
HBase 是一个面向列的数据存储,位于 Hadoop 分布式文件系统的顶部,为大数据顾问提供随机数据查找和更新。Hadoop 分布式文件系统基于”写入一次读取多”体系结构,这意味着一旦写入 HDFS 存储层的文件无法修改,但只能读取任何次。但是,HBase 在 HDFS 文件上提供了一个架构,用于访问和更新这些文件的任何次。
基地特征
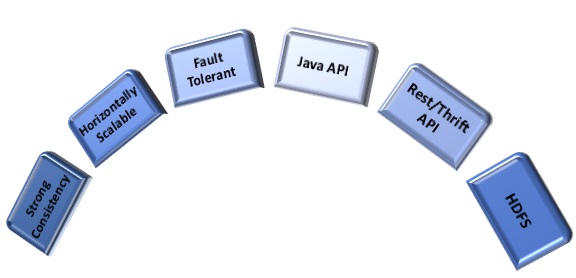
强一致性
HBase 为读/写提供了很强的一致性,这意味着您将始终在读取操作中获取最新数据,并且除非所有副本都已更新,否则不会完成写入操作。
水平可扩展
HBase 使用分布在群集上的区域概念提供自动分片。每当表大小变得太大而无法容纳数据时,它都会自动分片并分布在多台计算机上。
故障容错
HBase 在发生故障时提供自动区域故障转移。
HDFS/地图减少集成
HBase 基于 HDFS 的顶部,可以与 MapReduce 程序集成,以充当源和接收器。
Java API/Rest/Thrift API
HBase 为非 java 终结点提供 Java API 以及休息/节俭 API
查询优化
HBase 具有内置块缓存和绽放筛选器,用于查询优化。
何时不使用 HBase?
- 数据不够大时。HBase 适用于可以在传统 RDBMS 数据库中容纳的数十亿行表示的数据。
- 当数据以恒定速度出现,并且预计将来不会增长时。
- 当您不关心事务控件、触发器、辅助索引以及传统数据库支持的许多其他功能时。
基地架构
HBase 具有主从体系结构,其中我们有一个 HBase 主服务器(也称为 HMaster)和多个从属服务器,称为区域服务器或 HRegion 服务器。
地区:HBase 中的表在多个区域上拆分,这些区域分布在群集中的多台计算机上。
哈基地主机:HBase 负责将区域分配给区域服务器、提供管理控制台(创建、更新和删除表)并控制故障。在读取请求的情况下,HMaster 会接收客户端请求,然后转发到相应的区域服务器。
区域服务器从属服务器:区域服务器在所有辅助节点上运行,并服务于一组区域。区域服务器由块缓存组成,这些缓存可保存频繁访问数据,以便更高效地提供读取请求数据写入区域服务器磁盘上的多个 Hfile。
动物园管理员:HBase 使用动物园管理员进行协调和故障恢复。动物园管理员保存有关 HBase 主服务器和区域服务器的配置信息。客户端必须首先访问动物园管理员才能与 HBase 群集连接。ZKquoram 是一个动物园管理员守护程序,用于监视故障和修复故障节点。因此,ZooKeeper 是 HBase 体系结构中不可或缺的一部分,它维护了 HBase 群集中的所有协调和同步。
基地数据模型
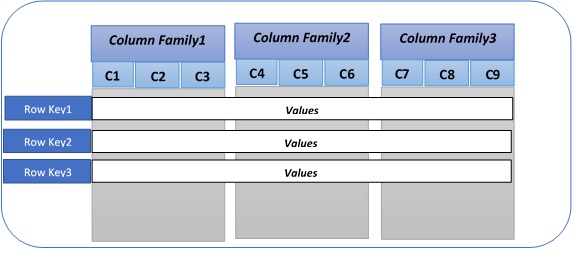
HBase 表:它是行的集合,这些表分布在分布式区域。
HBase 行:它表示 HBase 表中的单个实体。
行键:它就像一个主键,用于唯一标识 HBase 表中的每一行。
列:列表示实体的属性。例如,在客户 HBase 表中,列可以是客户姓名、年龄、电话号等。
列系列:所有显示某些相同品质的列都可以在同一列系列中拼凑在一起,这些列作为 Hfile 存储在 Hadoop 分布式文件系统上。
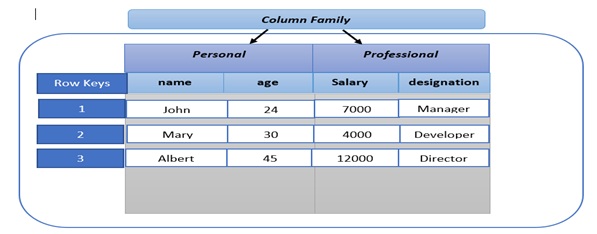
开始使用 HBase
我们将创建下表,使用 HBase shell 命令创建以下表,然后使用 Java API。员工表有两个列系列,即个人列系列,它表示个人信息,如姓名、年龄和专业列系列,代表工资和指定等专业信息。
HBase 外壳命令


