

你可以在这里阅读第1部分。
介绍
在这篇文章中,我将改进上一篇文章中分享的示例。我们还将尝试看到 Flink 的翻滚时间窗口的一些细节。
您可能还喜欢:
带 SnappyData 的实时流式处理 ETL
翻滚窗口
我在上一篇文章中使用的例子使用了翻滚的窗口。这是一种直观的入门方法,它收集给定窗口中的所有数据,并确保数据不会重叠。
根据 Flink 文档,”翻转窗口具有固定大小且不重叠。例如,如果指定大小为 5 分钟的翻滚窗口,将计算当前窗口,并且每五分钟启动一个新窗口。
从上一篇文章中使用的示例开始,我更新了类 IntegerSum ,以使用 10 秒的 TumblingWindow 间隔,添加了很少的日志语句来打印当前本地时间,以知道 何时 ctx.collect() 调用 和 apply() addSink() 。在 apply() 方法中,我使用 AllWindowFunction ,根据 Flink 文档,一旦收集了此时间窗口的所有数据,就会调用它。最后,我编辑了变量“sleepTimer”,以便每秒仅生成 2 个整数 IntegerSourceFunction 。
注意:此处使用的所有示例都位于GitHub上,因此仅显示重要的代码块。
下图显示了带有日志语句的日食控制台输出。
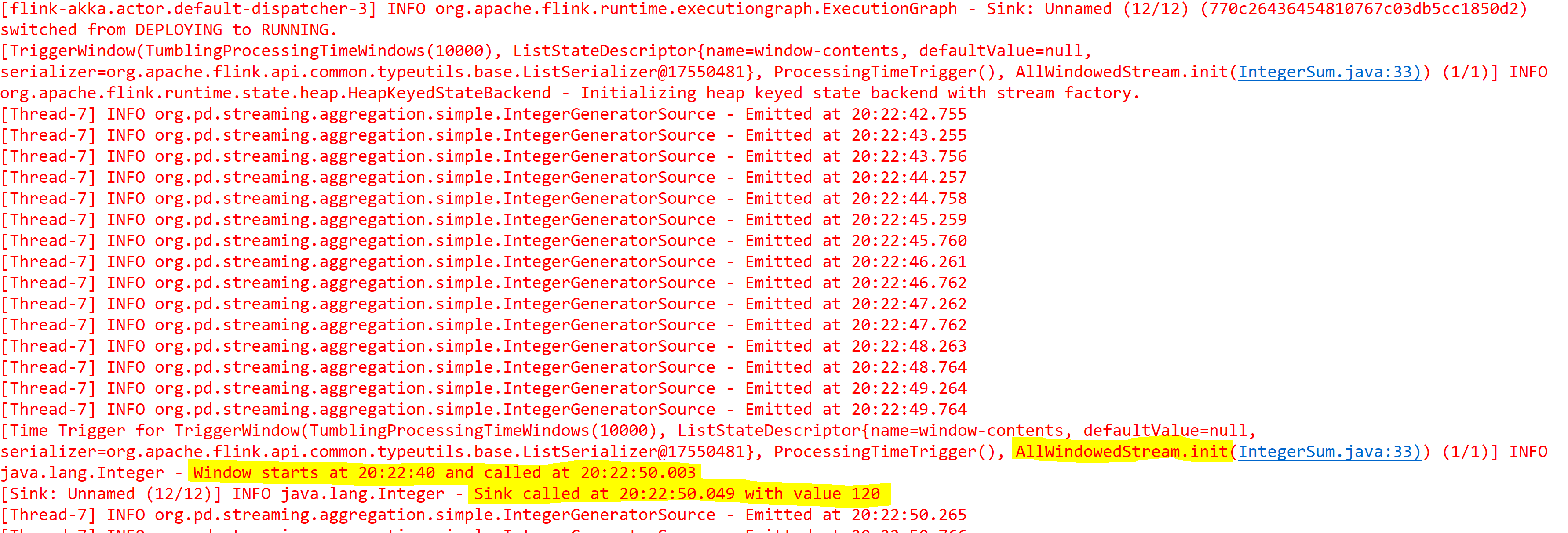
从上述输出中需要注意的要点:
- 翻滚窗口开始于 20:22:40
- ctx.collect() 语句被执行(”在 xx:yy:zz 发出”)
- 这些值由内存中的 Flink 缓冲
- 翻转窗口触发和 apply() 方法在 20:22:50.003 调用(10 秒后,如预期)
- 最后,在 20:22:50:049 应用() 之后,几乎立即调用 addSink() 与聚合结果
增量计算
在许多情况下,在内存中保存窗口的所有数据不是个好主意。Flink 通过名为 的方便的接口提供了一种增量计算方式 ReduceFunction ,该接口可用于代替 AllWindowFunction 。我们可以使用“减少函数“方法,而不是将apply()方法与AllWindow 函数一起使用。
根据 Flink Java 文档,
减少方法= “…此窗口将尝试并在窗口策略允许的情况下以增量方式聚合数据。例如,翻滚时间窗口可以聚合数据,这意味着每个键只存储一个元素”
减少功能接口= “…将元素组组合到单个值,将始终将两个元素合并为一个元素”
很公平,让我们试试这个减少(新的缩减函数_lt;整数>()
{
专用静态最终长串行版本UID = -6449994291304410741L;
@Override
公共整数缩减(整数值1,整数值2)引发异常
{
logger.info(”在值 1 = 和值 2 {}处减少调用”,LocalTime.now(),值1,值2;
返回值1 = 值2;
}
})
逻辑仍然相同(整数之和),但好的一部分是,现在 Flink 可以增量计算,不需要先缓冲所有数据。
下图显示了日食控制台的输出
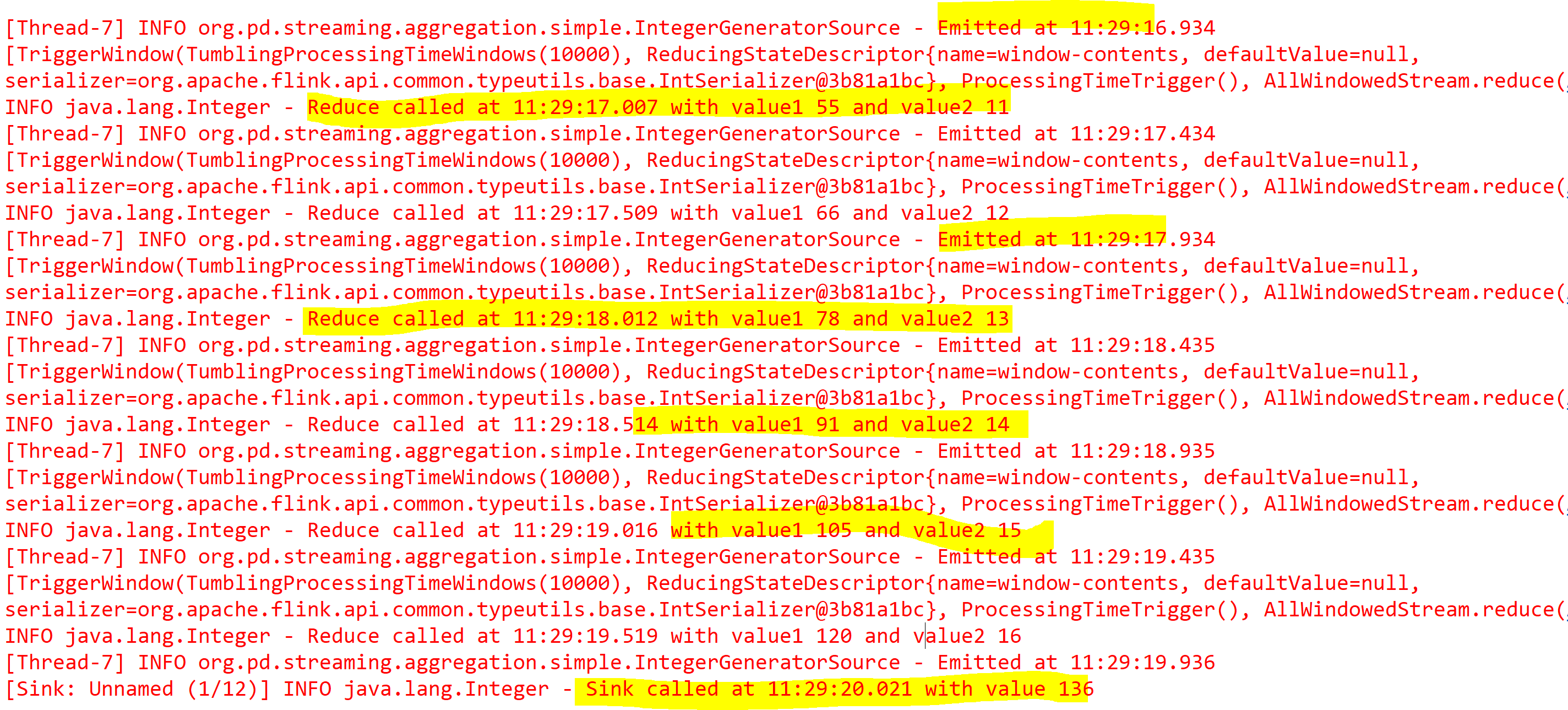
因此,在传递给 之后 ctx.collect() ,Flink 调用 reduce 方法,其中第一个参数表示上一个窗口的计算,第二个参数表示流中的当前值。最后,使用最终结果调用接收器。
注意:正如预期的那样,两种方法对翻滚窗口将使用相同的时间(10 秒后将调用接收器)。计算是增量的,与应用(AllWindowFunction)相比,有限的数据存储在缓冲区中。
键控数据
现在稍加步,在许多实际用例中,使用某种键将数据划分为多个数据流。此模式不仅有助于加快计算速度,而且会根据其属性分布数据。正如预期的那样,Flink 支持键控数据流,并且非常容易启动。
假设我们每个整数流都有一个键(或任何 id),现在想要计算每个键的总和。对于此示例,我使用的是 IntegerSourceWithKey 同时发出键和整数的新类。我们可以发送此键和值作为 Flink TupleXX 类,其中 XX 是 2 和 25 之间的任意数字 (Tuple2, 元组 3 …或元数25),或者我们可以使用POJO和getter方法告诉Flink在哪里查找密钥。
首先,让我们看一个使用 TupleXX 的示例。
下面是 IntegerGeneratorSourceWithKey::run() 实现 SourceFunction> 的 。此外,定义的 3 个 id,它将与生成的每个整数一起以循环方式使用。发送到流的每个记录都是 的实例 Tuple2 ,id 是第一个成员,数据是第二个成员。
private String[] id = new String[] {"id-1", "id-2", "id-3"};
@Override
public void run( SourceContext<Tuple2<String, Integer>> ctx ) throws Exception
{
int counter = 1;
while( isRunning )
{
Thread.sleep( sleepTimer );
// generate integers with an id
ctx.collect( new Tuple2<String, Integer>(id[counter%3],counter++));
}
}IntegerSumWithKey是从 生成的整数计算总和的类 IntegerGeneratorSourceWithKey 。
public class IntegerSumWithKey
{
private StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
private IntegerGeneratorSourceWithKey source = new IntegerGeneratorSourceWithKey(500);
public void init() throws Exception
{
// add a simple integer generator as source
DataStream<Tuple2<String, Integer>> dataStream = senv.addSource(source);
// build the pipeline using tumbling window size of 10 seconds
dataStream
.keyBy(0)
.timeWindowAll(Time.seconds(10))
.sum(1)
.print();
senv.execute(this.getClass().getSimpleName());
}
}注意:reduce()此类中没有 、 apply() 或 addSink() 方法
在这里, keyBy(0) 将让数据流知道它将在分区数据的第一个索引处找到一个键。时间窗口设置为 10 秒,之后它将 sum(1) 显示的数据索引 1 中的值,最后 print() 为粗放。
在后台, sum() 实际上是一个预定义的reduce()方法,使用 Flink 提供的聚合器和 print() 使用 Flink 的 PrintSink 函数类的预定义addSink()方法。
下面的示例使用 Java POJO 而不是 Flink Tuple 来实现相同的结果。
public class IntegerSumWithKeyFromPojo
{
private StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
public void init() throws Exception
{
// add a source using simple POJO
DataStream<MyData> dataStream =
senv.addSource(new SourceFunction<MyData>()
{
private static final long serialVersionUID = -1356281802334002703L;
private String[] id = new String[] {"id-1", "id-2", "id-3"};
@Override
public void run(SourceContext<MyData> ctx) throws Exception {
int counter = 1;
while(true) {
Thread.sleep( 500 );
ctx.collect(new MyData(id[counter%3], counter++));
}
}
@Override
public void cancel() {
// production code must handle cancellation properly.
}
});
// build the pipeline using tumbling window size of 10 seconds
dataStream
.keyBy((KeySelector<MyData, String>) MyData::getId)
.timeWindowAll(Time.seconds(10))
.sum("value")
.print();
senv.execute(this.getClass().getSimpleName());
}
}结论
我相信我们现在有好的例子开始与Flink。在接下来的几篇博文中,我将采用一个实际用例,并引导您完成各种步骤来分析流数据。




