
11月4日和 5日, bigml 加入了哈马德·本·哈利法大学下属的卡塔尔计算研究所 (qcri), 将机器学习学校带到卡塔尔多哈!我们很高兴有这个机会与 qcri 合作。
会议期间, sanjay chawla 博士讨论了他的聚类算法与异常, k 手段-.我们认为这将是一个有趣的练习, 实现它的变化使用我们的领域特定的语言自动化机器学习工作流, whizzml。
k-手段算法的通常过程如下所示。它从一些数据集、一些群集 k 和一些预期的异常值l开始。它随机选择k质心, 并将数据集的每个点分配给其中一个质心。到目前为止, 就像香草 k 的意思。在香草 k 的意思, 你现在会发现每个集群的平均值, 并将其设置为新的质心。但是, 在 k-手段中, 您首先找到距离指定的质心最远的 l 点, 并从数据集中对其进行筛选。使用剩余的点找到新的质心。通过在我们离开的过程中删除这些点, 我们会发现质心不受异常值的影响, 从而发现不同的 (希望更好的) 质心。
我们已经在群集资源 bigml 中实现了 k 手段。但这不是香草 k 的意思。bigml 的实现不是通过平均群集中的所有点来找到新的质心, 而是通过采样点和使用梯度下降方法来更快地工作。bigml 还选择了比香草 k 手段更好的初始条件。我们将调整 chawla 的 k-means-, 以便在核心迭代中使用完整的 bigml 群集资源, 而不是失去这些好处。
这个 whizzml 脚本是我们实现的一部分。
(define (get-anomalies ds-id filtered-ds k l)
(let (cluster-id (create-and-wait-cluster {"k" k
"dataset" filtered-ds})
batchcentroid-id (create-and-wait-batchcentroid
{"cluster" cluster-id
"dataset" ds-id
"all_fields" true
"distance" true
"output_dataset" true})
batchcentroid (fetch batchcentroid-id)
centroid-ds (batchcentroid "output_dataset_resource")
sample-id (create-and-wait-sample centroid-ds)
field-id (((fetch centroid-ds) "objective_field") "id")
anomalies (fetch sample-id {"row_order_by" (str "-" field-id)
"mode" "linear"
"rows" l
"index" true}))
(delete* [batchcentroid-id sample-id])
{"cluster-id" cluster-id
"centroid-ds" centroid-ds
"instances" ((anomalies "sample") "rows")}))让我们逐行检查
cluster-id (create-and-wait-cluster {"k" k "dataset" filtered-ds})然后很容易创建一个与附加到质心的距离的输出数据集的批处理质心。
batchcentroid-id (create-and-wait-batchcentroid {"cluster" cluster-id
"dataset" ds-id
"all_fields" true
"distance" true
"output_dataset"
true})为了获得特定的点, 我们需要使用 bigml 示例资源来获取最遥远的点。
sample-id (create-and-wait-sample centroid-ds)现在, 我们可以找到与 l-实例关联的距离, 然后筛选出与原始数据集之间大于该距离的所有点。
anomalies (fetch sample-id {"row_order_by" (str "-" field-id)
"mode" "linear"
"rows" l
"index" true}))我们重复此过程, 直到质心稳定, 通过在算法的后续迭代中, 在异常值集之间传递 jacard 系数的阈值来确定, 或者直到我们达到用户设置的一些最大迭代数。
您可以在github或 bigml 库中找到完整的代码。
那么, 当我们运行此脚本时, 会发生什么呢?让我们试试红酒质量数据集。以下是使用 k 13 (使用 bigml g 均值群集选择) 和 l 为10时的结果。
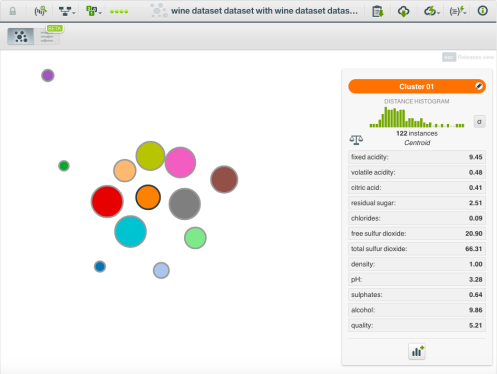
我们可以导出群集摘要报告, 并将其与具有相同k的香草 bigml 群集进行比较。正如您通过移除外围点所预期的, k 均值的质心标准偏差的平均值较小, 因为 k 均值减去两个结果: 0.00128 对0.00152。
我们作为异常值删除的点呢?我们知道它们是否真的是不正常的吗?当我们通过 bigml 异常检测器运行葡萄酒数据集时, 我们可以根据隔离林获得前10个异常。与脚本找到的十个异常值相比, 我们看到有六个常见的实例。这是一个体面的协议, 我们已经删除了真正的异常值。
我们希望您喜欢此演示 bigml 如何可以与研究合作, 轻松地定制 ml 算法。