
哦, 不, 更多的数据!
上个月, 我们采用了长时间运行的熊猫分类器, 利用沃拉鲁的并行化功能使其运行速度更快。这一次, 我们想把它踢到一个缺口, 看看我们是否可以继续扩大, 以满足更高的需求。我们还希望尽可能节约成本: 根据需要提供基础结构, 并在完成处理后对其进行预配置。
如果你不想阅读上面链接的帖子, 这里有一个简短的情况总结: 每个小时都有一份你正在运行的批处理作业。此作业接收 CSV 文件, 并使用基于熊猫的算法对文件的每一行进行分类。作业的运行时开始接近一小时标记, 并且担心当输入数据超过特定点时, 管道将断开。
在博客文章中, 我们展示了如何将输入数据分割成较小的数据框, 并在一个特殊的沃拉鲁集群中的工作人员之间分发它们, 在一个物理机器上运行。以这种方式并行工作会给我们很多时间, 并且批处理作业可以继续处理不断增加的数据量。
当然, 我们可以在合理的时间内处理100万行, 但如果数据集按数量级增长, 该怎么办?通过在本地沃拉鲁群集上运行我们的分类器, 我们能够将100万行的处理时间缩短到16分钟, 从而在分配的时间间隔内安装一个小时。但是, 如果输入数据, 比方说, 10x 更多, 我们将有一个困难的时间处理它在本地。
让我们看看如何通过按需启动基于云的沃拉鲁群集、运行作业、收集数据和关闭群集, 以完全自动化的方式来跟踪数据增长。
贸易工具
沃拉鲁的一个重要想法是, 您的应用程序不必知道它是否在一个进程、多个本地进程或包含许多物理计算机的分布式系统上运行。从这个意义上讲, 从以前的博客文章 “迁移” 我们的分类器应用程序没有额外的工作。
我们将需要一些工具来帮助我们在云中设置和管理集群。沃拉鲁可以使用许多不同的工具。我们在 Pulumi 的朋友提供了一个出色的工具, 可消除供应基础设施中涉及的头疼。在本例中, 我们将使用 Pulumi 定义、设置和最终拆除处理群集。
我们还需要Ansible来启动、停止和检查集群的状态, 最后但并非最不重要的是, 我们需要一个AWS账户, 我们的机器将在那里生存。
让我们跳进它!
示例运行
首先, 如果你想跟随 (并花一些钱调配 EC2 服务器), 请下载并设置 Pulumi。
接下来,克隆沃拉鲁博客示例存储库并导航到 provisioned-classifier 。如果你跟着以前的熊猫博客文章, 你会发现我们的旧应用程序嵌套在这里, 下 classifier 。更有趣的是两个新目录: pulumi 和 ansible 。
在不深入了解详细信息的情况下, 让我们看看如何在 EC2 云中的新配置的群集上运行我们的应用程序:
make up run-cluster get-results down INPUT_LINES=1000000 CLUSTER_SIZE=3让我们打破这一点, 看看这里到底发生了什么。
1) 将 make up CLUSTER_SIZE=3 群集配置为由3台计算机和代表组成, 以进行 pulumi up 基础结构的实际业务。我们的物理群集将包含3个用于处理的节点, 以及一个额外的 metrics_host 节点, 用于承载我们的指标 UI和收集结果。
2) 一旦预配完成, 下一个任务, run-cluster INPUT_LINES=1000000 使用我们的 Ansible 行动手册将应用程序代码上载 classifier/* 到上面设置的所有三台计算机, 然后启动一个沃拉鲁群集, 每个计算机有7个工作进程。
接下来, Ansible 开始发送100万行我们的合成 CSV 数据, 并等待100万行到达该 data_receiver 过程。当这些行到达时, 它们将被压缩, 并且群集被关闭。
3) 将 make get-results 压缩结果文件拉到 output/results.tgz ,
4) 最后, make down 销毁用于为我们的计算供电的云基础结构。
Pulumi 群集定义
让我们来看看我们的基础架构是如何定义的。这是定义的核心:
function instance(name) {
return new aws.ec2.Instance(
name,
{associatePublicIpAddress: true,
instanceType: instanceType,
securityGroups: [secGrp.name],
ami: ami,
tags: {"Name": name},
keyName: keyPair.keyName})
}
let metrics_host = instance("classifier-metrics_host");
let initializer = instance("classifier-initializer");
let workers = [];
for(var i=0; i<clusterSize-1; i++){
workers.push(instance("classifier-"+(i+1).toString()));
}正如您从上面所看到的, 我们的小 instance() 功能封装了我们想要提供的每台机器的通用设置。
and metrics_host initializer 是 ec2.Instance 具有描述性名称的对象, 而 workers s 则 ec2.Instance 仅由其序号区分。Pulumi 允许我们在代码中定义安全组、SSH keypairs, 以及云基础架构的几乎所有其他方面的内容。
此功能的一个示例是 keyPair 用于通过 SSH 访问实例的对象。我们的生成文件可确保为群集实时生成 ssh 密钥, Pulumi 知道如何使用它为新设置的节点设置 ssh 访问:
let pubKey = fs.readFileSync("../ssh_pubkey_in_ec2_format.pub").toString();
let keyPair = new aws.ec2.KeyPair("ClassifierKey", {publicKey: pubKey});随着我们所定义的计算基础设施的相关位, 我们可以告诉 Pulumi 在现实世界中采取行动, 使其符合我们的定义:
当我们运行时 make up CLUSTER_SIZE=3 , 我们将看到 Pulumi 输出类似于以下内容:
Performing changes:
+ pulumi:pulumi:Stack classifier-classifier-demo creating
+ aws:ec2:KeyPair ClassifierKey creating
(...)
+ aws:ec2:Instance classifier-2 created
---outputs:---
metrics_host: [
[0]: {
name : "classifier-metrics_host"
private_ip: "17247.236 “public_dns:” ec2-54-245-53-87. 美国-西-2. 计算. amazonaws. com “} (…)
] 信息: 7 执行的更改: + 7 资源创建更新持续时间: 1m59.524017637s
我们可以使用 Pulumi 的输出来缝合 Ansible 库存, 这将让我们以编程方式与我们的预配置实例进行交互。
如果要修改群集, 可以编辑 pulumi/index.js , 然后重新运行 make up CLUSTER_SIZE=N 。如果更改不需要重新启动实例 (例如, 它们只关注安全组), Pulumi 将做正确的事情, 而不会干扰基础结构的其余部分。
如果您深入检查 Pulumi 定义文件, 您将看到它依赖于一个神秘的 AMI: ami-058d2ca16567a23f7 。这是一个基于 Ubuntu 的实验图像, 沃拉鲁二进制文件 ( machida 、, cluster_shutdown cluster_shrinker 和 data_receiver ) 预加载。目前, 它只存在于 us-west-2 AWS 区域, 但我们希望使沃拉鲁 ami 可在所有区域进行试验, 从下一个沃拉鲁版本开始。
运行计算
现在我们已经知道了什么是魔力, 我们的 AWS 基础架构, 让我们来看看如何使用它来运行我们的任务。从根本上讲, 我们集群的组件可以描述如下:
-
数据源-在我们的情况下, 它是文件发送. py, 它可以生成和传输随机生成的 CSV 数据, 以供我们的计算使用。
-
町田过程: 一个初始值设定项和一堆工人。两者之间的区别仅在群集启动时才有意义。
-
数据接收器-在 TCP 端口上侦听计算输出的进程。这是
data_receiver作为沃拉鲁安装的一部分提供的。 -
指标 UI –我们的灵药供电的实时仪表板。
我们的 Ansible 手册负责协调各种组件的启动, 确保其输入、输出和控制端口匹配。特别是, 群集初始值设定项开始了解群集中的工作人员总数, 并且每个其他工作人员都连接到初始值设定项的内部 IP 和控制端口。如果您对集群的详细讨论感兴趣,请参阅此处。
这就是我们启动 Ansible 行动手册时在服务器上运行的最终结果:
群集启动并运行后, 初始值设定项节点的TCP 源正在侦听连接时, 我们启动 sender 并指示它向 TCP 源发送数据流。在现实的批处理方案中, 此发件人可以作为从远程文件系统或 S3 读取特定文件的连接器实现。为了我们的目的, 我们将通过按需生成一组 CSV 行, 然后关闭, 来模拟这一点。
在执行该工作时, 我们可以查看在屏幕上打印的指标 URL, 以了解如何分发工作美国-西-2. 计算. amazonaws: 4000
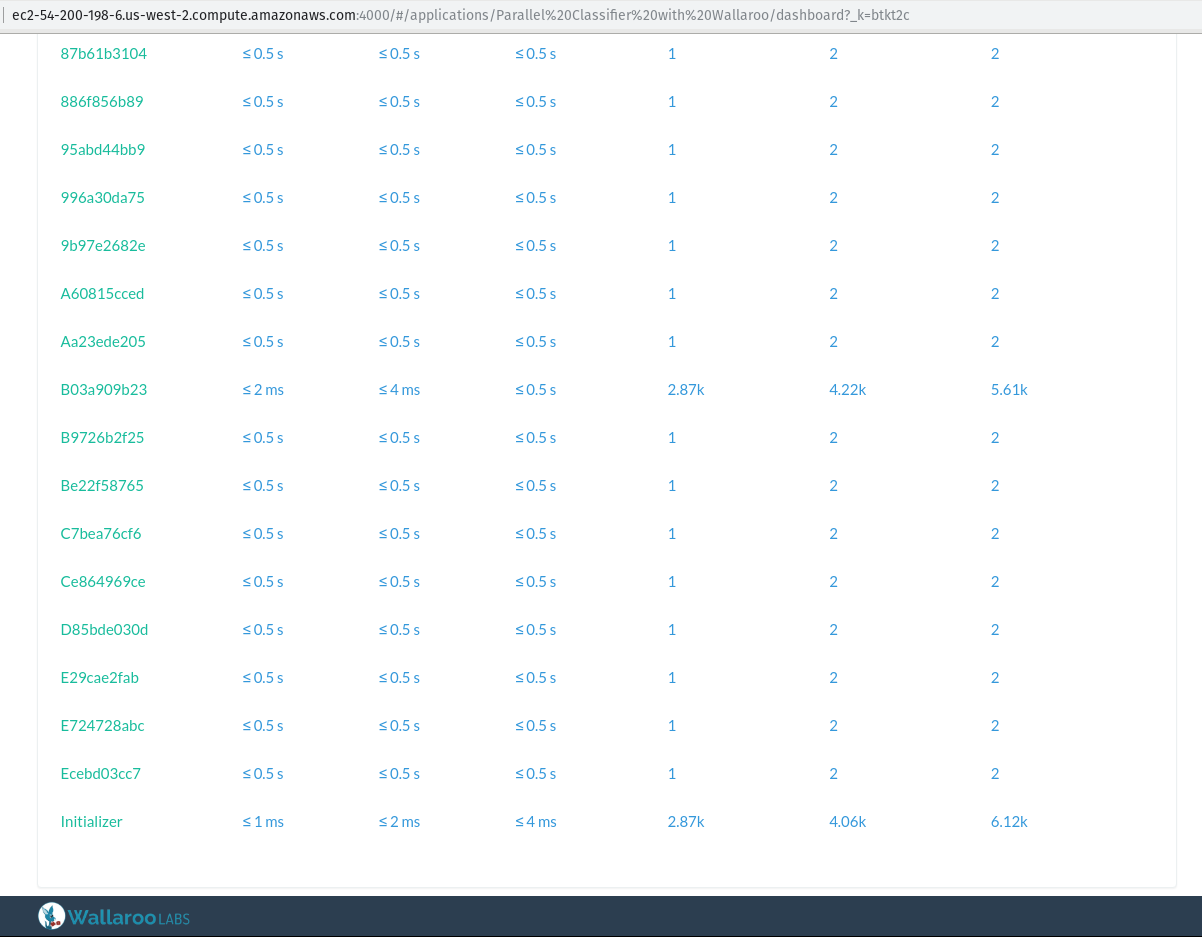
在上面的屏幕截图中, 您可以看到 Initializer 和 B03a909b23 节点每秒处理大约4k 消息, 并且所有其他工作人员都将分类工作均匀地划分在其中。不要惊讶, 两个工人正在处理数量级更多的消息!还记得我们的熊猫应用管道吗?
ab.new_pipeline("Classifier",
wallaroo.TCPSourceConfig(in_host, in_port, decode))
ab.to_stateful(batch_rows, RowBuffer, "CSV rows + global header state")
ab.to_parallel(classify)
ab.to_sink(wallaroo.TCPSinkConfig(out_host, out_port, encode))
return ab.build()CSV 行是一对一的, 但我们批处理它们并将它们转换为数据框 100, 这样我们的分类算法一次可以处理多个行。工人恰好 B03a909b23 是我们的状态命名为 “CSV 行 + 全局标头状态” 的工作人员。让我们来看看它的指标:
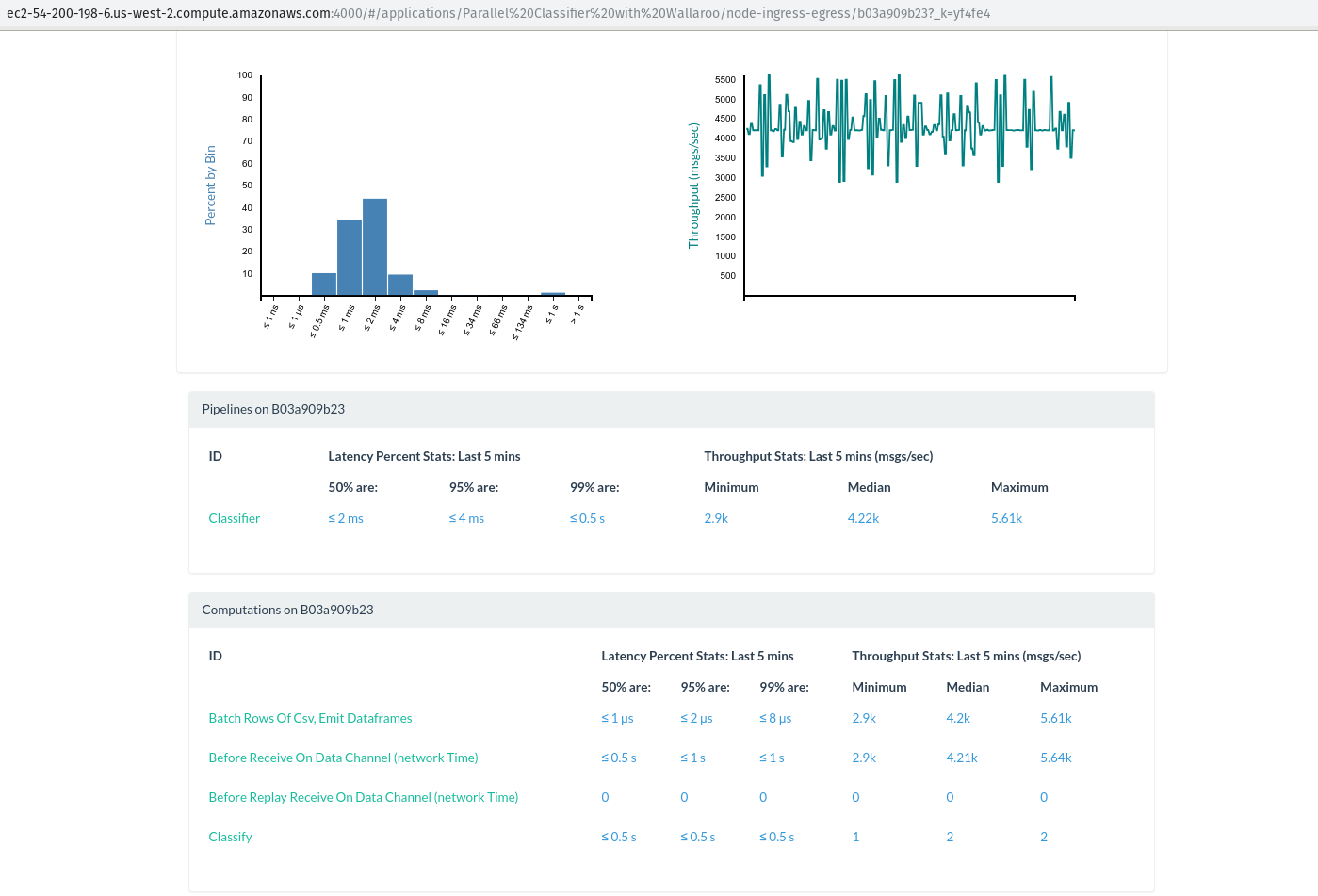
事实上, 我们可以看到, 此工作人员正在处理大约4米/秒消息在 “批处理行 CSV, 发出数据框” 步骤。其他的工人都忙着分类!让我们看看不同的随机工作人员的细分:
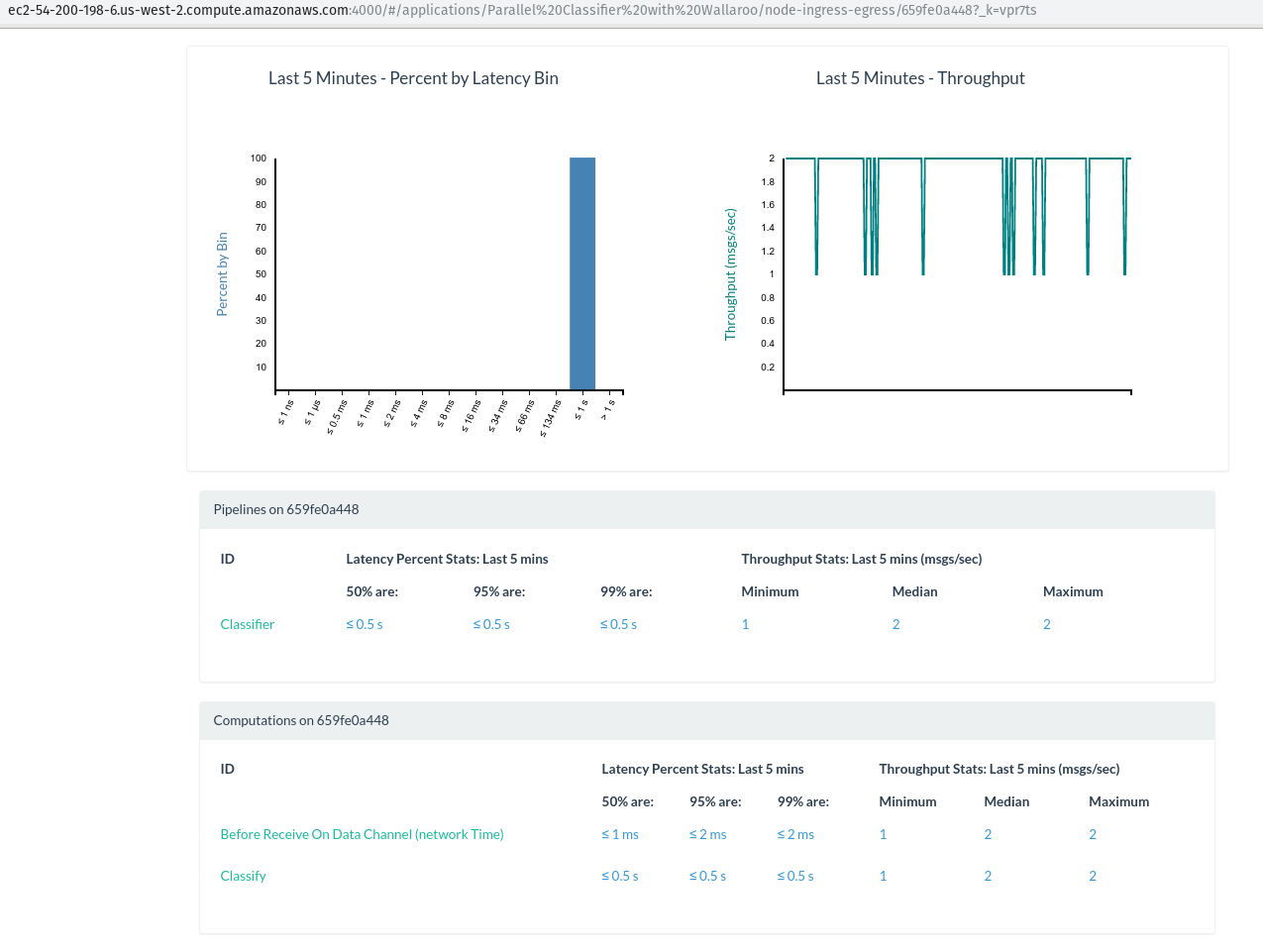
看起来不错剩下的我们要做的就是等到作业完成后, 我们收到我们的磁盘上的压缩数据。
数字!
作为提醒, 让我们看看我们通过在 AWS 中的单个实例上运行我们的分类器获得的数字 c5.4xlarge :
单马海因运行时间 (无预配)
| CSV 行 | 1 工人 | 4 名工人 | 8 名工人 |
|---|---|---|---|
| 10 000 | 39s | 405 | 11s |
| 100 000 | 6m28s | 3m16s | 1m41s |
| 1 000 000 | 1h03m46s | 32m12s | 16m33s |
现在, 让我们看看通过我们的按需预配置基础架构扩展, 我们可以实现多大的加速。
多机运行时间 (预配 + 计算)
| CSV 行 | 4 台/ 28名工人 |
8 台机器/ 56名工人 |
16 台机器/ 112名工人 |
|---|---|---|---|
| 10 000 | 2m13s | 2m36s | 2m43s |
| 100 000 | 3m38s | 3m42s | 3m48s |
| 1 000 000 | 7m38s | 6m41s | 5m56s |
| 10 000 000 | 40m56s | 33m10s | 23m24s |
| 30 000 000 | > 2h | 1h45m | 1h12m |
尽管在旋转所需的基础结构方面存在一些持续的开销 (显然太多的开销足以证明为不到100万行的群集旋转), 但我们现在能够在半小时内对1000万行 CSV 数据进行分类, 再过一小时就3000万点。这为我们提供了一些关于何时我们的应用程序需要额外的资源, 或者可能一些性能优化的观点
结论
上面的数据说明了如何使用沃拉鲁作为临时计算云, 使用 Pulumi 和 Ansible 来调配、远程运行工作负载, 并在结果完成后关闭基础结构。
在案例或我们的批处理作业中, 我们可以利用此模式按需水平缩放, 即使传入的工作负载超过一台物理机的容量, 同时运行与本地运行的完全相同的沃拉鲁应用程序, 作为常规发展。沃拉鲁处理我们程序的规模感知层, 因此我们可以专注于业务逻辑和数据流。