
最近, 我的一位同事提出了一个要求: 如何在 redis 中创建内容筛选器?他想根据一系列脏话过滤收到的信息。这是一个相当常见的用例–任何接受用户输入的应用可能都希望至少对不恰当的单词进行粗略扫描。我首先想到的是, 他应该使用布鲁姆过滤器, 但我想知道是否有更好的选择, 所以我想测试我的假设。我从这里得到了一个不好的词的列表, 并做了一些初步测试的文本尤利西斯由詹姆斯·乔伊斯 (一个大的书在公共领域与许多有趣的语言!)。
对于那些不熟悉的人来说, bloom 筛选器是一种概率 (p11c) 数据结构, 可以测试是否存在。这种方法一开始看起来很吓人, 但它真的很简单: 将项目添加到 bloom 筛选器中, 然后检查是否存在于 bloom 筛选器中。bloom 筛选器是概率的, 因为它们无法明确回答存在性问题–它们要么告诉您一个项目肯定不在筛选器中, 要么可能不在筛选器中。换句话说, 与布鲁姆过滤器误报是可能的, 但假阴性不是.布鲁姆过滤器真正酷的是, 它们使用的空间的一小部分 (与实际存储项目相比), 并且可以以适度的计算复杂性确定可能的存在。我的妻子是一名文学教授, 我很开心地选择了尤利西斯参加这次考试, 提醒我这本书的主角叫布鲁姆。拟 合。
回到手头的问题上来。你想做的是把给定信息中的所有单词都拿出来, 找到一个已知的坏词列表的交集。然后你确定有问题的单词, 或者拒绝或者手动筛选它们。
为了使事情尽可能易于使用, 并避免任何网络瓶颈, 我在 lua 中实现了所有解决方案, 并从 redis 内部运行它们。我使用了一个 lua 表, 其中的键是不合适的单词, 值是 “true”, 以防止在所有脚本中发出不需要的 redis 命令。
关于消息处理的说明: 在脚本中, 我使用了一个非常简单的方法, 只是按空间拆分。诚然, 这本身在实践中是行不通的, 因为你需要处理标点符号、数字等。在这种情况下, 它工作得很好, 因为我们以同样的方式处理脚本, 而不是试图测量 lua 字符串拆分的速度。
使用内容筛选集
除了 bloom 筛选器之外, 解决此问题的另一种方法是使用 redis set。我做的第一件事就是使用 sadd 命令和超过1600个参数将脏话添加到 set 键中。我拿了坏单词列表, 用双引号包围了每个单词, 然后加上了 sadd 和密钥的前缀, 最后将其保存到一个文本文件 (badwords-sets. txt)。我执行它与这个重新的 cli 管道技巧:
$ cat ./badwords-set.txt | redis-cli -a YourRedisPassword一个简单的方法是将信息分解成文字, 并在消息中的每个单词上运行 sism置于以识别单词。我最初的想法是, 命令的数量之多将使这种情况效率低下。让我们看看它是如何实现的:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local badwords = {}
for word,v in pairs(words) do
if redis.call('SISMEMBER', KEYS[1], word) == 1 then
table.insert(badwords,word)
end
end
return badwords我们在这里所做的就是拆分第一个参数 (在本例中为消息), 然后遍历单词并为每个参数运行 sism直er。如果 sismember 返回 1, 那么我们知道这是一个坏词, 并将其添加到一个表, 我们返回到 redis让我们用 sadd 和 sinter 来做这件事。同样, 这似乎是一吨的命令, 但下面是它在 lua 中的外观:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
for word,v in pairs(words) do
redis.call('SADD',KEYS[1],word)
end
local badwords = redis.call('SINTER',KEYS[1],KEYS[2])
redis.call('UNLINK',KEYS[1])
return badwords这是相同的拆分例程, 但我没有为每个单词颁发 sism开出, 而是将其添加到使用 sadd 设置的临时 redis 中。然后, 我使用啊, 我使用啊, 用 “辛特” 命令, 把这个临时集合和我们的坏话交织在一起。最后, 我摆脱了与 unlink 的临时设置, 并返回了啊, 是我的结果。使用此方法, 请记住您正在写信给 redis。这对持久性和分片有一些影响, 因此 lua 脚本的相对简单隐藏了一些操作复杂性。
内容过滤与绽放
对于我的第二种方法, 我将所有的脏话添加到布鲁姆过滤器中。与 sadd 一样, 您可以一次向带有 bf 的 bloom 筛选器添加多个项目。命令。事实上, 我拿了包含所有坏单词和 sadd 命令的文本文件, 只是替换了命令 (现在是 bf。madd) 和键。
使用此解决方案, 请务必记住, bloom 筛选器是概率的, 它们可以返回误报。根据您的使用情况, 这可能需要对结果进行二次检查, 或者只是将其用作手动过程的屏幕。
首先, 让我们看一下 lua 脚本, 以检查是否存在脏话:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local badwords = {}
for word,v in pairs(words) do
if redis.call('BF.EXISTS', KEYS[1], word) == 1 then
table.insert(badwords,word)
end
end
return badwords类似于 sismamer 方法, 我们可以将传入字符串拆分为唯一的单词, 然后运行 bf。每个单词都有例外。Cfo如果筛选器中可能存在, 则存在 existts 将返回 1; 如果筛选器肯定不存在, 则返回0。此解决方案将消息中的每个单词与筛选器进行比较, 将任何坏单词插入表中, 并在最后将其返回。
我们还可以使用 rebloom 模块, 该模块提供 bf。命令检查多个字符串与筛选器。它的功能与 bf 相同。可以, 但可以让你一次做得更多。然而, 这一次的事情变得有些棘手。运行多个命令 (即使是来自 lua 的命令) 会给 redis 带来一些开销, 因此, 理想情况下, 您希望运行的命令越少越好, 让 redis 实际检查数据, 而不是花费资源来解释数千个命令。最好通过最大化参数的数量来最大限度地减少命令调用 (这至少是理论)。
我的第一次尝试只是把《尤利西斯》 (45, 834) 的所有独特之语 (45, 834 字) 都推入 bf 的一个命令中。使用解包功能的 mexistts。这并没有成功, 因为 lua 的固定堆栈大小远远小于我的45k 参数。这迫使我拆分我的 bf。mexist 分成更小的单词块。尝试和错误帮助我发现, 我可以安全地添加约 7, 000个参数到 bf。在卢亚抱怨之前, 麦克斯命令。这是以 lua 脚本的复杂性为代价的, 但这意味着我可以运行66个命令, 而不是超过45k。
下面是脚本的最终外观:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local function bloomcheck(key,wordstocheck,dest)
for k, v in ipairs(redis.call('BF.MEXISTS',key,unpack(wordstocheck))) do
if v == 1 then
table.insert(dest,wordstocheck[k])
end
end
end
local possiblebad = {}
local temp = {}
local i = 0;
for word,v in pairs(words) do
table.insert(temp,word)
i = i+1;
if i == 7000 then
bloomcheck(KEYS[1],temp,possiblebad)
temp = {}
i = 0;
end
end
bloomcheck(KEYS[1],temp,possiblebad)
return possiblebad正如你所看到的, 这开始是大量的 lua 代码最后, 它返回所有可能的坏话。
测试
从 cli 运行 lua 脚本并不有趣, 因为您正在处理大型参数, 并且事情可能会变得棘手。因此, 我使用基准. js 框架编写了一个小型 node. js 脚本, 多次运行我的测试, 并在每次运行时获得正确的统计信息。除了尤利西斯, 我还运行它的1000和500字的 lorem ipsum 随机文本集, 以获得较短的消息的感觉。所有这些测试都是在我的开发笔记本电脑上运行的, 因此除了相对差异之外, 它们的含义微不足道。
让我们来看看结果:
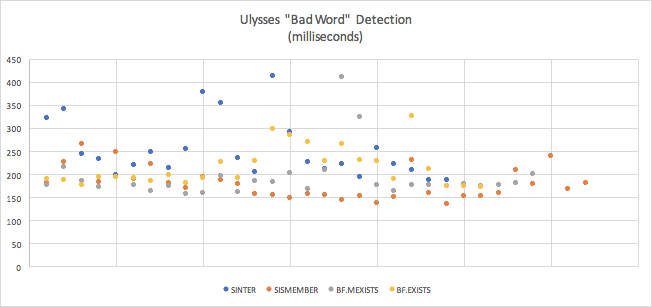
| 均值 | 标准偏差 | 错误的边距 | |
|---|---|---|---|
| 入门级 (第4) | 0.25 2477065875 秒 (252.478ms) |
0.06331450637410971 | 0.026739796333390907027 |
| 妹妹 (1) | 0.17 3657477090625秒 (179.356 毫秒) | 0.034054707030413132506 | 0.0117993526261322626679 |
| Cfo墨西哥菜 (第2次) | 0.1925117373762064 (192.52 毫秒) | 0.05 1589253435185 | 0.019619660405252156 |
| Cfo考试 (第3次) | 0.21505565530769238 (23.556ms) | 0.04 1931428091619434 | 0.01640265013395354 |
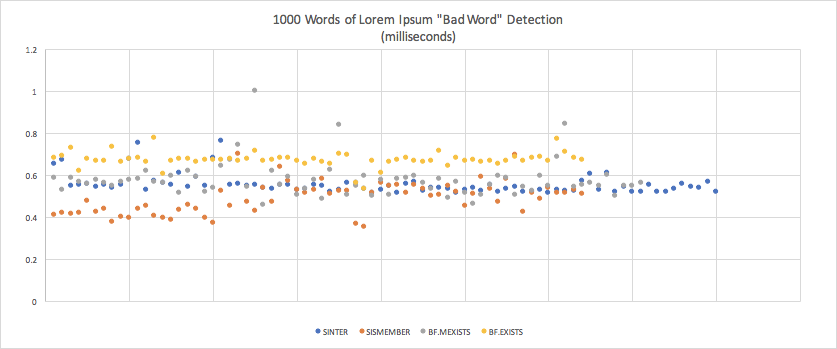
| 均值 | 标准偏差 | 错误的边距 | |
|---|---|---|---|
| 烧结机 (第2次) | 0.000 55343038665705 (0.55 毫秒) | 0.0000 4478206422951418 | 0.0000 10447163737135063 |
| 妹妹 (1) | 0.00087821613392592 (0.49 毫秒) | 0.00007453275890098545 | 0.0000 1826260593074143636 |
| Cfo墨西哥菜 (第3次) | 0.00057705050503133733705 (0.58 毫秒) | 0.00884234034283731551 | 0.0000 199593614949282812 |
| Cfo考试 (4) | 0.0006705186154166669 (0.67 毫秒) | 0.000035960357334688716 | 0.00000 8888 8754646998835 |
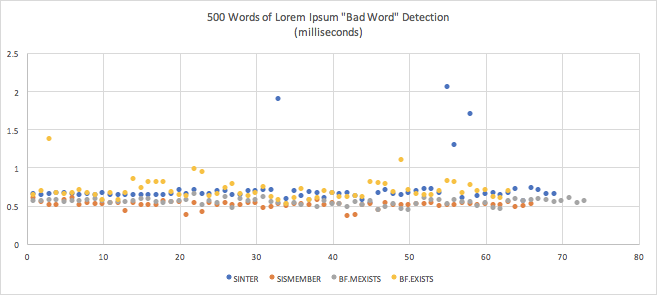
| 均值 | 标准偏差 | 错误的边距 | |
|---|---|---|---|
| 入门级 (第4) | 0.0007199102990995225 (0.72 毫秒) | 0.000 2662192424373751274 | 0.0000 686 1610037055691 |
| 妹妹 (1) | 0.000512735960882813 (0.51 毫秒) | 0.000042812670318675034 | 0.000103288558277771371371371371373年 |
| Cfo墨西哥菜 (第2次) | 0.0005467939453535285 (0.55 毫秒) | 0.004135890147573503 | 0.00000 94877778886686 |
| Cfo考试 (第3次) | 0.0007052701613834288 (0.71 毫秒) | 0.00013292929264339345952 | 0.000032836237873305535 |
结论
我觉得这些结果很有趣。我最初的假设是不正确的这种情况-布鲁姆过滤器不是最快的。在所有测试中, 普通的老 ssammer 运行得更快。除此之外, 我的一些重要外卖包括:
- 尤利西斯是这种类型的事情不寻常的工作量, 你很可能不会有很多詹姆斯·乔伊斯提交史诗小说
响应时间因小数毫秒而异, 因此这些差异是不可察觉的。
那你为什么要使用布鲁姆过滤器呢?存储效率。让我们看最后一件事:
127.0.0.1:6379> MEMORY USAGE badwordsset
(integer) 68409
127.0.0.1:6379> MEMORY USAGE badwords
(integer) 4228在这里, “坏词” 是布鲁姆过滤器, 而 “坏词集” 是集结构。布鲁姆过滤器比集合小16X 以上。在这种情况下, 大小并不那么重要, 因为它是一个单一的列表。但是, 想象一下, 如果一个网站上的每个用户都有自己的脏话过滤器?这真的可以使用 set 结构来添加, 但使用 bloom 筛选器会更容易容纳。而这一测试表明, 响应时间非常相似。




