

(由AI科技大本营付费 下载自视觉中国)
作者 | 刘占亮 一览群智技术副总裁
编辑 | Jane
出品 | AI科技大本营( ID:rgznai100)
如何合理地表示语言的内在意义?这是自然语言处理业界中长久以来悬而未决的一个命题。
在 2013 年分布式词向量表示(Distributed Representation)出现之前,one-hot 是最常用的字词数值表示形式。在这样的词袋模型下,语言被表示为极其稀疏的向量形式,词之间的相互关系完全独立,语言深刻的内在含义被简化成 0-1 关系。
而之后出现的一系列预训练词向量(如 Word2Vec、Glove 等),在一定程度上解决了词袋模型的稀疏性,对大部分NLP任务的表现都带来了一定程度的提升,但其仍无法对如组合性,多义性、照应性、依赖性等复杂语言现象进行合理的表示。到了 2018 年,随着一系列在大规模语料上训练的深度语言模型的出现,以阅读理解为代表的一大批 NLP 任务的榜单屡被刷新,人工智能在语言上的理解能力超过人类的言论一度甚嚣尘上。但当我们回过头来仔细思考,在真实的“自然语言理解”业务场景中,这一轮“技术革新”带来的利好似乎乏善可陈。
那么,对大规模语料的暴力拟合是不是真的能让模型理解语言的语义呢?
2019 年出现的 GTP2 模型参数数量达到了惊人的 15 亿之巨,由它生成的新闻甚至能骗过专业的记者。但值得玩味的是,今年早些时候 台湾成功大学的几位研究者发现,BERT 更多地学到了语言中的统计线索,而不是理解文本当中的真正逻辑。当我们用同样的模型对武侠小说进行学习之后,在其生成的文本中我们看到“三柄长剑断作两截”这样的“statistically impeccable but logically wrong”的句子,让我们进一步验证基于人工神经网络的大规模语言模型对语言的深度理解仍然有限。
其实,对于语言表示的问题,在统计学派兴起之前的 20 世纪初期,以索绪尔为代表的一批符号学派语言学家就开始系统地研究了。到了六十年代末期,随着逻辑学家和语言学家之间的屏障开始被打破,一批理论语言学家们着手为自然语言寻求一套完整的语义理论模式,来对语义进行完整的表示。美国逻辑学家理查德·蒙塔古是其中的佼佼者,他认为自然语言与形式语言在基本文法逻辑上是一致的,他提出的“蒙太古语法”也为之后的语义表示研究奠定了基础。
> There is in my opinion no important theoretical difference between natural languages and the artificial languages of logicians; indeed I consider it possible to comprehend the syntax and semantics of both kinds of languages with a single natural and mathematically precise theory. (Montague 1970c, 222)
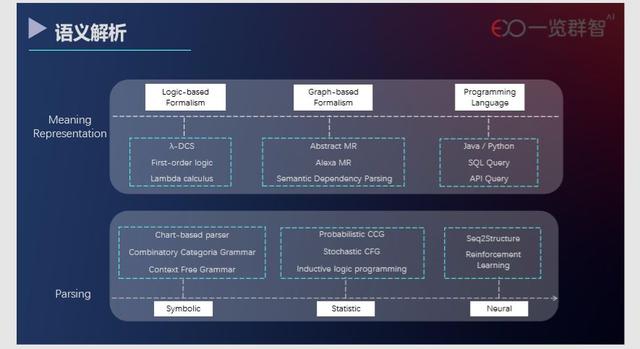
在语义解析这个领域,语义表示早期的工作几乎都是符号学派为主的,例如一阶逻辑表达式和lambda计算式。举个例子,对于:

这样一个自然语言,利用一阶逻辑表达式可以简单地表达为:

但这些早期的逻辑表达式有一些限制条件。例如,在一阶逻辑中,量词只能用于个体变元,取消这一限制条件,允许量词也可用于命题变元和谓词变元,由此构造起来的谓词逻辑就是高阶逻辑。 FMR(Functional Meaning Representation)就是利用高阶函数来做意义表达,将语义(函数声明的调用)和语用(函数具体实现逻辑,函数体)的实现解耦合,让模块的复用性和实用性更好。
也有一些研究者希望用有向无环图来更完备地表达语义,例如由帕尔默等人提出的AMR(Abstract Meaning Representation)。近年来,一些工业界机构也根据自己的业务场景提出了满足各自需求的多种语义表示方法,例如亚马逊的 Alexa 语音助手就采用了同样基于有向无环图的AMRL(Alexa Meaning Representation Language)来表示以对话为主的自然语言。
还有一些研究者倾向于把自然语言直接转化为像 Python、SQL 一样的程序语言,使之能够直接被执行。由于程序语言天然地倾向于消除歧义,这样的方法在某些特定领域有着很强的实用性。
我们也一直在探索一种实用性强、扩展性好的落地方案。面对实际业务问题,能够基于坚实的基础研发产品进行快速的行业适配,摆脱传统方法对数据标注的依赖。同时,又能无缝衔接先进通用模型带给我们的技术利好,有机地把行业内的专家知识与自然语言学界的前沿成果 结合起来。
基于 Go 语言的开源库FMR(Functional Meaning Representation)就是我们朝这个方向踏出的坚实一步。基于FMR框架,仅需要少量的工程师就能将有行业特殊性的语言逻辑快速转化为 FMR 框架可读的文法,快速满足行业定制化需求。 另外,FMR 相比于传统的框架,可解释性强,误差可控,在部署便利性和技术的延展性上,都有着独特的优越性。
FMR开源库地址链接
https://github .com/liuzl/fmr
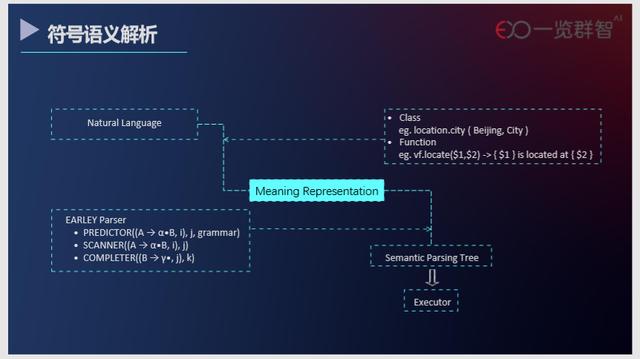
在传统自然语言的应用中,业界倾向于用一种 pipeline 的方式,包括分词、特征工程、建模等流程。这样的方式中的任何一个子流程的误差在整个过程中都会被传播甚至放大。
与传统流程不同的是,语义解析把自然语⾔的歧义性尽量当成特性⽽不是问题来进行处理,尽量保留所有符合语义的解析树,并 结合上下文语境进行歧义消解。例如,在 FMR 中,对语句词的切分是依据 UnicodeStandardAnnex#29,并在此基础上根据文法进⾏解析,这极大程度规避了分词模型误差在 pipeline 中逐级传播。
另外,对于大部分自然语言模型框架,外部依赖繁杂,在业务部署过程中非常繁琐。相比之下,基于 Go 语言的 FMR 在部署时能够被编译成一个可以直接执行的二进制文件,给部署带来了极大的便利。
语言的歧义性与其解析难度是正相关的。正如刚才所说,大部分编程语言在设计的时候就把“消除歧义”作为设计原则之一,因此,大部分程序语言的解析复杂度都是 O(n)的。对于自然语言,由于其内在的歧义性,所用到的解析算法的复杂度(例如 CKY 和 Earley)都是O(N^3) 的。与编程语言相似的是,在金融、公安、法律等领域,文书的文法和词法在一定程度上会刻意避免歧义,以求准确表达。这正好 大大降低了语言的歧义性,让语义解析在这些场景下能够发挥效用。
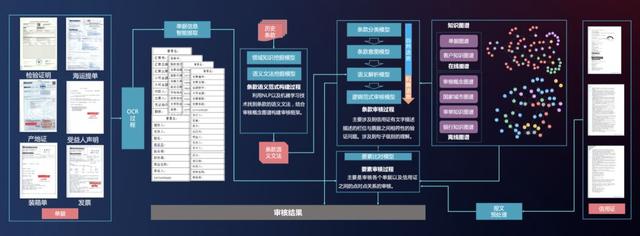
金融行业的票 据审核正是这样一个和语义解析耦合性很强的场景。在这个场景下,语言的歧义性一定程度上被人为的避免,降低了语义解析的难度。票 据中的语言表述精炼,几乎没有“上下文语境”,而这是大多深度学习模型所依赖的,所以这些屠榜的利器在这个场景下几乎没有用武之地。另外,金融行业对模型的可解释性和可控性要求极高,这也是语义解析能在这个行业落地的重要因素。在一览群智为金融行业打造的智能审单专家系统中,不论是对票 据信息的抽取还是对条款语义的理解,语义解析扮演着举足轻重的角色。这个审单系统已经在多个银行的票 据审核中投入使用,不仅给银行客户带来了业务效率的提升,也节省了银行大量的人力成本。
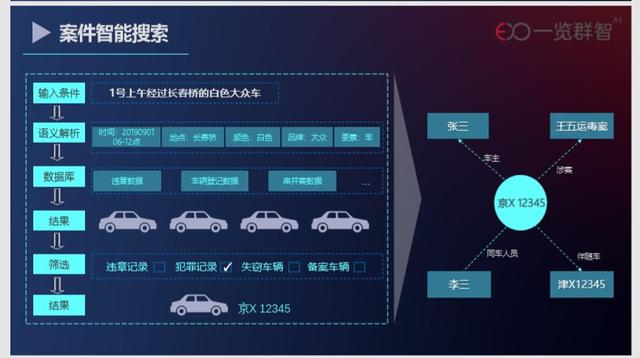
与金融行业类似,公安行业也存在着大量的零碎数据,分布在不同部门数据库中。以前,面对海量数据,很多业务需求,例如案件线索追踪和串并案发现,都极度依赖于专家的个人经验和大量人力比对。另外,由于公安行业的特殊性,其数据很难流通,这就给数据标注也带来了很大的困扰。针对公安行业的数据现状,我们研发了融合海量警情分析和案件关联分析的警情案情分析预警系统,在多地的公安系统中得到应用与好评。
正因为这些行业的文本数据分布与开放领域文本的分别存在偏移,导致很多通用的模型无法快速地适配到应用场景中。同时,这些模型算法中大多数依赖于短期内无法得到的大批量标注数据,面对没有标注数据的场景几乎无法冷启动。
著名学者杨乐村曾说过:如果把人工智能比作蛋糕,那监督学习和强化学习只是蛋糕上的点缀,只有非监督学习是蛋糕本体。在我们面临的大多数没有标注数据的场景中,也许语义解析就是那块蛋糕。自然语言处理和文本分析针对的场景往往是多个任务的集合,而语义解析与深度学习模型的综合使用,能够让自然语言处理和文本分析中的各项任务,按照最适合其特性的解决方法,得到综合的处理。
语义解析所依赖的所有语义解析语法是不是都需要人工编写呢?
在特定领域中,由于语法规则的制定带有很多人工的先验知识,需要人为的来制定。例如在数字解析中,“一打”的指的是“12”,这样的规则就是机器学不来的。但对于大部分语法规则来说,我们是可以通过统计和机器学习等数据驱动方法,从语⾔数据中学习,从而获得规律。在极端的数据驱动⽅方法中,甚至可以完全不使用⼈工手写语法,所有规则都是从数据中学习⽽而获得的。
语义解析是否就是正则表达式匹配或者槽位填充呢?⾃然语言具有语义组合性和递归性的特点,槽位填充实现了部分的组合性。而对于语义的递归性,不论是正则表达式匹配还是槽位填充都无法体现。
在标注数据充足的情况下,符号化语义解析是否仍有优势呢?基于神经网络的一些模型在很多特定的任务上取得了鼓舞人心的评测结果,但与语义解析框架不同的是,这些模型算法更像是太上老君的丹炉,模型的优劣是实验规律总结得到,很难得到理论上的解释性。正如张钹院士所说:“现在的人工智能没有自知之明”。
数据驱动的方法做出来的人工智能系统,是很危险的。即使对于SOTA模型,我们只知道在很大概率上,模型的结果是正确的,但我们无法确定很小概率的那部分在哪里。举例来说,对于一个简单的自然语言描述数字转换成阿拉伯数字问题,即使模型精度达到了99%,但在如票 据审核这样容错率极低的场景下,即使是1%的错误率,但模型无法确定性的直接给出到底是哪 1% 是错误的,这样也会带来无法接受的后果。
总而言之,我们当然对真正的强人工智能喜闻乐见,但受限于当前的技术发展,“全心全意”地相信深度学习模型并不是一种负责任的选择,更不用说在很多场景下,由于标注数据的匮乏,可选模型乏善可陈。相比之下,语义解析似乎是我们在这个阶段上的一个局部最优解。若干年后,假使真的出现对语言理解胜于人类的智能产物,人们也不会忘记语义解析在人工智能发展的长河中浓墨重彩的一笔。
作者介绍: 刘占亮 一览群智技术副总裁

2007年毕业于天津大学计算机系,曾先后供职于微软亚洲研究院互联网 搜索与挖掘组、腾讯 搜索、搜狗号码通和百度国际化,历任研究软件工程师、研究员、资深研究员/研发负责人、资深架构师/高级技术经理,负责基础研究、产品研发、研发管理、业务推广、商业变现等方面的工作。此外,他还曾作为产品技术负责人参与创办 Hitchsters .com(named one of Time Magazine’s 50 Best Websites for 2007)和 Initialview .com。