。他们可以打开数据湖的数据科学家运行初步实验。由于数据收集和采集现在已处于可谨慎,因此数据科学家可以专注于寻找创新方法,将原始数据用于使用。
他们可以带来开源或商业分析工具,以创建所需的测试台,并致力于创建符合不同业务用例的新分析模型。
生产区域 = 服务处理数据
通过处理,数据湖现在可以将数据推送到所有必要的应用程序和利益相关者。因此,您可以将数据分到旧版应用程序、数据仓库、BI 应用程序和仪表板。分析师、数据科学家、业务用户和其他自动化和参与平台可以访问此功能。
因此,您可以拥有完整的数据湖架构,以及如何使用同类最佳的 AWS 解决方案进行设置。


