
最近, 我的公司面临着将1000万行 csv 格式的地理数据实时加载到 mongodb 的严峻挑战。
我们首先尝试创建一个简单的 python 脚本来加载内存中的 csv 文件并将数据发送到 mongodb。以这种方式处理1000万行需要 26分钟!
实时处理数据集的26分钟是不可接受的, 因此我们决定以不同的方式进行处理。
使用 hadoopn spark 进行数据摄入
wa 决定将 hadoop 群集用于原始数据 (实木复合地板而不是 csv) 存储和复制。
为什么选择实木复合地板?
实木复合地板是一种柱状文件格式, 提供高效的存储。更好的压缩列和编码算法已经到位。我们主要使用雅典娜的大文件。bigquery 还支持实木复合地板文件格式。因此, 我们可以更好地控制性能和成本。

使用 apache spark 映射数据
apache spark 是分布式数据处理最强大的解决方案之一, 尤其是在实时数据分析方面。
阅读带有 spark 的实木复合地板文件非常简单和快速:
val df = spark.read.parquet("examples/src/main/resources/data.parquet")在 mongodb 中存储数据
mongodb 为 apache spark 提供了一个连接器, 该连接器公开了 spark 的所有库。
以下是如何通过 sparksession 启动连接器配置的方法:
val spark = SparkSession.builder()
.master("local")
.appName("MongoSparkConnectorIntro")
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.myCollection")
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1/test.myCollection")
.getOrCreate()将数据框写入 mongodb
编写数据框架到 mongodb 是非常简单的, 它使用相同的语法编写任何 csv 或实木复合地板文件。
people.write.format("com.mongodb.spark.sql.DefaultSource").mode("append").option("database",
"people").option("collection", "contacts").save()比较表演-谁赢?
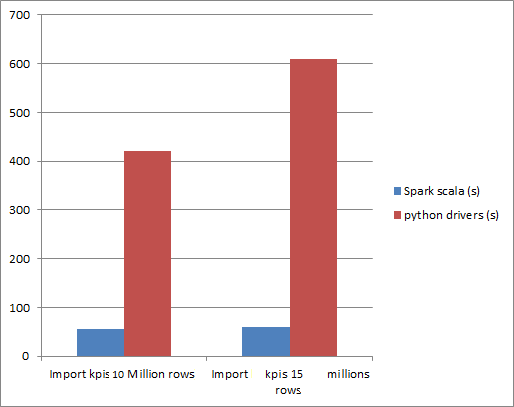
毫无疑问, 斯派克会赢, 但不是这样。在性能方面的差异是巨大的!
更有趣的是 spark 解决方案是可扩展的, 这意味着通过向我们的集群添加更多的计算机并拥有最佳的集群配置, 我们可以获得一些令人印象深刻的结果。